用户指南(Apache NiFi User Guide)
编辑人(全网同名):酷酷的诚 邮箱:zhangchengk@foxmail.com
介绍
Apache NiFi是基于流程编程概念的数据流系统。它支持强大的可扩展的且包含了数据路由,转换和系统中介逻辑的有向图。NiFi具有基于Web的用户界面,用于设计,控制,反馈和监控数据流。它在服务质量的几个方面具有高度可配置性,例如容错与保证交付,低延迟与高吞吐量以及基于优先级算法的排队。NiFi为所有received, forked, joined cloned, modified, sent,dropped的数据提供细粒度的数据来源。
有关系统要求,安装和配置的信息,请参阅系统管理员指南。安装NiFi后,使用支持的Web浏览器查看UI。
浏览器支持
| 浏览器 | 版本 |
|---|---|
| Chrome | Current and Current - 1 |
| FireFox | Current and Current - 1 |
| Edge | Current and Current - 1 |
| Safari | Current and Current - 1 |
Current和Current - 1表示该浏览器的当前稳定版本和前一个版本支持NIFI UI。例如,如果当前的稳定版本是45.X,那么官方支持的版本将是45.X和44.X.
对于不太频繁发布主要版本的Safari,Current和Current - 1只代表两个最新版本。
不支持的浏览器
虽然UI可能在不受支持的浏览器中成功运行,但没有针对它们进行主动测试。此外,UI被设计为桌面体验,目前在移动浏览器中不受支持。
在可变大小的浏览器中查看UI
在大多数环境中,所有UI在浏览器中都可见。此外,UI具有响应式设计,允许您根据需要在较小尺寸的浏览器或平板电脑环境中滚动屏幕。
在浏览器宽度小于800像素且高度小于600像素的环境中,部分UI可能不可用。
术语
DataFlow Manager:DataFlow Manager(DFM)是NiFi用户,具有添加,删除和修改NiFi数据流组件的权限。
FlowFile:FlowFile代表NiFi中的单个数据。FlowFile由两个组件组成:FlowFile属性(attribute)和FlowFile内容(content)。内容是FlowFile表示的数据。属性是提供有关数据的信息或上下文的特征,它们由键值对组成。所有FlowFiles都具有以下标准属性:
uuid:一个通用唯一标识符,用于区分FlowFile与系统中的其他FlowFiles。
filename:在将数据存储到磁盘或外部服务时可以使用的可读文件名
path:在将数据存储到磁盘或外部服务时可以使用的分层结构值,以便数据不存储在单个目录中
Processor:处理器是NiFi组件,用于监听传入数据、从外部来源提取数据、将数据发布到外部来源、路由,转换或提取FlowFiles。
Relationship:每个处理器都为其定义了零个或多个关系。命名这些关系以指示处理FlowFile的结果含义。处理器处理完FlowFile后,它会将FlowFile路由(传输)到其中一个关系。DFM能够将每一个关系连接到其他组件,以指定FlowFile应该在哪里进行下一步处理。
Connection:DFM通过将组件从NiFi工具栏的Components部分拖动到画布,然后通过Connections将组件连接在一起来创建自动的数据处理流程。每个连接由一个或多个关系组成。对于每个Connection,DFM都可以为其确定使用哪些关系。这样我们可以基于其处理结果的不同来以不同的方式路由数据。每个连接都包含一个FlowFile队列。将FlowFile传输到特定关系时,会将其添加到属于当前Connection的队列中。
Controller Service:控制器服务是扩展点,在用户界面中由DFM添加和配置后,将在NiFi启动时启动,并提供给其他组件(如处理器或其他控制器服务)需要的信息。常见Controller Service比如StandardSSLContextService,它提供了一次配置密钥库和/或信任库属性的能力,并在整个应用程序中重用该配置。我们的想法是,控制器服务不是在每个可能需要它的处理器中配置这些信息,而是根据需要为任何处理器提供。
Reporting Task:报告任务在后台运行,以提供有关NiFi实例中发生情况的统计报告。DFM根据需要在用户界面中添加和配置报告任务。常见的报告任务包括ControllerStatusReportingTask,MonitorDiskUsage,MonitorMemory和StandardGangliaReporter。
Funnel:漏斗是一个NiFi组件,用于将来自多个Connections的数据合并到一个Connection中。
Process Group:当数据流变得复杂时,在更高,更抽象的层面上推断数据流是很有用的。NiFi允许将多个组件(如处理器)组合到一个过程组中。然后,DFM可以在NiFi用户界面轻松地将多个流程组连接到逻辑数据处理流程中,DFM还可以进入流程组查看和操作流程组中的组件。
Port:使用一个或多个进程组构建的数据流需要一种方法将进程组连接到其他数据流组件。这是通过使用Ports实现的。DFM可以向进程组添加任意数量的输入端口和输出端口,并相应地命名这些端口。
Remote Process Group:正如数据传输进出进程组一样,有时需要将数据从一个NiFi实例传输到另一个NIFI实例。虽然NiFi提供了许多不同的机制来将数据从一个系统传输到另一个系统,但是如果将数据传输到另一个NiFi实例,远程进程组通常是实现此目的的最简单方法。
Bulletin:NiFi用户界面提供了大量有关应用程序当前状态的监视和反馈。除了滚动统计信息和为每个组件提供的当前状态之外,组件还能够报告公告。每当组件报告公告时,该组件上都会显示公告图标(处理器右上角红色的图标)。系统级公告显示在页面顶部附近的状态栏上。使用鼠标悬停在该图标上将提供一个工具提示,显示公告的时间和严重性(Debug, Info, Warning, Error)以及公告的消息。也可以在全局菜单中的公告板页面中查看和过滤所有组件的公告。
Template:通常,DataFlow由许多可以重用的组件组成。NiFi允许DFM选择DataFlow的一部分(或整个DataFlow)并创建模板。此模板具有名称,然后可以像其他组件一样拖动到画布上。最终,可以将若干组件组合在一起以形成更大的构建块,然后从该构建块创建数据流处理流程。这些模板也可以导出为XML并导入到另一个NiFi实例中,从而可以共享这些构建块。
flow.xml.gz:DFM放入NiFi用户界面画布的所有内容都实时写入一个名为flow.xml.gz的文件。该文件默认位于conf目录中。在画布上进行的任何更改都会自动保存到此文件中,而无需用户单击保存按钮。此外,NiFi在更新时会自动在归档目录中创建此文件的备份副本。您可以使用这些归档文件来回滚配置,如果想要回滚,先停止NiFi,将flow.xml.gz替换为所需的备份副本,然后重新启动NiFi。在集群环境中,停止整个NiFi集群,替换其中一个节点的flow.xml.gz,删除自其他节点的flow.xml.gz,然后重新启动该节点。确认此节点启动为单节点集群后,然后启动其他节点。替换的流配置将在集群中同步。flow.xml.gz的名称和位置以及自动存档行为是可配置的。有关更多详细信息,请参阅系统管理员指南。
NiFi用户界面
NiFi UI提供了创建自动DataFlow以及可视化,编辑,监视和管理这些DataFlow的机制。UI可以分为几个部分,每个部分负责不同的功能。本节提供应用程序的屏幕截图,并突出显示UI的不同部分。每个部分将在本文档后面进一步详细讨论。
启动应用程序后,用户可以访问http://hostname:8080/nifi 看到NIFI的UI 。默认情况下没有配置权限,因此任何人都可以查看和修改数据流。有关保护系统的信息,请参阅系统管理员指南。
当DFM首次导航到UI时,会提供一个空白画布,可在其上构建数据流:
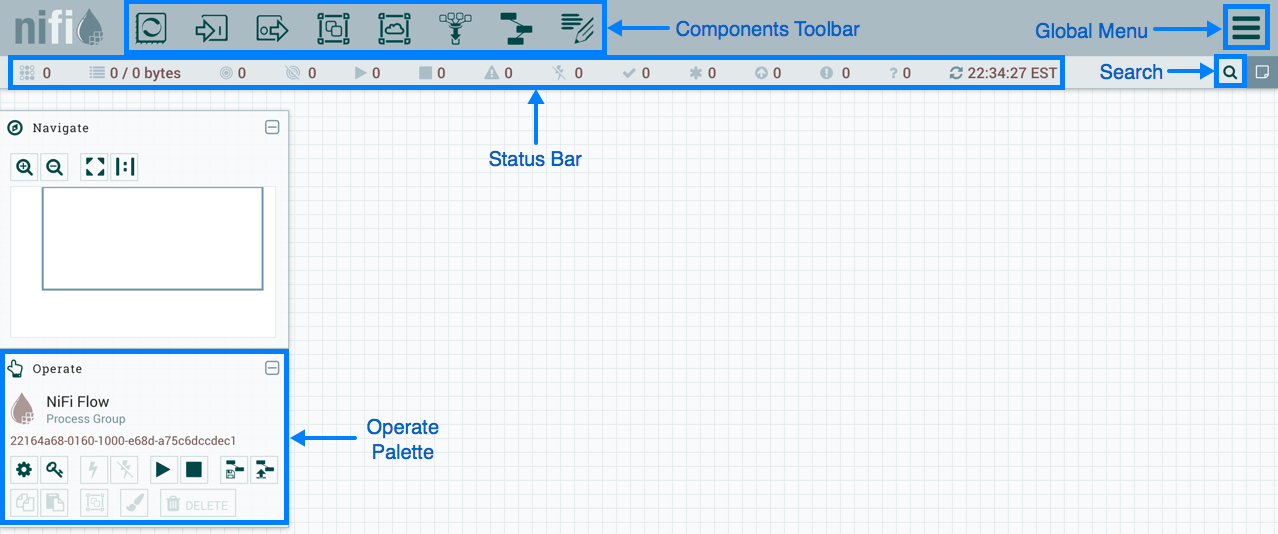
组件工具栏跨越屏幕的左上角。它包含可以拖动到画布上以构建DataFlow的组件。在构建DataFlow中更详细地描述了每个组件。
状态栏位于组件工具栏下。状态栏提供有关当前在流中处于活动状态的线程数,流中当前存在的数据量,每个状态中画布上存在的远程进程组数(传输,未传输),画布上的处理器存在于每个状态的数量信息(已停止,正在运行,无效,已禁用),每个状态下画布上存在多少个版本化的进程组(最新,本地修改,过时,本地修改和失效,同步失败)和上次刷新所有这些信息的时间戳。此外,如果NiFi实例是集群的,则状态栏会显示集群中有多少节点以及当前连接的节点数。
操作面板位于屏幕的左侧。它包含DFM用于DataFlow的一些按钮,以及管理用户访问和配置系统属性的管理员的一些按钮,例如应向应用程序提供多少系统资源。
在画布的右侧是搜索和全局菜单。您可以使用 Search 轻松查找画布上的组件,并按组件名称,类型,标识符,配置属性及其值进行搜索。全局菜单:
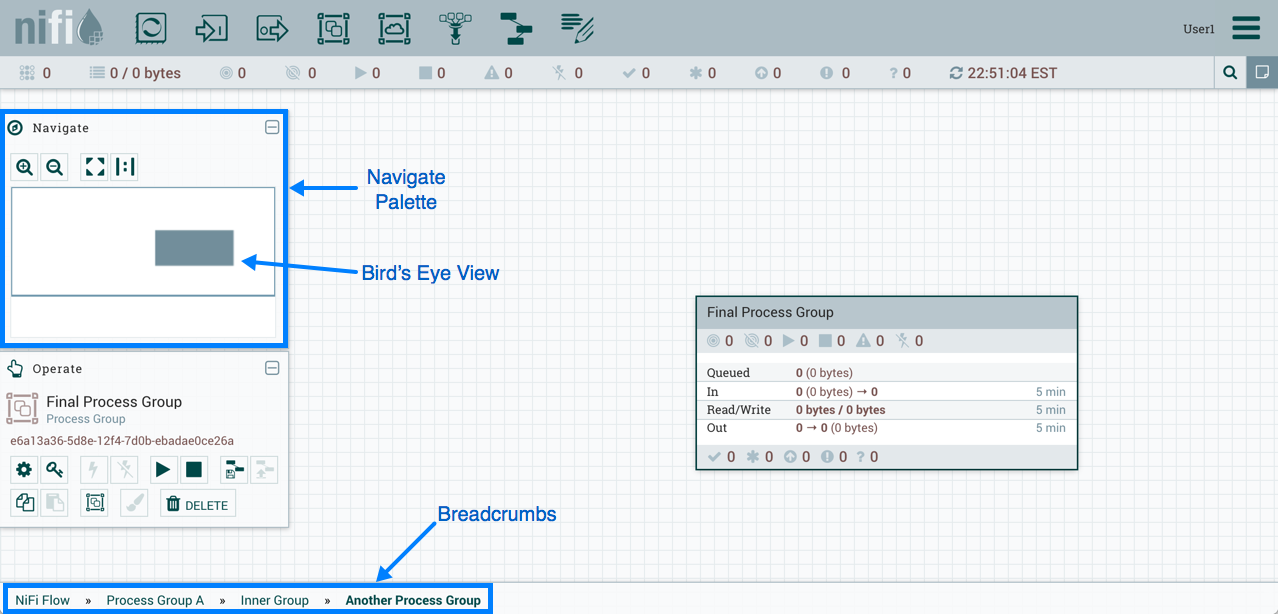
此外,UI还具有一些功能,可让您轻松浏览画布。您可以使用Navigate Palette(画布左上角,操作面板上面)在画布上平移,以及放大和缩小。数据流的Birds Eye View提供了DataFlow的高级视图,并允许您平移大部分DataFlow。您还可以在屏幕底部找到面包屑(画布底部)。当您导航进出流程组时,面包屑会显示当前流程中的深度,以及其中的每个流程组。面包屑中列出的每个进程组都是一个链接,点击可以返回相应进程组。
使用多租户授权访问UI
多租户授权允许多组用户(租户)控制和观察数据流的不同部分,具有不同级别的授权。当经过身份验证的用户尝试查看或修改NiFi资源时,系统会检查用户是否具有执行该操作的权限。这些权限由可以应用于系统范围或单个组件的策略定义。从DataFlow管理员的角度来看,这意味着一旦您有权访问NiFi画布,您就可以看到一系列功能,具体功能取决于分配给您的权限。
可用的global级别访问策略是:
| Policy | Privilege |
|---|---|
| view the UI | 允许用户查看UI |
| access the controller | 允许用户查看和修改控制器,包括报告任务,控制器服务和集群中的节点 |
| query provenance | 允许用户提交出处搜索并请求甚至沿袭 |
| access restricted components | 假设其他权限足够,允许用户创建/修改受限制的组件。受限组件可以指示需要哪些特定权限。可以为特定限制授予权限,也可以在不受限制的情况下授予权限。如果授予权限而不受限制,则用户可以创建/修改所有受限制的组件。 |
| access all policies | 允许用户查看和修改所有组件的策略 |
| access users/groups | 允许用户查看和修改用户和用户组 |
| retrieve site-to-site details | 允许其他NiFi实例检索站点到站点的详细信息 |
| view system diagnostics | 允许用户查看系统诊断 |
| proxy user requests | 允许代理计算机代表其他人发送请求 |
| access counters | 允许用户查看和修改计数器 |
可用的组件级访问策略包括:
| Policy | Privilege |
|---|---|
| view the component | 允许用户查看组件配置详细信息 |
| modify the component | 允许用户修改组件配置详细信息 |
| view provenance | 允许用户查看此组件生成的起源事件 |
| view the data | 允许用户在出站连接中的流文件队列中以及通过出处事件查看此组件的元数据和内容 |
| modify the data | 允许用户在出站连接中清空流文件队列,并通过出处事件提交重播 |
| view the policies | 允许用户查看可以查看和修改组件的用户列表 |
| modify the policies | 允许用户修改可以查看和修改组件的用户列表 |
| retrieve data via site-to-site | 允许端口从NiFi实例接收数据 |
| send data via site-to-site | 允许端口从NiFi实例发送数据 |
如果无法查看或修改NiFi资源,请与系统管理员联系,或参阅系统管理员指南中的配置用户和访问策略以 获取更多信息。
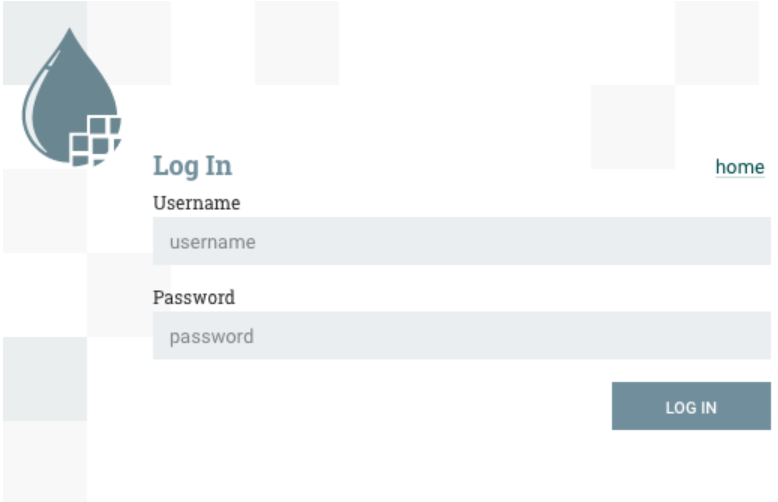
登录
如果NiFi配置为安全运行,则用户将能够请求访问DataFlow。有关配置NiFi以安全运行的信息,请参阅系统管理员指南。
如果NiFi配置为支持匿名访问,则会为用户提供相应的访问权限,并提供登录选项。
单击'login'链接将打开登录页面。如果用户使用他们的用户名/密码登录,他们将会看到一个表单。
如果NiFi未配置为支持匿名访问且用户使用其用户名/密码登录,则会立即将其发送到绕过画布的登录表单。
构建DataFlow
DFM能够使用NiFi UI构建DataFlow。只需将组件从工具栏拖到画布,配置组件以满足特定需求,并将组件连接在一起。
向画布添加组件
上面的用户界面部分概述了UI的不同部分,本节将查看该组件工具栏中的每个组件:

 处理器(Processor):处理器是最常用的组件,因为它负责数据的流入,流出,路由和操作。有许多不同类型的处理器。实际上,这是NiFi中非常常见的扩展点,这意味着许多供应商可能会实现自己的处理器来执行其所需的任何功能。将处理器拖动到画布上时,会向用户显示一个对话框,以选择要使用的处理器类型:
处理器(Processor):处理器是最常用的组件,因为它负责数据的流入,流出,路由和操作。有许多不同类型的处理器。实际上,这是NiFi中非常常见的扩展点,这意味着许多供应商可能会实现自己的处理器来执行其所需的任何功能。将处理器拖动到画布上时,会向用户显示一个对话框,以选择要使用的处理器类型:
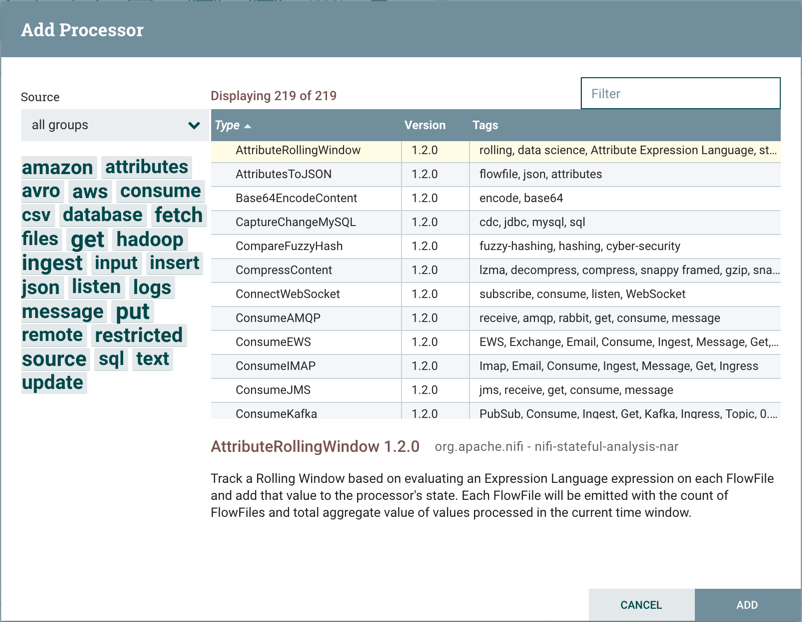
在右上角,用户可以根据处理器类型或与处理器关联的标签过滤列表。处理器开发人员能够将标签添加到其处理器中。这些标签在此对话框中用于过滤,并显示在标签云的左侧。使用特定标记存在的处理器越多,标记在标记云中显示的越大。单击云中的标记会将可用的处理器过滤为仅包含该标记的处理器。如果选择了多个标记,则仅显示包含所有这些标记的处理器。例如,如果我们只想显示那些允许我们提取文件的处理器,我们可以同时选择files 和ingest 标签:
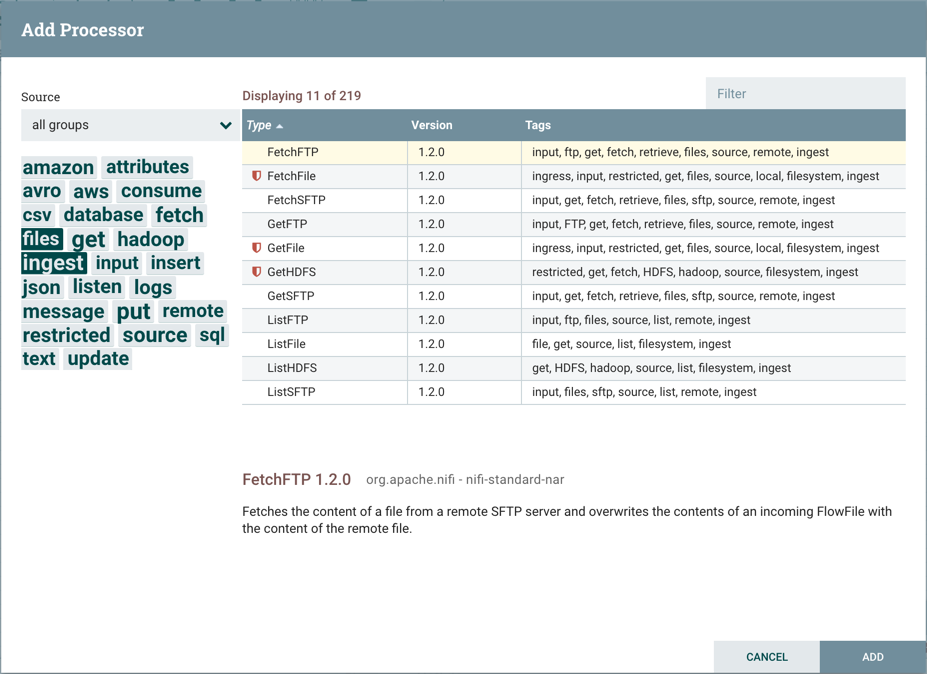
受限制的组件将在其名称旁边标有红色的盾牌图标 。这些组件可用于执行用户通过 NiFi REST API / UI 提供的代码,或者可用于使用NiFi OS凭据获取或更改NiFi主机(或其他非NIFI主机)系统上的数据(举例 ExecuteGroovyScript 执行脚本,FetchHDFS 读取文件(读权限或写权限))。这些组件可以由其他授权的NiFi用户使用,以超出应用程序的预期用途、升级特权,或者公开关于NiFi进程或主机系统内部的数据。
。这些组件可用于执行用户通过 NiFi REST API / UI 提供的代码,或者可用于使用NiFi OS凭据获取或更改NiFi主机(或其他非NIFI主机)系统上的数据(举例 ExecuteGroovyScript 执行脚本,FetchHDFS 读取文件(读权限或写权限))。这些组件可以由其他授权的NiFi用户使用,以超出应用程序的预期用途、升级特权,或者公开关于NiFi进程或主机系统内部的数据。
所有这些功能都应被视为特权,系统管理员应了解这些功能,并明确地为受信任用户授权。在允许用户创建和修改受限制的组件之前,必须授予他们访问权限。将鼠标悬停在受限图标上将显示受限组件所需的特定权限。无论限制如何,都可以分配权限。在这种情况下,用户可以访问所有受限制的组件。或者,可以为用户分配对特定限制的访问权限。如果用户已被授予对组件所需的所有限制的访问权限,则他们将具有对该组件的访问权限,否则将需要获得足够的权限。
有关更多信息,请参阅使用多租户授权访问UI和版本化流程中受限制的组件。
单击Add按钮或双击处理器类型将选定的处理器添加到画布中。
 :对于添加到画布的任何组件,可以使用鼠标选择它并将其移动到画布上的任何位置。此外,可以通过按住Shift键并选择每个项目或按住Shift键并在所需组件周围拖动选择框,一次选择多个项目。
:对于添加到画布的任何组件,可以使用鼠标选择它并将其移动到画布上的任何位置。此外,可以通过按住Shift键并选择每个项目或按住Shift键并在所需组件周围拖动选择框,一次选择多个项目。
将处理器拖到画布上后,可以通过右键单击处理器并从上下文菜单中选择一个选项来与其进行交互。根据分配给您的权限,上下文菜单中可用的选项会有所不同。
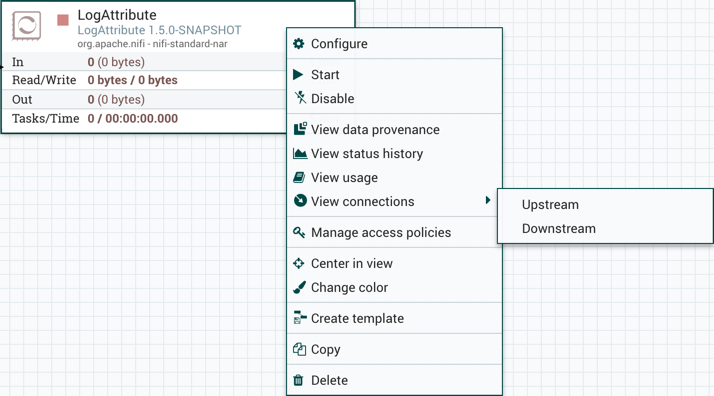
虽然上下文菜单中的选项有所不同,但是当您具有使用处理器的完全权限时,通常可以使用以下选项:
- 配置(Configure):此选项允许用户建立或更改处理器的配置(请参阅配置处理器)。
对于处理器,端口,远程进程组,连接和标签,可以通过双击所需组件来打开配置对话框。
启动(Start)或停止(stop):此选项允许用户启动或停止处理器;该选项可以是Start或Stop,具体取决于处理器的当前状态。
启用(Enable)或禁用(Disable):此选项允许用户启用或禁用处理器;该选项将为"启用"或"禁用",具体取决于处理器的当前状态。
查看数据来源(View data provenance):此选项显示NiFi数据来源表,其中包含有关通过该处理器路由的FlowFiles的数据出处事件的信息(请参阅数据来源)。
查看状态历史记录(View status history):此选项打开处理器随时间的统计信息图形表示。
查看用法(View usage):此选项将用户带到处理器的使用文档。
查看连接→上游(View connections→Upstream):此选项允许用户查看和跳转到进入处理器的上游连接。当处理器连接进出其他进程组时,这尤其有用。
查看连接→下游(View connections→Downstream):此选项允许用户查看和跳转到处理器外的下游连接。当处理器连接进出其他进程组时,这尤其有用。
视图中心(Center in view):此选项将画布的视图置于给定的处理器上。
更改颜色(Change color):此选项允许用户更改处理器的颜色,这可以使大流量的可视化管理更容易。
创建模板(Create template):此选项允许用户从所选处理器创建模板。
复制(Copy):此选项将所选处理器的副本放在剪贴板上,以便可以通过右键单击画布并选择粘贴将其粘贴到画布上的其他位置。复制/粘贴操作也可以使用按键Ctrl-C(Command-C)和Ctrl-V(Command-V)完成。
删除(Delete):此选项允许DFM从画布中删除处理器。
 输入端口(Input Port):输入端口提供将数据传输到进程组的机制。将输入端口拖动到画布上时,将提示DFM命名端口。进程组中的所有端口必须具有唯一的名称。
输入端口(Input Port):输入端口提供将数据传输到进程组的机制。将输入端口拖动到画布上时,将提示DFM命名端口。进程组中的所有端口必须具有唯一的名称。
所有组件仅存在于进程组中。当用户最初导航到NiFi页面时,用户被放置在根进程组中。如果将输入端口拖动到根进程组,则输入端口提供了一种通过站点到站点从远程NiFi实例接收数据的机制。在这种情况下,如果NiFi配置为安全运行,则可以将输入端口配置为限制对适当用户的访问。有关配置NiFi以安全运行的信息,请参阅" 系统管理员指南"。
 输出端口(Output Port):输出端口提供了一种机制,用于将数据从进程组传输到进程组外部的目标。将输出端口拖动到画布上时,将提示DFM命名端口。进程组中的所有端口必须具有唯一的名称。
输出端口(Output Port):输出端口提供了一种机制,用于将数据从进程组传输到进程组外部的目标。将输出端口拖动到画布上时,将提示DFM命名端口。进程组中的所有端口必须具有唯一的名称。
如果将输出端口拖动到根进程组,则输出端口提供了一种通过站点到站点将数据发送到远程NiFi实例的机制。在这种情况下,端口充当队列。当NiFi的远程实例从端口提取数据时,该数据将从传入的Connections的队列中删除。如果NiFi配置为安全运行,则可以将输出端口配置为限制适当用户的访问。有关配置NiFi以安全运行的信息,请参阅系统管理员指南。
 进程组(Process Group):进程组可用于对一组组件进行逻辑分组,以便更容易理解和维护DataFlow。将进程组拖动到画布上时,将提示DFM命名进程组。同一父组中的所有进程组必须具有唯一的名称。然后,进程组将嵌套在该父组中。
进程组(Process Group):进程组可用于对一组组件进行逻辑分组,以便更容易理解和维护DataFlow。将进程组拖动到画布上时,将提示DFM命名进程组。同一父组中的所有进程组必须具有唯一的名称。然后,进程组将嵌套在该父组中。
将进程组拖到画布上后,可以通过右键单击进程组并从上下文菜单中选择一个选项来与其进行交互。从上下文菜单中可用的选项会有所不同,具体取决于分配给您的权限。
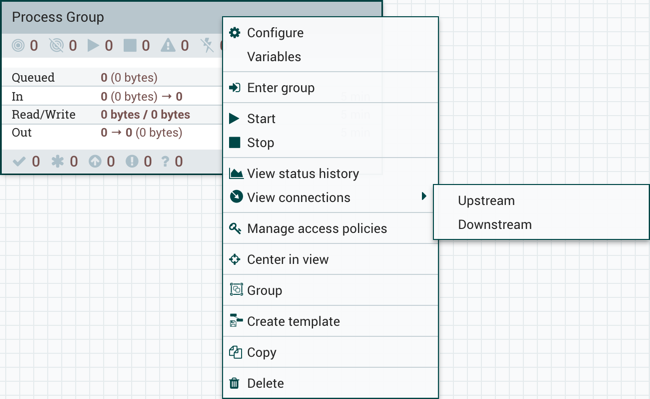
虽然上下文菜单中提供的选项各不相同,但如果您具有进程组的完全使用权限,则通常可以使用以下选项:
配置(Configure):此选项允许用户建立或更改进程组的配置。
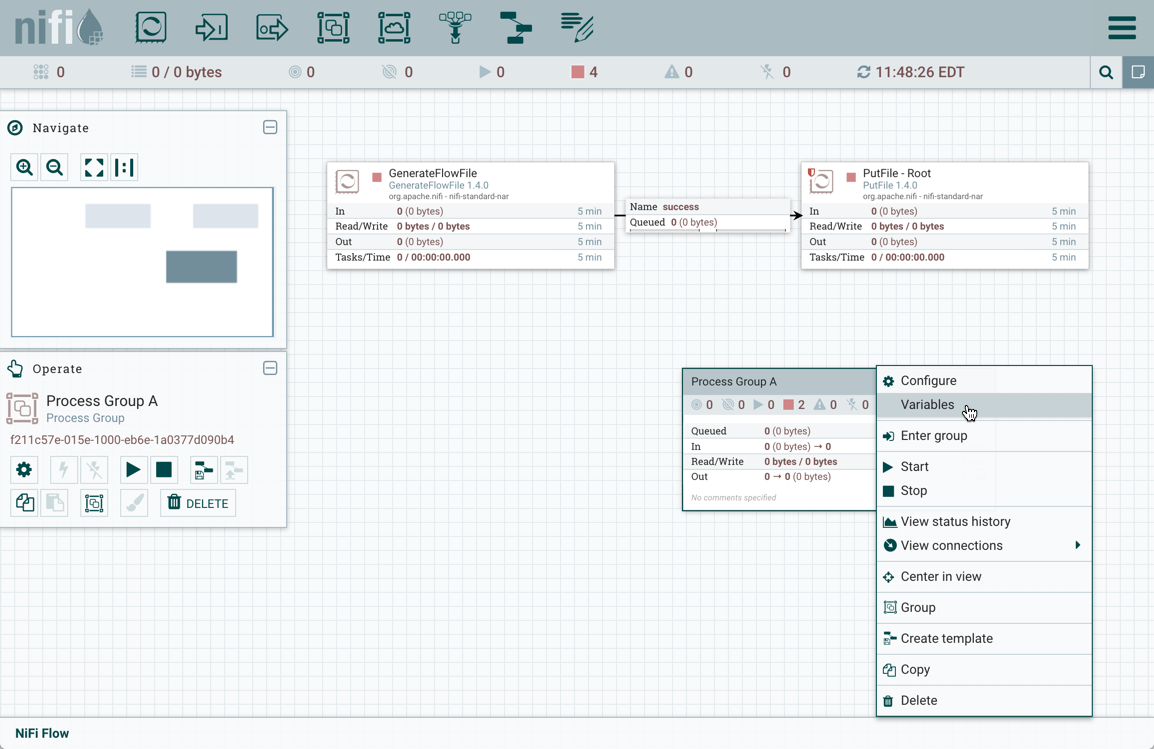
变量(Variables):此选项允许用户在NiFi UI中创建或配置变量。
输入组(Enter group):此选项允许用户进入进程组。
也可以双击进程组输入它。
开始(Start):此选项允许用户启动进程组。
停止(Stop):此选项允许用户停止进程组。
查看状态历史记录(View status history):此选项打开过程组随时间变化的统计信息的图形表示。
查看连接→上游(View connections→Upstream):此选项允许用户查看和跳转进入进程组的上游连接。
查看连接→下游(View connections→Downstream):此选项允许用户查看和跳转到流程组外的下游连接。
视图中心(Center in view):此选项将画布视图置于给定进程组的中心。
组(Group):此选项允许用户创建一个新的流程组,其中包含选定的流程组和在画布上选择的任何其他组件。
创建模板(Create template):此选项允许用户从选定的进程组创建模板。
复制(Copy):此选项将所选进程组的副本放在剪贴板上,以便可以通过右键单击画布并选择"粘贴"将其粘贴到画布上的其他位置。复制/粘贴操作也可以使用按键Ctrl-C(Command-C)和Ctrl-V(Command-V)完成。
删除(Delete):此选项允许DFM删除进程组。
 远程进程组(Remote Process Group):远程进程组显示和行为都类似于进程组。但是,远程进程组(RPG)引用了NiFi的远程实例。将RPG拖动到画布上时,不会提示输入名称,而是提示DFM输入远程NiFi实例的URL。如果远程NiFi是集群模式,则应使用的URL是该集群中任意NiFi实例的URL。当数据通过RPG传输到NiFi集群时,RPG将首先连接到远程实例,其URL配置会帮助确定集群中的节点以及每个节点的繁忙程度。然后,此信息用于对推送到每个节点的数据进行负载平衡。然后定期询问远程实例,以确定有关从集群中删除或添加到集群的任何节点的信息,并根据每个节点的负载重新计算负载平衡。有关更多信息,请参阅有关的部分站点到站点。
远程进程组(Remote Process Group):远程进程组显示和行为都类似于进程组。但是,远程进程组(RPG)引用了NiFi的远程实例。将RPG拖动到画布上时,不会提示输入名称,而是提示DFM输入远程NiFi实例的URL。如果远程NiFi是集群模式,则应使用的URL是该集群中任意NiFi实例的URL。当数据通过RPG传输到NiFi集群时,RPG将首先连接到远程实例,其URL配置会帮助确定集群中的节点以及每个节点的繁忙程度。然后,此信息用于对推送到每个节点的数据进行负载平衡。然后定期询问远程实例,以确定有关从集群中删除或添加到集群的任何节点的信息,并根据每个节点的负载重新计算负载平衡。有关更多信息,请参阅有关的部分站点到站点。
将远程进程组拖到画布上后,可以通过右键单击远程进程组并从上下文菜单中选择一个选项来与其进行交互。根据分配给您的权限,上下文菜单中可用的选项会有所不同。
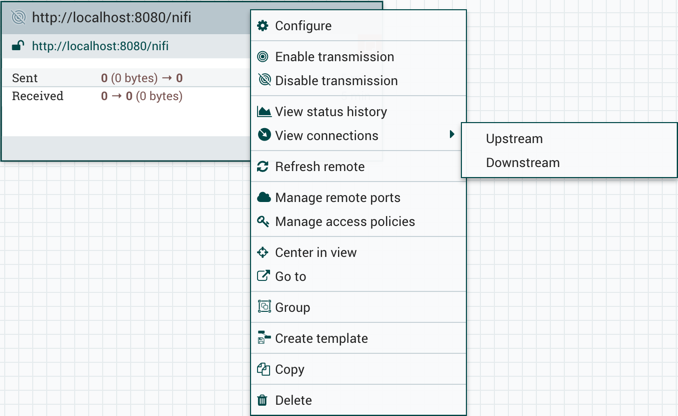
虽然上下文菜单中的选项有所不同,但是当您具有远程进程组的完全使用权限时,通常可以使用以下选项:
配置(Configure):此选项允许用户建立或更改远程进程组的配置。
启用传输(Enable transmission):激活NiFi实例之间的数据传输(请参阅远程进程组传输)。
禁用传输(Disable transmission):禁用NiFi实例之间的数据传输。
查看状态历史记录(View status history):此选项打开远程过程组随时间变化的统计信息的图形表示。
查看连接→上游(View connections→Upstream):此选项允许用户查看和"跳转"进入远程进程组的上游连接。
查看连接→下游(View connections→Downstream):此选项允许用户查看和"跳转"到远程进程组外的下游连接。
刷新远程(Refresh remote):此选项刷新远程NiFi实例的状态视图。
组(Group):此选项允许用户创建包含所选远程进程组和在画布上选择的任何其他组件的新进程组。
管理远程端口(Manage remote ports):此选项允许用户查看远程进程组连接到的远程NiFi实例上存在的输入端口和/或输出端口。请注意,如果站点到站点配置是安全的,则仅可以看到已访问连接的NiFi的端口。
视图中心(Center in view):此选项将画布的视图置于给定的远程进程组的中心。
转到(Go to):此选项在浏览器的新选项卡中打开远程NiFi实例的视图。请注意,如果站点到站点配置是安全的,则用户必须能够访问远程NiFi实例才能查看它。
创建模板(Create template):此选项允许用户从选定的远程进程组创建模板。
复制(Copy):此选项将所选进程组的副本放在剪贴板上,以便可以通过右键单击画布并选择"粘贴"将其粘贴到画布上的其他位置。复制/粘贴操作也可以使用按键Ctrl-C(Command-C)和Ctrl-V(Command-V)完成。
删除(Delete):此选项允许DFM从画布中删除远程进程组。
 漏斗(Funnel):漏斗用于将来自多个Connections的数据合并到一个Connection中。这有两个好处。首先,如果使用相同的数据源创建了许多Connection,而如果这些连接必须跨越大空间,则画布可能会变得混乱。通过将这些Connections汇集到一个Connection中,可以绘制一个Connection来跨越该大空间就可以了。其次,可以使用FlowFile优先级配置器配置Connections。来自多个Connections的数据可以汇集到一个Connection中,从而能够对该一个Connection上的所有数据进行优先级排序,而不是单独确定每个Connection上的数据的优先级。
漏斗(Funnel):漏斗用于将来自多个Connections的数据合并到一个Connection中。这有两个好处。首先,如果使用相同的数据源创建了许多Connection,而如果这些连接必须跨越大空间,则画布可能会变得混乱。通过将这些Connections汇集到一个Connection中,可以绘制一个Connection来跨越该大空间就可以了。其次,可以使用FlowFile优先级配置器配置Connections。来自多个Connections的数据可以汇集到一个Connection中,从而能够对该一个Connection上的所有数据进行优先级排序,而不是单独确定每个Connection上的数据的优先级。
 模板(Template):模板可以由流的各个部分的DFM创建,也可以从其他DataFlow导入。这些模板提供了更大的构建块,可以快速创建复杂的流程。将模板拖动到画布上时,DFM会提供一个对话框,用于选择要添加到画布的模板:
模板(Template):模板可以由流的各个部分的DFM创建,也可以从其他DataFlow导入。这些模板提供了更大的构建块,可以快速创建复杂的流程。将模板拖动到画布上时,DFM会提供一个对话框,用于选择要添加到画布的模板:
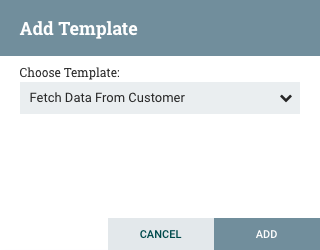
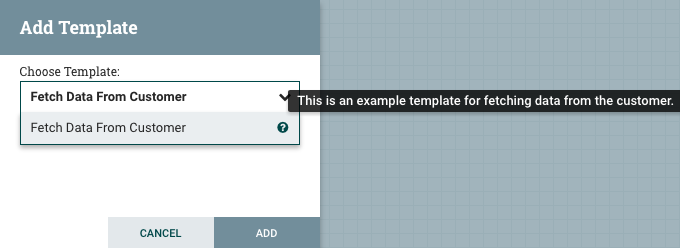
单击下拉框可显示所有可用模板。创建的任何使用描述了的模板都将显示一个问号图标,会提供有更多信息。使用鼠标将鼠标悬停在图标上将显示以下说明:
 标签(Label):标签用于为数据流的各个部分提供文档说明。将Label放到画布上时,会使用默认大小创建它。然后可以通过拖动右下角的手柄来调整Label的大小。标签在最初创建时没有文本。可以通过右键单击Label并选择Configure来添加Label的文本。
标签(Label):标签用于为数据流的各个部分提供文档说明。将Label放到画布上时,会使用默认大小创建它。然后可以通过拖动右下角的手柄来调整Label的大小。标签在最初创建时没有文本。可以通过右键单击Label并选择Configure来添加Label的文本。
组件版本
您可以访问有关Processors,Controller Services和Reporting Tasks的版本的信息。Add Processor,Add Controller Service和Add Reporting Task对话框包括一个标识组件版本的列,以及组件的名称,创建组件的组织或组以及包含该组件的NAR包。
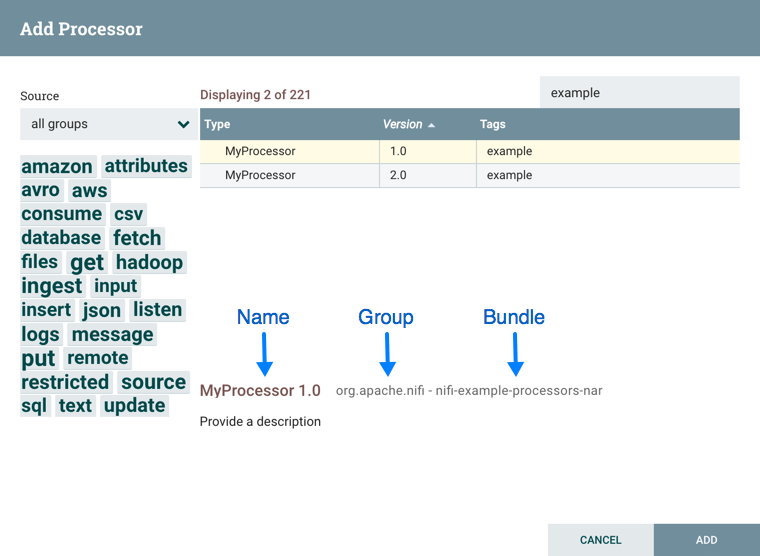
画布上显示的每个组件也包含此信息。
排序和过滤组件
添加组件时,可以根据版本号排序,也可以根据源文件进行筛选。
要基于版本进行排序,请单击版本列以按升序或降序显示。
要基于源组进行过滤,请单击 Add Component对话框左上角的源下拉列表,然后选择要查看的组。
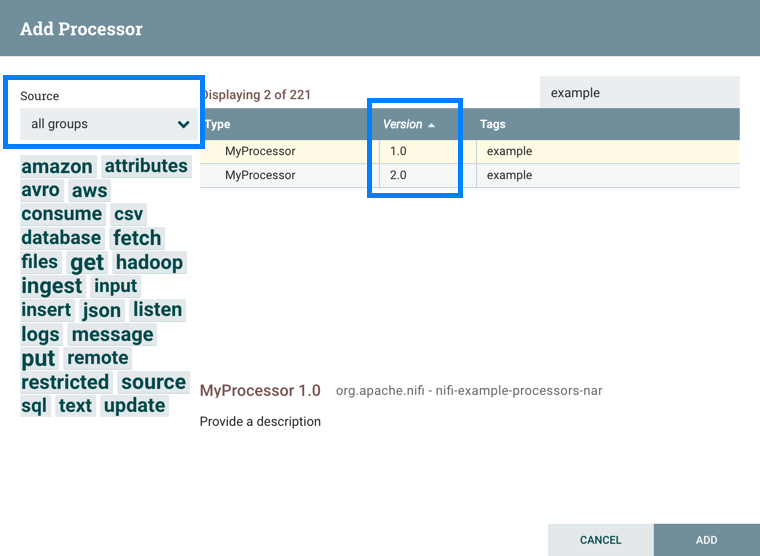
更改组件版本
要更改组件版本,请执行以下步骤。
右键单击画布上的组件以显示配置选项。
选择更改版本。
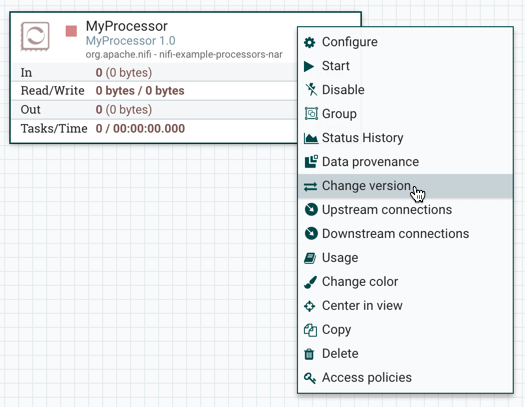
- 在Component Version对话框中,从Version下拉菜单中选择要运行的版本。
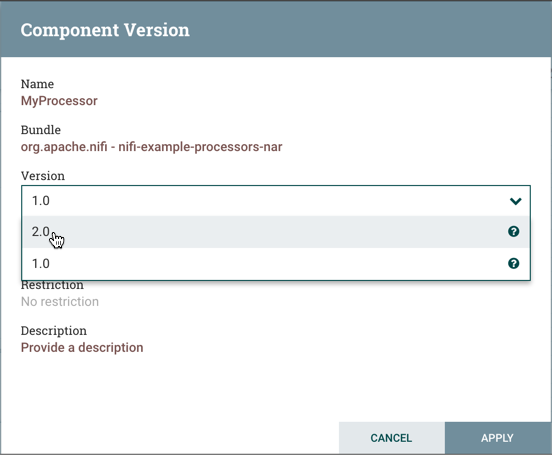
了解版本依赖关系
配置组件时,还可以查看有关版本依赖性的信息。
右键单击组件,然后选择Configure 以显示组件的Configure 对话框。
单击Properties 选项卡。
单击信息图标以查看版本依赖关系信息。
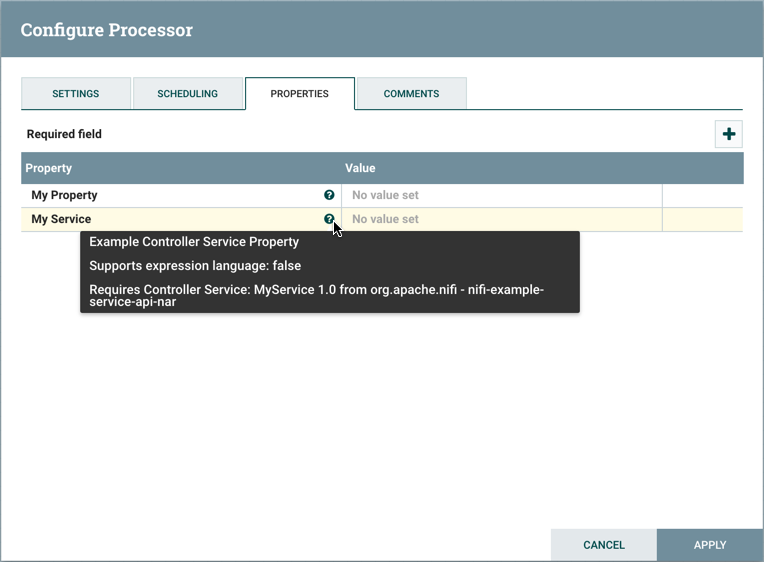
在以下示例中,使用控制器服务StandardMyService 1.0版正确配置了MyProcessor 1.0版:
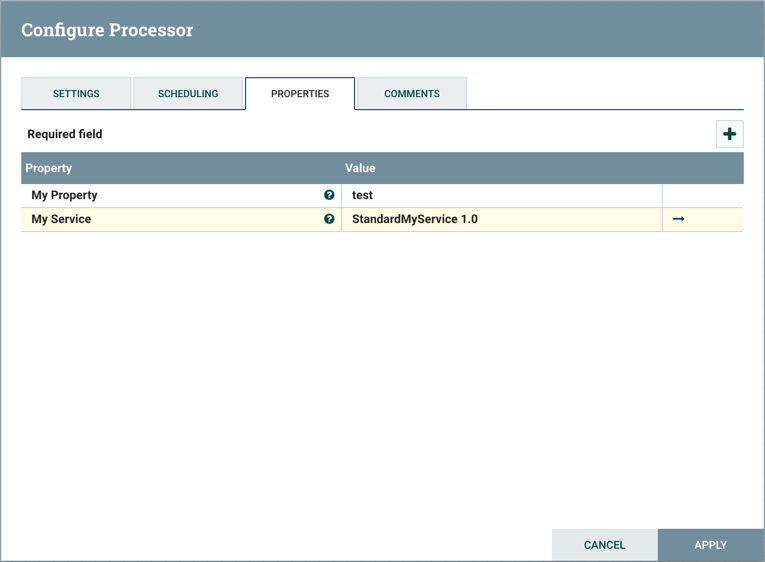
如果MyProcessor的版本更改为不兼容的版本(MyProcessor 2.0),则验证错误将显示在处理器上
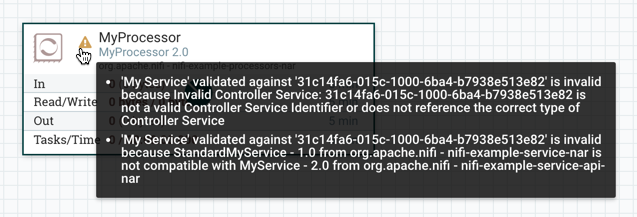
并且由于服务不再有效,因此处理器的控制器服务配置中将显示错误消息:
配置处理器
要配置处理器,请右键单击处理器,然后从上下文菜单中选择Configure选项。或者,双击处理器。打开配置对话框,其中包含四个不同的选项卡,每个选项卡将在下面逐一进行讲解。完成处理器配置后,可以通过单击Apply按钮更改应用,或单击Cancel按钮取消所有更改。
请注意,处理器启动后,为处理器显示的上下文菜单不再有Configure 选项,而是有一个View Configuration选项。处理器运行时无法更改处理器配置。必须先停止处理器并等待其所有活动任务完成,然后再次配置处理器。
请注意,配置里不支持输入某些控制字符,并在输入时自动过滤掉。任何配置中都不会保留以下字符和任何未配对的Unicode代理点代码点:
[#x0],[#x1],[#x2],[#x3],[#x4],[#x5],[#x6],[#x7],[#x8],[#xB], [#xC],[#xE],[#XP],[#x10],[#x11],[#x12],[#x13],[#x14],[#x15],[#x16], [#x17],[#x18],[#x19],[#x1A],[#x1B],[#x1C],[#x1D],[#x1E],[#x1F],[#xFFFE], [#xFFFF]
设置(Settings)
处理器配置对话框中的第一个选项卡是Settings选项卡:
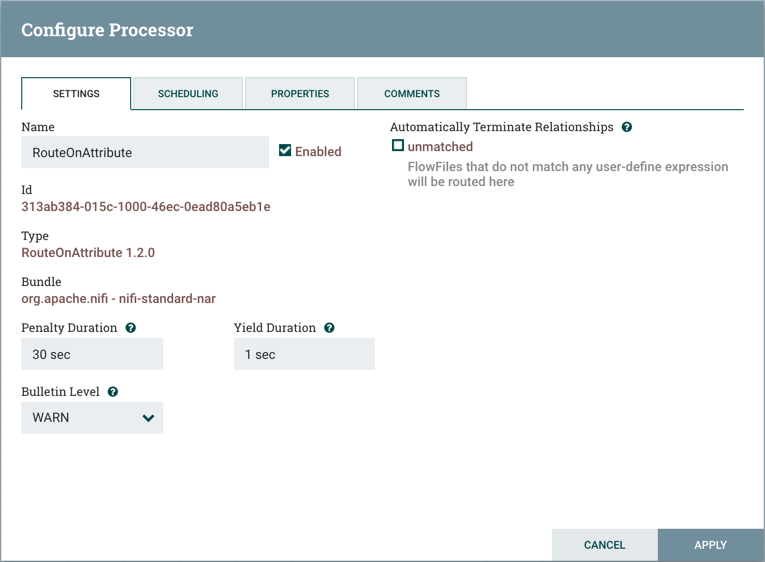
此选项卡包含几个不同的配置项。首先,它允许DFM更改处理器的名称。默认情况下,处理器的名称与处理器类名相同。处理器名称旁边是一个复选框,指示处理器是否已启用。将处理器添加到画布后,将启用它。如果禁用处理器,则无法启动。禁用状态用于指示当启动一组处理器时,例如当DFM启动整个进程组时,应排除此(disabled)处理器。
在Name配置下方,将显示Processor的唯一标识符以及Processor的类名和NAR包。这些值无法修改。
接下来是两个用于配置Penalty Duration和Yield Duration的对话框。在处理一条数据(FlowFile)的正常过程中,可能发生事件,该事件指示处理器此时不能处理数据但是数据可以在稍后进行处理。在发生这种情况时,处理器可以选择Penalize FlowFile。这将阻止FlowFile在一段时间内被处理。例如,如果处理器要将数据推送到远程服务,但远程服务已经有一个与处理器指定的文件名同名的文件,则处理器可能会惩罚FlowFile。Penalty Duration允许DFM指定FlowFile应该受到多长时间的惩罚。默认值为30 seconds。(简单理解为推后一段时间再处理)
类似地,处理器可以确定存在某种情况,处理器没法进行处理数据。例如,如果处理器要将数据推送到远程服务并且该服务没有响应。这样的话处理器应该Yield,这将阻止处理器运行一段时间。通过设置Yield Duration来指定该时间段。默认值为1 second。
Settings选项卡左侧的最后一个可配置选项是Bulletin级别。每当处理器写日志时,处理器将生成公告。此设置指示应在用户界面中显示的最低级别的公告。默认情况下,公告级别设置为WARN,这意味着它将显示所有警告和错误级别公告。
Settings选项卡的右侧包含自动终止关系(Automatically Terminate Relationships)部分。此处列出了处理器定义的每个关系及其描述。为了使处理器被视为有效且能够运行,处理器定义的每个关系必须连接到下游组件或自动终止。如果关系是自动终止的,则将从流中删除任何路由到该关系的FlowFile,并视其为处理完成。已连接到下游组件的任何关系都无法自动终止。必须首先从使用它的所有Connection中删除关系。此外,对于选择自动终止的关系,如果将关系添加到连接,则自动终止状态将被清除(turned off)。
调度(Scheduling)
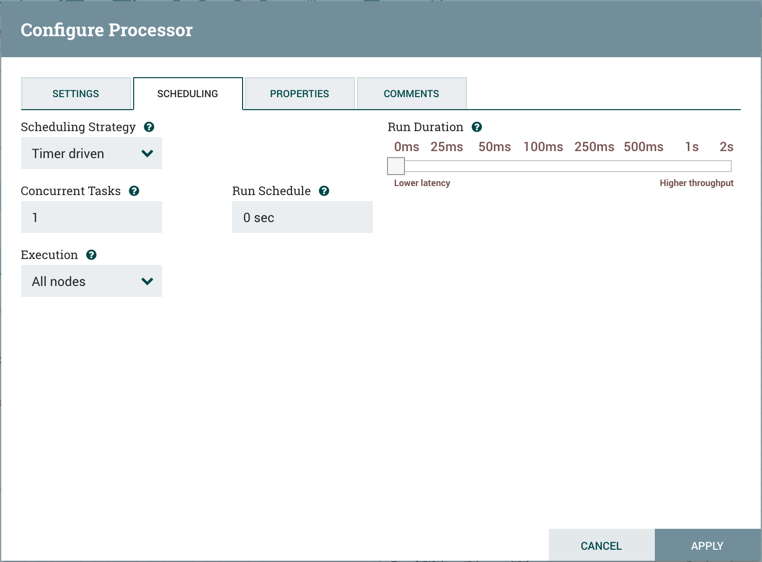
处理器配置对话框中的第二个选项卡是Scheduling选项卡:
调度策略
第一个配置选项是调度策略。调度有三种可能的选项:
Timer driven:这是默认模式。处理器将定期运行。运行处理器的时间间隔由Run Schedule选项定义(见下文)。
Event driven:选择此模式时,将由一个事件触发处理器运行,当FlowFiles进入连接此处理器的Connections时,将产生这个事件。此模式目前被认为是实验性的,并非所有处理器都支持。选择此模式时,Run Schedule选项不可配置。此外,只有此模式下Concurrent Tasks选项可以设置为0。这种情况,线程数仅受管理员配置的事件驱动线程池的大小限制。
CRON驱动:当使用CRON驱动的调度模式时,处理器将定期运行,类似于定时器驱动的调度模式。CRON驱动模式提供了更大的灵活性。CRON驱动的调度值是由六个必需字段和一个可选字段的字符串组成,每个字段由空格分隔。这些字段是:
| Field | Valid values |
|---|---|
| Seconds | 0-59 |
| Minutes | 0-59 |
| Hours | 0-23 |
| Day of Month | 1-31 |
| Month | 1-12 or JAN-DEC |
| Day of Week | 1-7 or SUN-SAT |
| Year (optional) | empty, 1970-2099 |
您通常通过以下方式来指定值:
数字:指定一个或多个有效值。您可以使用逗号分隔列表输入多个值。
范围:使用 number-number语法指定范围。
增量:使用 start value/increment语法指定增量。例如,在"分钟"字段中,0/15表示分钟0,15,30和45。
您还应该知道几个有效的特殊字符:
* 表示所有值对该字段都有效。
? 表示未指定特定值。此特殊字符在"Day of Month"和"Day of Week"字段中有效。
L 您可以将L附加到星期值之一,以指定该月中该日的最后一次出现。例如,1L表示该月的最后一个星期日。
例如:
该字符串0 0 13 * * ?表示您希望将处理器安排在每天下午1:00运行。
该字符串0 20 14 ? * MON-FRI表示您希望将处理器安排在每周一至周五下午2:20运行。
该字符串0 15 10 ? * 6L 2011-2017表示您希望将处理器安排在2011年至2017年的每个月的最后一个星期五上午10:15运行。
有关其他信息和示例,请参阅Quartz文档中的ChronTrigger教程。
并发任务
接下来,Scheduling选项卡提供名为'Concurrent Tasks'的配置选项。这可以控制处理器将使用的线程数。换句话说,它控制此处理器应同时处理多少个FlowFiles。增加此值通常会使处理器在相同的时间内处理更多数据。但是,它是通过使用其他处理器无法使用的系统资源来实现此目的。这基本上提供了处理器的相对权重 - 应该将多少系统资源分配给此处理器而不是其他处理器。该字段适用于大多数处理器。但是,某些类型的处理器只能使用单个任务进行调度。
运行计划
"Run Schedule"指示处理器运行的频率。此字段的有效值取决于所选的调度策略(参见上文)。如果使用事件驱动的调度策略,则此字段不可用。使用定时器驱动的调度策略时,该值是由数字后跟时间单位指定的持续时间。例如,1 second或5 mins。默认值0 sec表示处理器应尽可能频繁地运行,只要它有要处理的数据即可。有关适用于CRON驱动的调度策略的值的说明,请参阅CRON驱动的调度策略本身的说明。
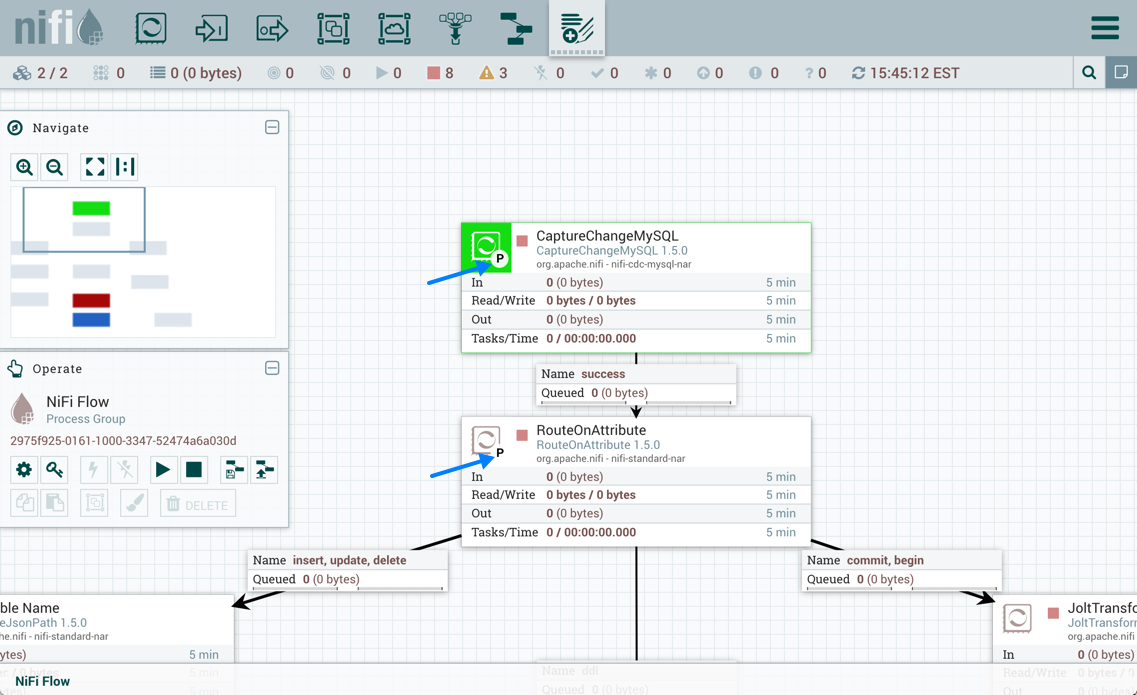
执行
执行设置用于确定处理器将被调度执行的节点。选择"All Nodes"将导致在集群中的每个节点上调度此处理器。选择"Primary Node"将导致此处理器仅在主节点上进行调度。已配置"Primary Node"执行的处理器由处理器图标旁边的"P"标识:
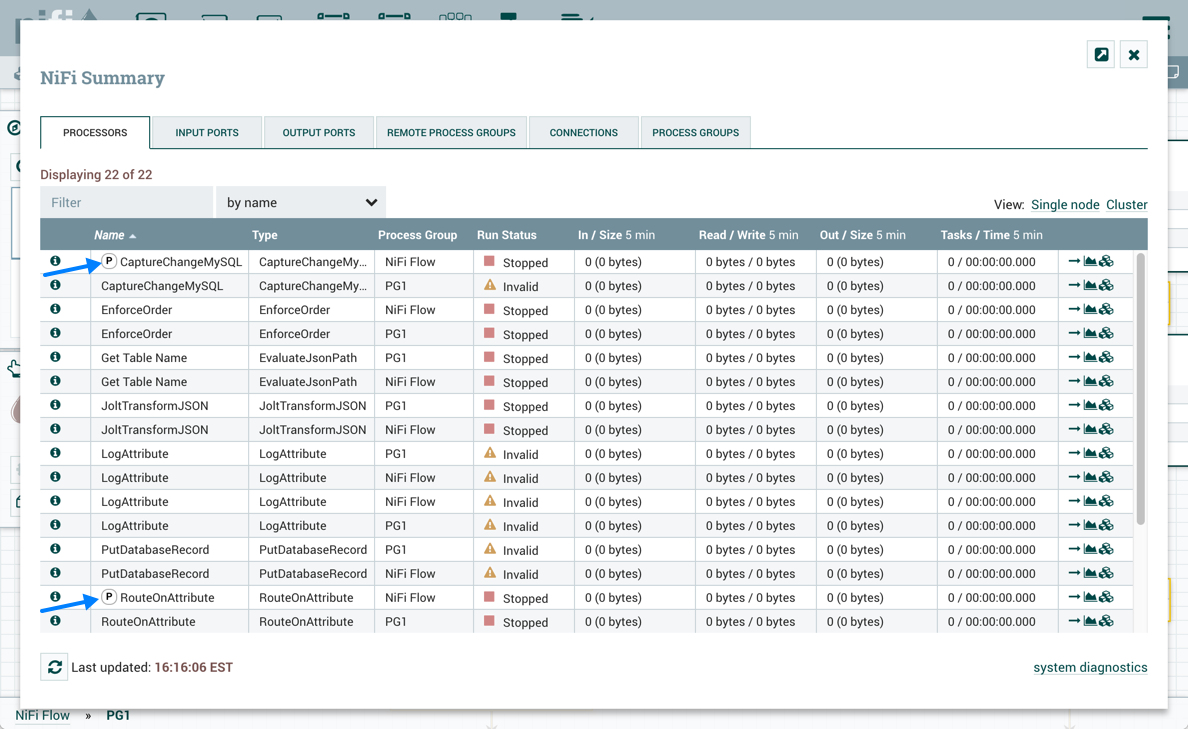
要快速识别"Primary Node"处理器,"P"图标也会显示在摘要页面的处理器选项卡中:
运行持续时间
"Run Duration"选项卡的右侧包含一个用于选择运行持续时间的滑块。这可以控制处理器每次触发时应安排运行的时间。在滑块的左侧,标记为"Lower latency(较低延迟)",而右侧标记为"Higher throughput(较高吞吐量)"。处理器完成运行后,必须更新存储库才能将FlowFiles传输到下一个Connection。更新存储库的成本很高,因此在更新存储库之前可以立即完成的工作量越多,处理器可以处理的工作量就越多(吞吐量越高)。这意味着在上一批数据处理更新此存储库之前,Processor是无法开始处理接下来的FlowFiles。结果是,延迟时间会更长(从开始到结束处理FlowFile所需的时间会更长)。因此,滑块提供了一个频谱,DFM可以从中选择支持较低延迟或较高吞吐量。
属性(Properties)
Properties选项卡提供了一种特定于Processor的行为机制的配置。每种类型的处理器必须定义哪些属性对其用例有意义。下面,我们看到RouteOnAttribute Processor的Properties选项卡:
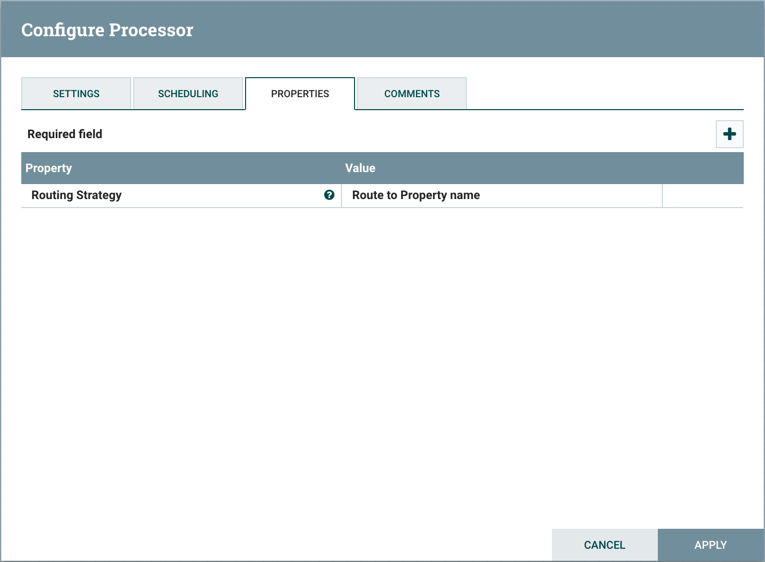
默认情况下,此处理器只有一个属性:"Routing Strategy"。默认值为"Route to Property name"。此属性的名称旁边是一个小问号符号 。在整个用户界面的其他位置也可以看到此帮助符号,它表示可以获得更多信息。使用鼠标将鼠标悬停在此符号上将提供有关属性和默认值的其他详细信息,以及为该属性设置的历史值。
。在整个用户界面的其他位置也可以看到此帮助符号,它表示可以获得更多信息。使用鼠标将鼠标悬停在此符号上将提供有关属性和默认值的其他详细信息,以及为该属性设置的历史值。
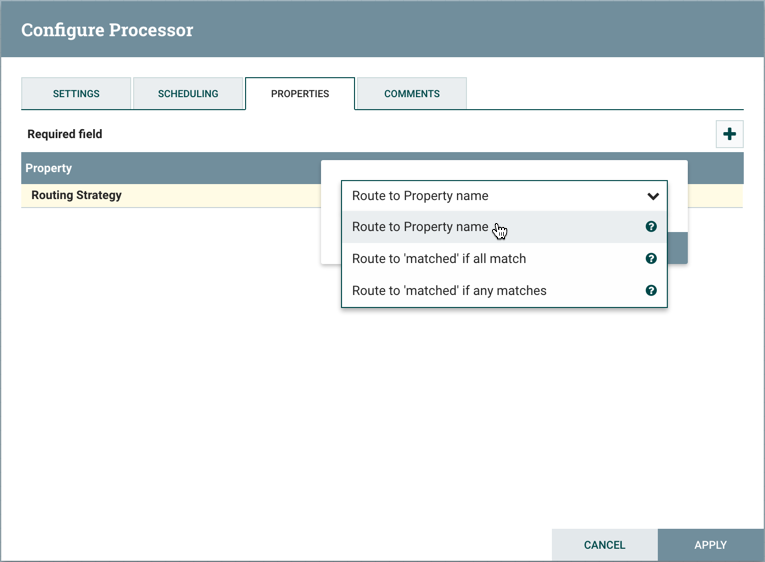
单击属性的值将允许DFM更改该值。根据属性允许的值,向用户提供从中选择值的下拉列表,或者为用户提供键入值的文本区域:
选项卡的右上角是一个用于添加新属性的按钮。单击此按钮将为DFM提供一个对话框,用于输入新属性的名称和值。并非所有处理器都允许用户自定义的属性。在不允许它们的处理器中,处理器在应用用户定义属性时变为无效。但是,RouteOnAttribute允许用户定义的属性。实际上,在用户添加属性之前,此处理器无效。
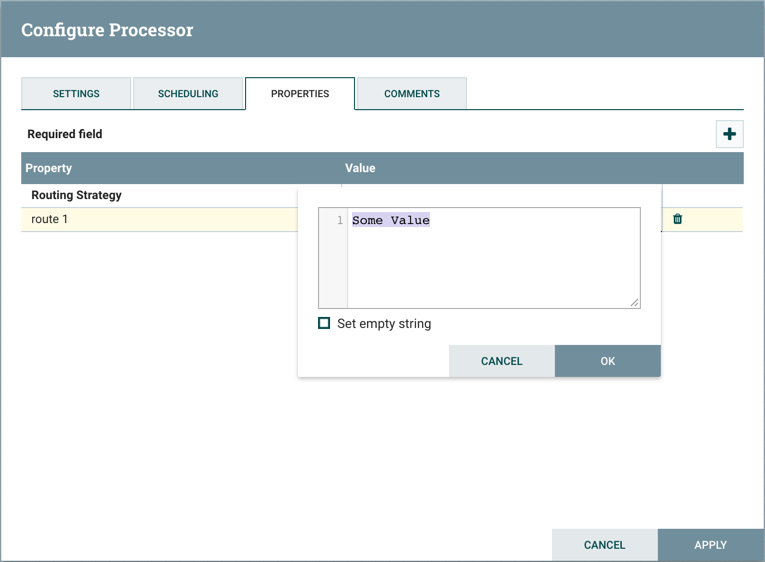
请注意,添加了User-Defined属性后,该行的右侧将出现一个图标 。单击它将从处理器中删除用户定义的属性。
。单击它将从处理器中删除用户定义的属性。
某些处理器还内置了高级用户界面(UI)。例如,UpdateAttribute处理器具有高级UI。要访问高级用户界面,请单击Advanced"配置处理器"窗口底部显示的按钮。只有具有高级UI的处理器才具有此按钮。
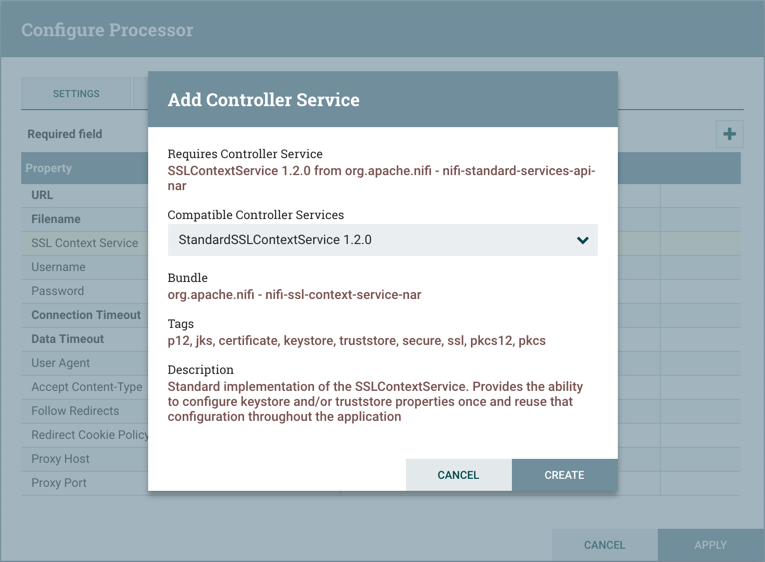
某些处理器具有引用其他组件的属性,例如Controller Services,这些组件也需要进行配置。例如,GetHTTP处理器具有SSLContextService属性,该属性引用StandardSSLContextService控制器服务。当DFM想要配置此属性但尚未创建和配置控制器服务时,他们可以选择在现场创建服务,如下图所示。有关配置Controller Services的详细信息,请参阅Controller Services部分。
注释(Comments)
处理器配置对话框中的最后一个选项卡是注释选项卡。此选项卡仅为用户提供一个区域,以包含适用于此组件的任何注释。注释选项卡是可选的:
Processor帮助文档
您可以通过右键单击处理器并从上下文菜单中选择"Usage"来访问有关每个处理器使用情况的其他文档。或者,从UI右上角的全局菜单中选择帮助,以显示包含所有文档的帮助页面,包括所有可用处理器的使用文档。单击所需的处理器以查看使用文档。
使用表达式语言自定义属性(NIFI Expression Language)
您可以使用NiFi表达式语言来引用FlowFile属性,将它们与其他值进行比较,并在创建和配置数据流时操纵它们的值。有关表达式语言的更多信息,请参阅表达式语言指南。
除了在Express Language中使用FlowFile属性,系统属性和环境属性之外,您还可以使用自定义属性来定义表达式语言。自定义属性可以更灵活地处理数据流。
在创建自定义属性时,应该注意NiFi属性具有优先级:
Processor-specific attributes
FlowFile properties
FlowFile attributes
变量注册表:
用户定义的属性(自定义属性)
系统属性
操作系统环境变量
在创建自定义属性时,请确保每个自定义属性包含不同的属性值,以便现有环境属性,系统属性或FlowFile属性不会覆盖它。
有两种方法可以使用和管理自定义属性:
在NiFi UI中通过Variables窗口
通过nifi.properties引用自定义属性
变量窗口
可以在NiFi UI中创建和配置变量。变量可用于支持表达式语言的任何字段。NiFi自动获取在UI中创建的新变量或修改变量。
要访问Variables 窗口,请右键单击画布空白处:
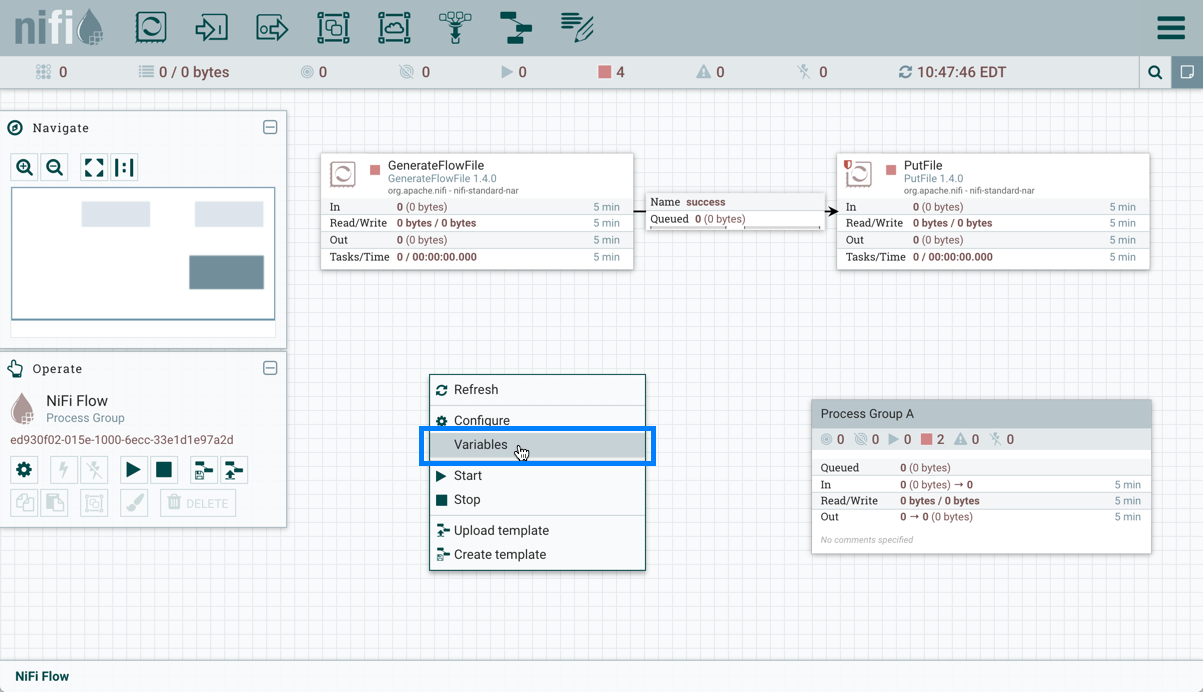
从上下文菜单中选择Variables:
![]()
选择进程组时,右键单击上下文菜单中也可以使用Variables:
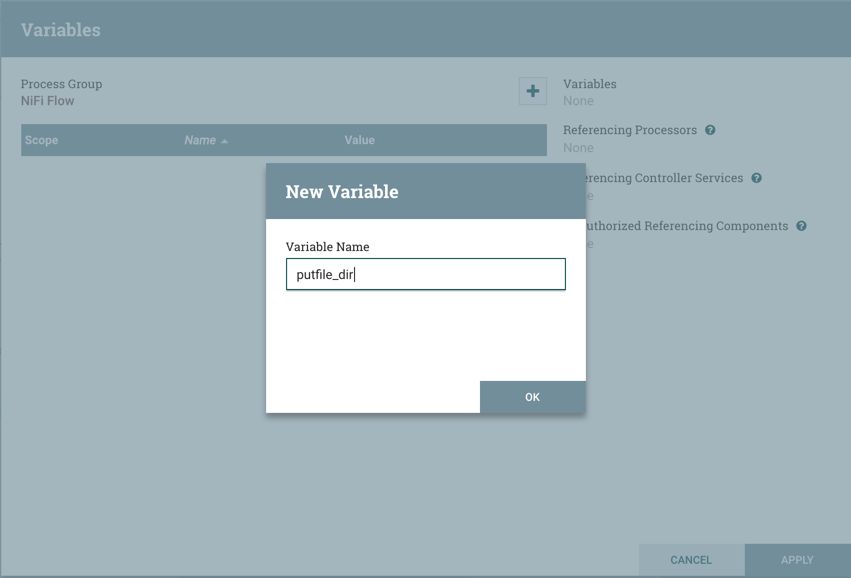
创建变量
在Variables窗口中,单击+按钮以创建新变量。添加名称:
和一个值:
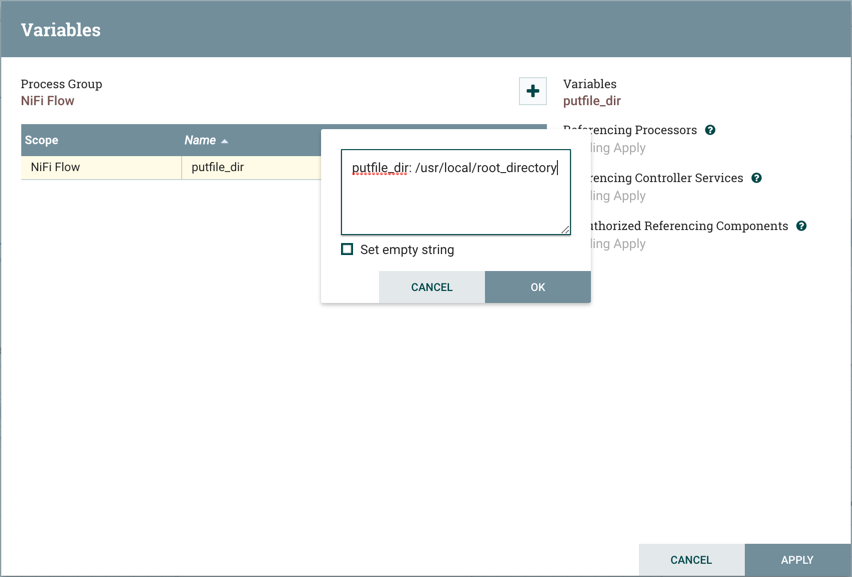
选择Apply:
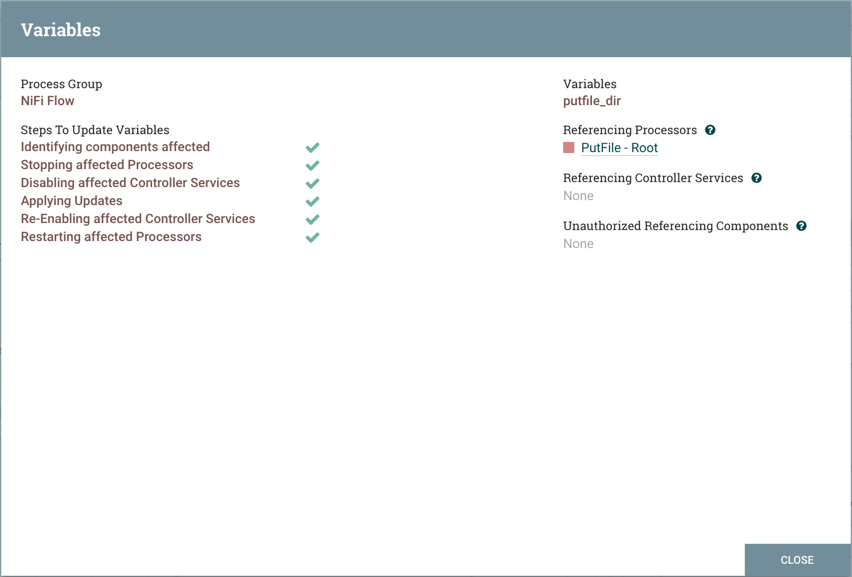
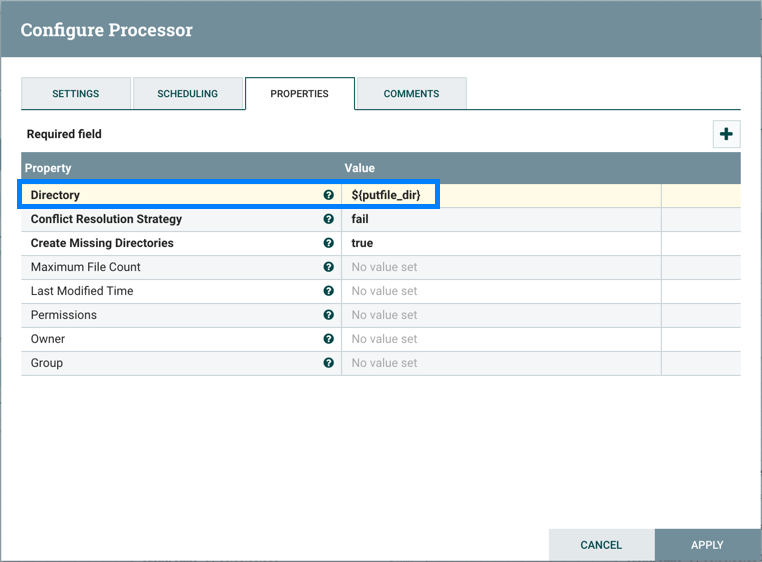
执行更新变量的步骤(识别受影响的组件,停止受影响的处理器等)。例如,Referencing Processors部分现在列出了"PutFile-Root"处理器。在列表中选择处理器的名称将导航到画布上的该处理器。查看处理器的属性,${putfile_dir}由Directory属性引用:
变量的作用域
变量的作用域由它们定义的进程组确定,并且可供该级别及以下定义的任何处理器使用(即任何后代处理器)。
后代组中的变量会覆盖父组中的值。更具体地说,如果变量x在根组中声明并且也在进程组内声明,则进程组内的组件将使用进程组中x定义的值。
例如,除了putfile_dir根进程组中存在的变量之外,假设putfile_dir在进程组A中创建了另一个变量。如果进程组A中的一个组件引用putfile_dir,则将列出这两个变量,但是putfile_dir根组中的变量将是有一个删除线表明被覆盖:
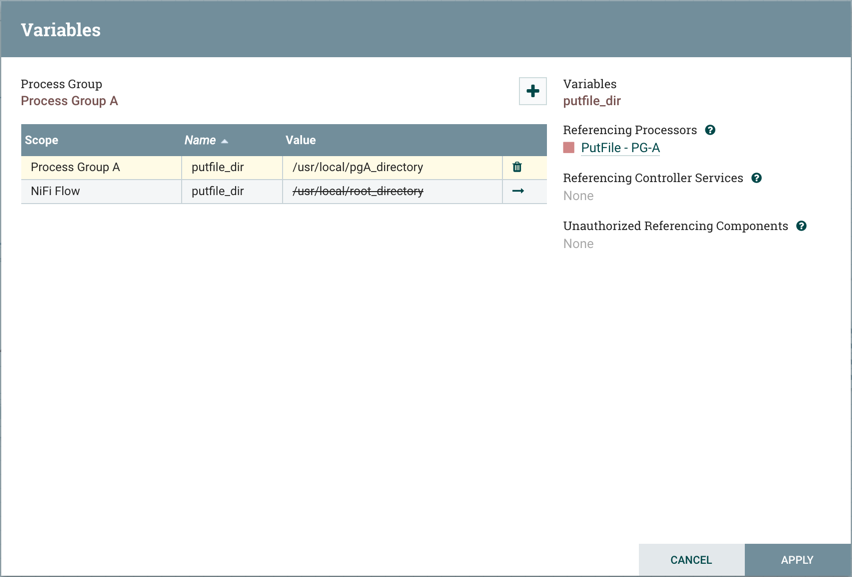
只能为其创建的进程组修改变量,该变量列在变量窗口的顶部。要修改在不同进程组中定义的变量,请选择该变量行中的箭头图标:
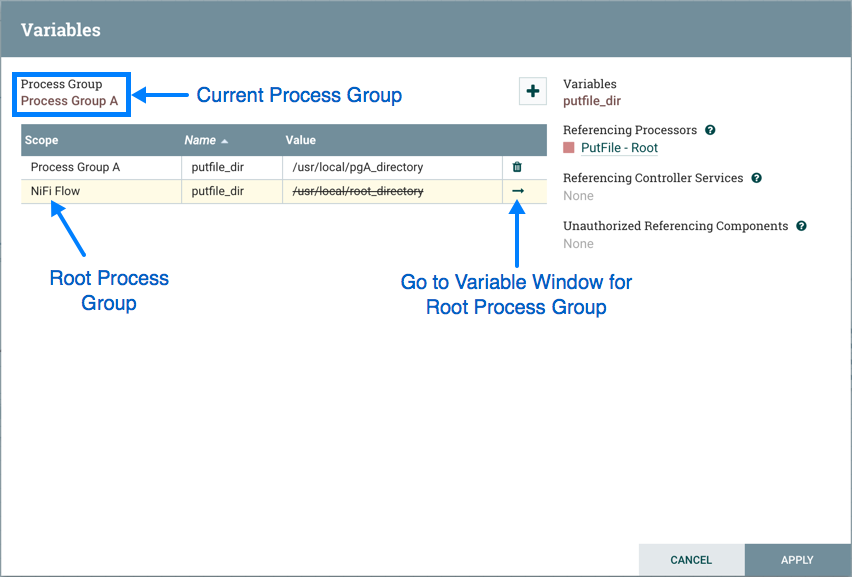
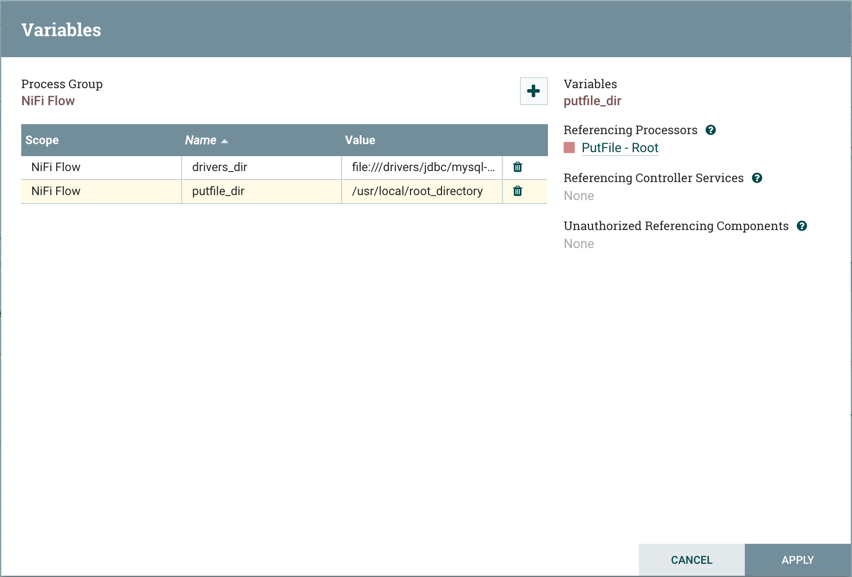
这将导航到该进程组的Variables窗口:
变量权限
变量权限仅基于相应进程组上配置的权限。
例如,如果用户无权查看进程组,则无法查看该进程组的变量窗口:
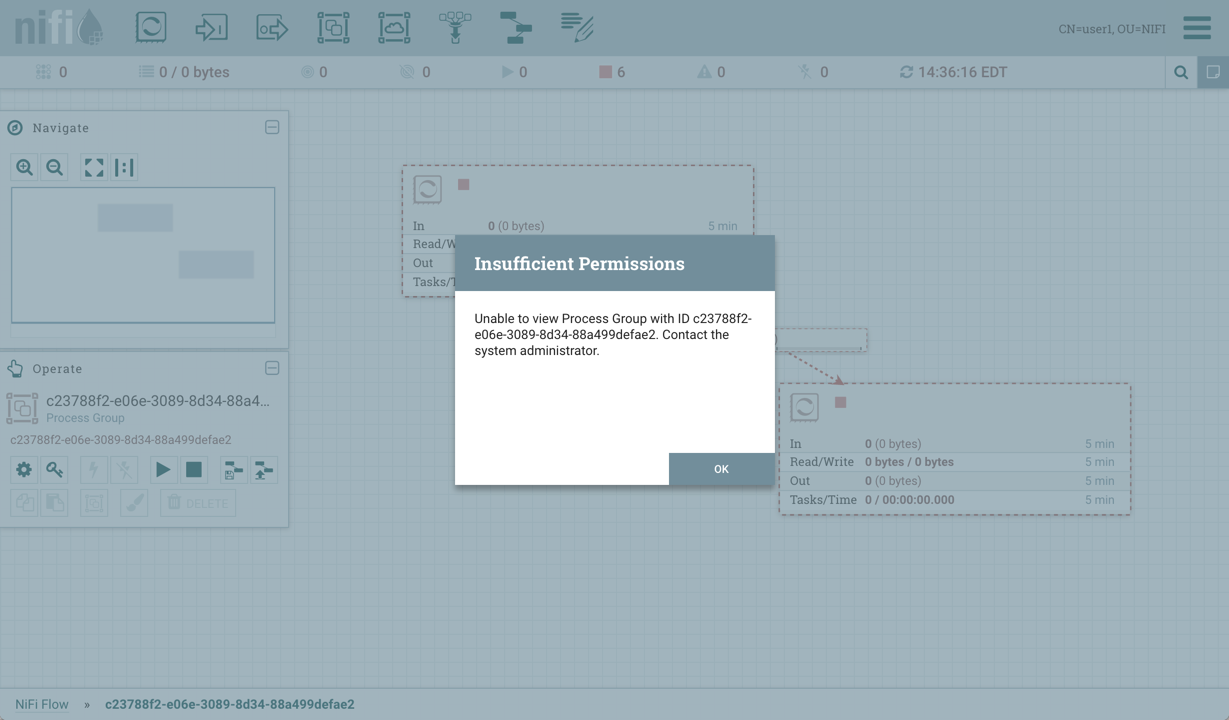
如果用户有权查看流程组但无权修改流程组,则可以查看变量但不能修改变量。
有关如何管理组件权限的信息,请参阅系统管理员指南中的访问策略部分。
引用控制器服务
除了Referencing Processors之外,Variables窗口还显示Referencing Controller Services:
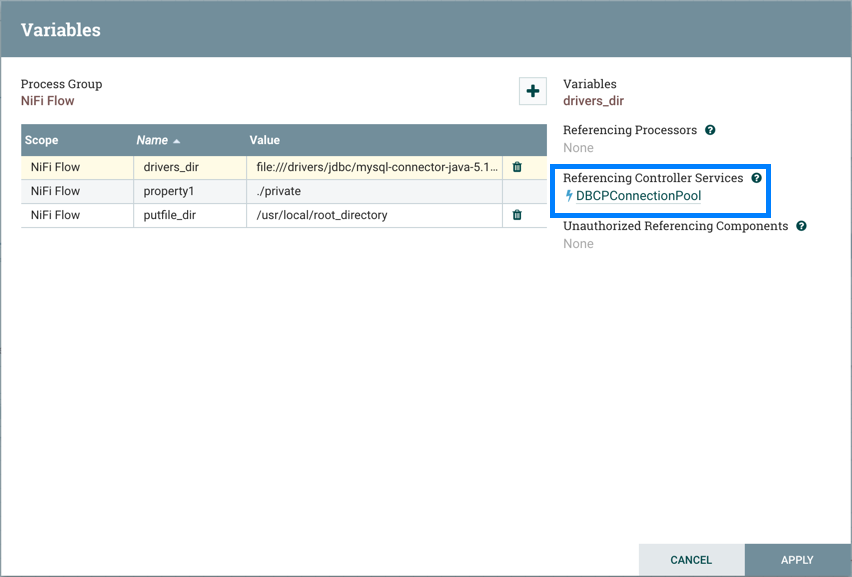
选择控制器服务的名称将导航到该控制器服务的配置窗口中:
未经授权的引用组件
如果未向引用变量的组件提供查看或修改权限,则组件的UUID将显示在变量窗口中:
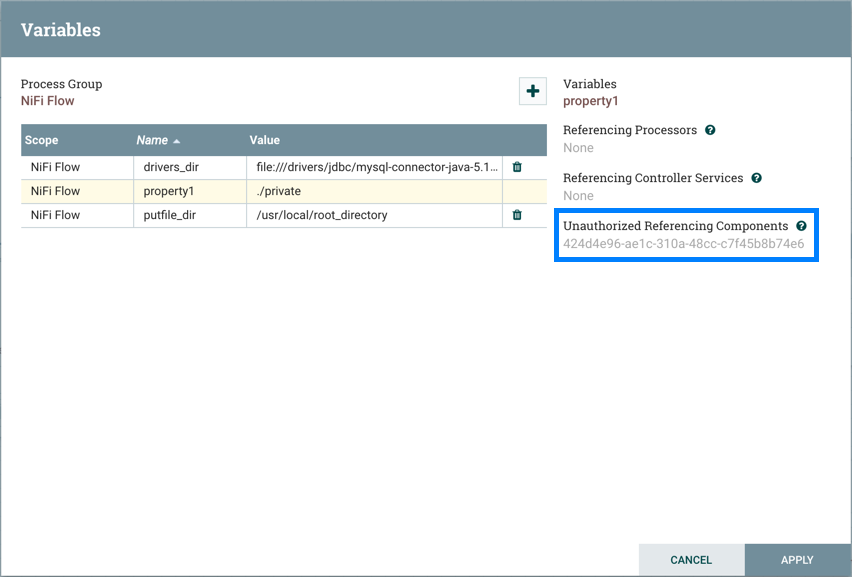
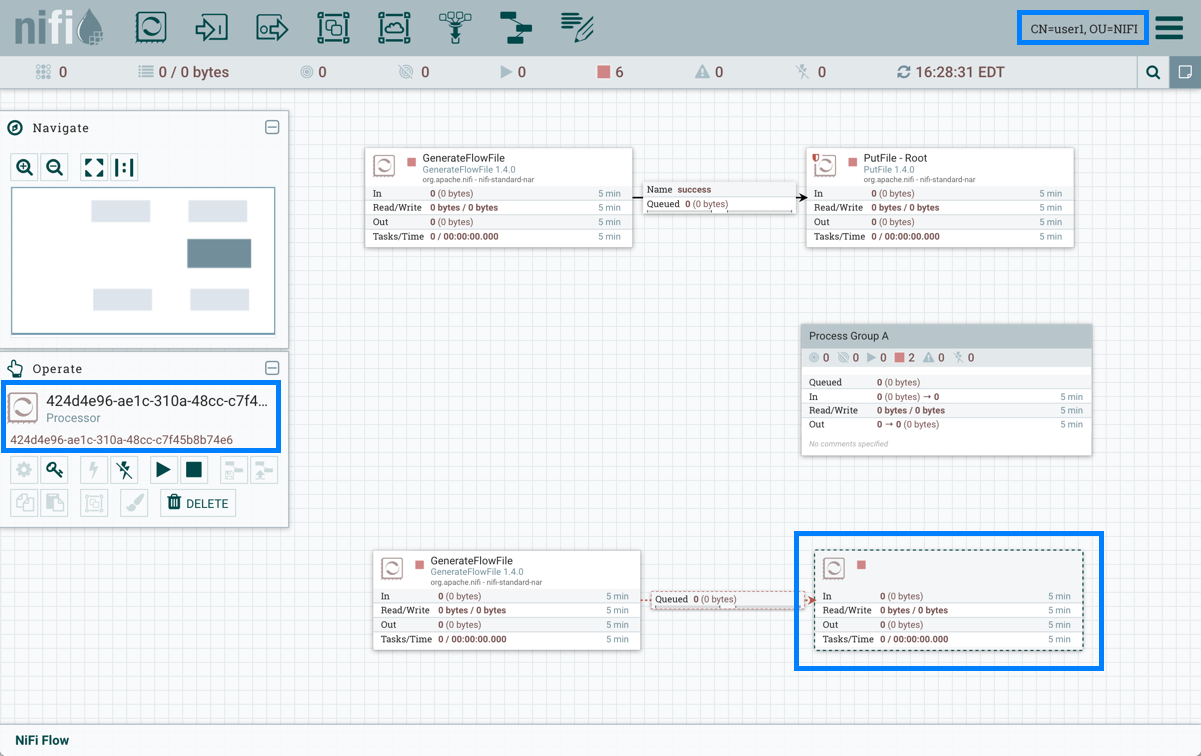
在上面的示例中,变量property1由user1无法查看的处理器引用:
通过nifi.properties引用自定义属性
识别一组或多组键值对,并将它们提供给系统管理员。
添加新的自定义属性后,请确保使用自定义属性位置更新nifi.properties文件中的nifi.variable.registry.properties 字段。
必须重新启动NiFi才能获取这些更新。 有关详细信息,请参阅系统管理员指南中的自定义属性部分。
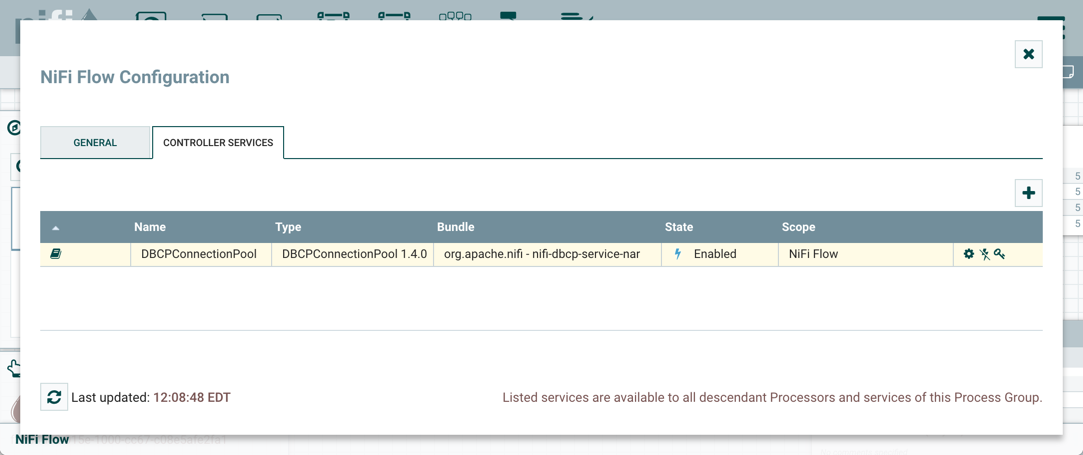
控制器服务
Controller Services是共享服务,可供给报告任务,处理器和其他服务使用,以用于配置或任务执行。
 控制器级别定义的控制器服务仅限于报告任务和其中定义的其他服务。必须在将要使用它们的根进程组或子进程组的配置中定义控制器服务。
控制器级别定义的控制器服务仅限于报告任务和其中定义的其他服务。必须在将要使用它们的根进程组或子进程组的配置中定义控制器服务。
如果您的NiFi实例受到保护,您查看和添加Controller Services的能力取决于分配给您的权限。如果您无权访问一个或多个Controller Services,则无法在UI中查看或访问它。可以在全局或特定于Controller Service的基础上分配访问权限(有关更多信息,请参阅访问具有多租户授权的UI)。
为报告任务添加控制器服务
要为报告任务添加控制器服务,请从全局菜单中选择控制器设置。
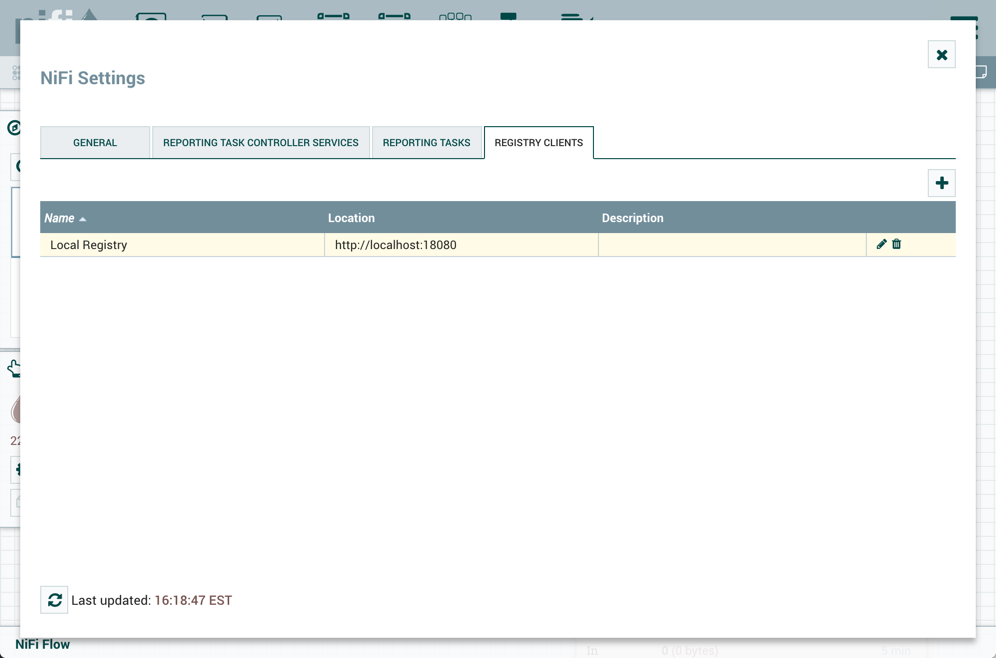
这将显示NiFi设置窗口。该窗口有四个选项卡:常规(General),报告任务控制器服务(Reporting Task Controller Services),报告任务(Reporting Tasks)和注册表客户端(Registry Clients)。常规选项卡提供实例的总体最大线程数的设置。
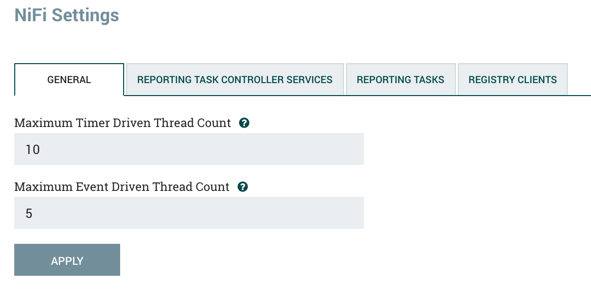
常规选项卡右侧是报告任务控制器服务选项卡。在此选项卡中,DFM可以单击右上角的+按钮以创建新的Controller Service。

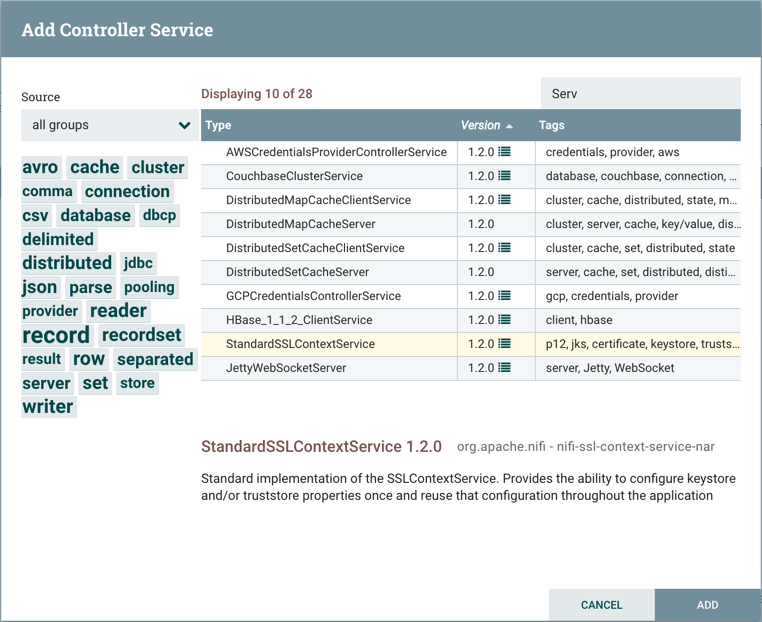
添加控制器服务窗口打开。此窗口类似于添加处理器窗口。它提供了右侧可用的Controller Services列表和标签云,显示了左侧用于Controller Services的最常见类别标签。DFM可以单击标签云中的任何标签,以便将Controller Services列表缩小到适合所需类别的那些。DFM还可以使用窗口右上角的过滤器字段来搜索所需的控制器服务,或使用左上角的源(Source)下拉列表按创建它们的组筛选列表。从列表中选择Controller Service后,DFM可以在下面看到该服务的描述。选择所需的控制器服务,然后单击添加按钮,或者双击要添加的服务名称即可。
添加控制器服务后,可以通过单击Configure最右侧列中的按钮进行配置。此列中的其他按钮包括Enable,Remove和Access Policies。

您可以通过单击左侧列中的Usage和Alerts按钮来获取有关Controller Services的信息。
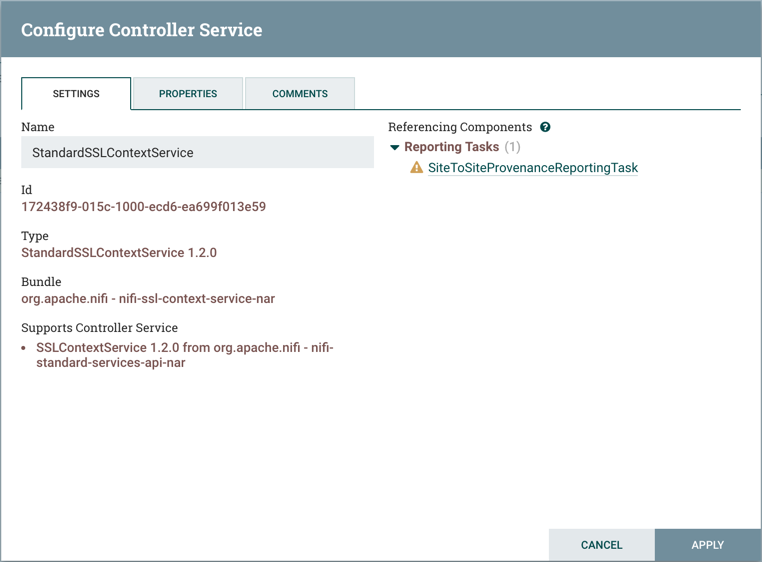
当DFM单击该Configure按钮时,将打开配置控制器服务窗口。它有三个选项卡:设置,属性和注释。此窗口类似于配置处理器窗口。设置选项卡为DFM提供了一个位置,以便为Controller Service提供唯一的名称。它还列出了服务的UUID,类型,捆绑和支持信息,并提供了引用该服务的其他组件(报告任务或其他控制器服务)的列表。
属性选项卡列出了适用于特定控制器服务的各种属性。与配置处理器一样,DFM可以将鼠标悬停在问号图标上以查看有关每个属性的更多信息。
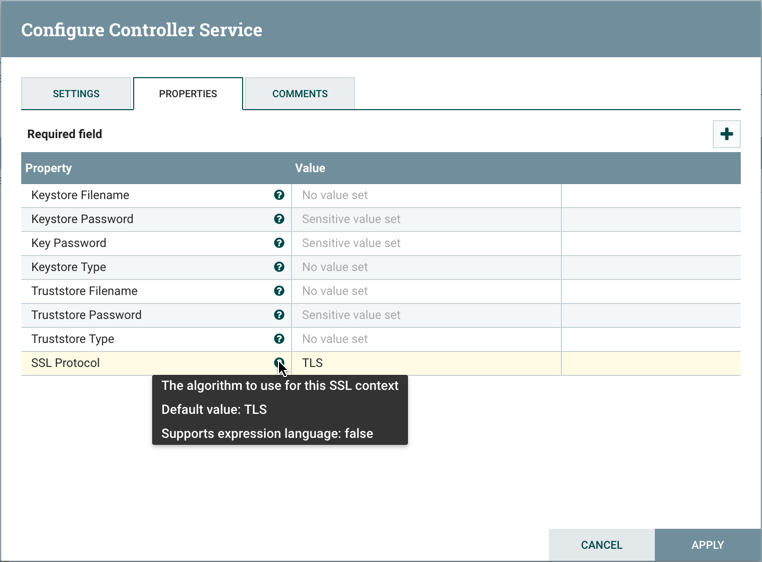
注释选项卡只是一个开放文本,其中可能包含DFM对有关服务的注释。配置Controller Service后,单击Apply按钮以应用配置并关闭窗口,或单击Cancel按钮取消更改并关闭窗口。
为数据流添加控制器服务
要为数据流添加控制器服务,可以右键单击进程组并选择配置,或单击操作选项板中的配置。
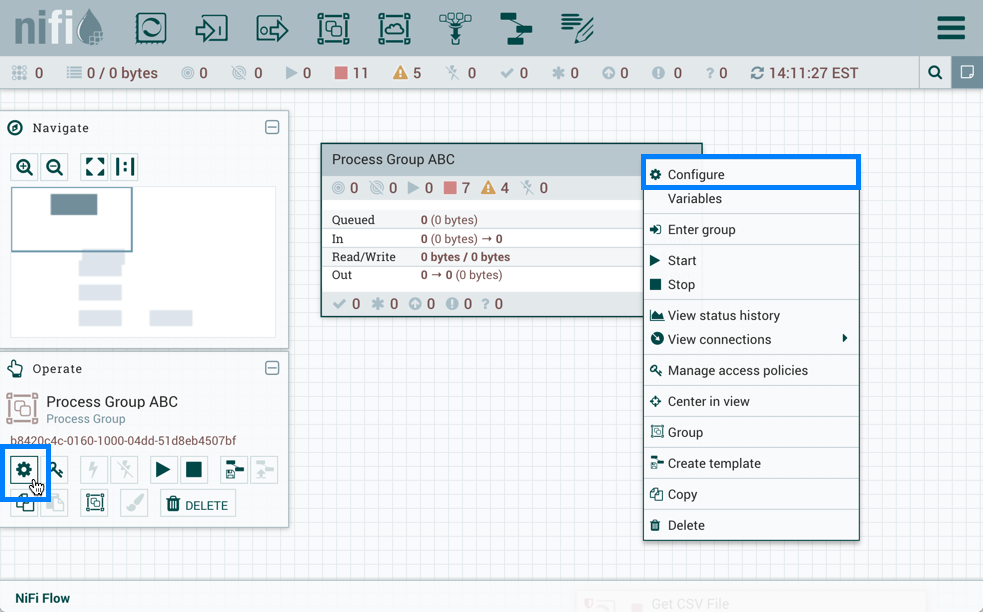
在画布上单击操作选项板中的配置时,如果未在画布上选择任何内容,则为根进程组添加控制器服务。然后,该控制器服务可用于数据流中的所有嵌套进程组。在画布上选择进程组,然后从操作选项板或进程组上下文菜单中单击配置时,该服务将可用于该进程组及以下中定义的所有处理器和控制器服务。

使用以下步骤添加Controller Service:
1、单击配置,可以从操作选项板或进程组上下文菜单中单击配置。这将显示进程组配置窗口。该窗口有两个选项卡:常规和控制器服务。常规选项卡用于与有关进程组的常规信息有关的设置。例如,如果配置根进程组,DFM可以为整个数据流提供唯一的名称,以及描述流的注释(注意:此信息对于远程连接到此实例的任何其他NiFi实例是可见的(使用远程进程组,又名,站点到站点))。
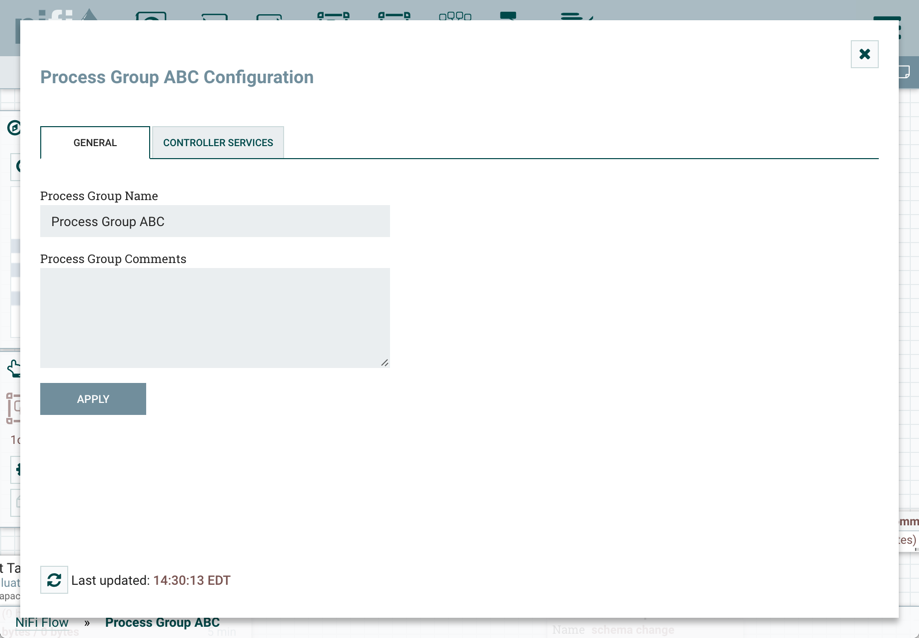
2、从Process Group Configuration页面中,选择Controller Services选项卡。
3、单击+按钮以显示添加控制器服务对话框。
4、选择所需的Controller Service,然后单击添加。
5、单击 右侧列中的配置图标,配置Controller Service。
右侧列中的配置图标,配置Controller Service。
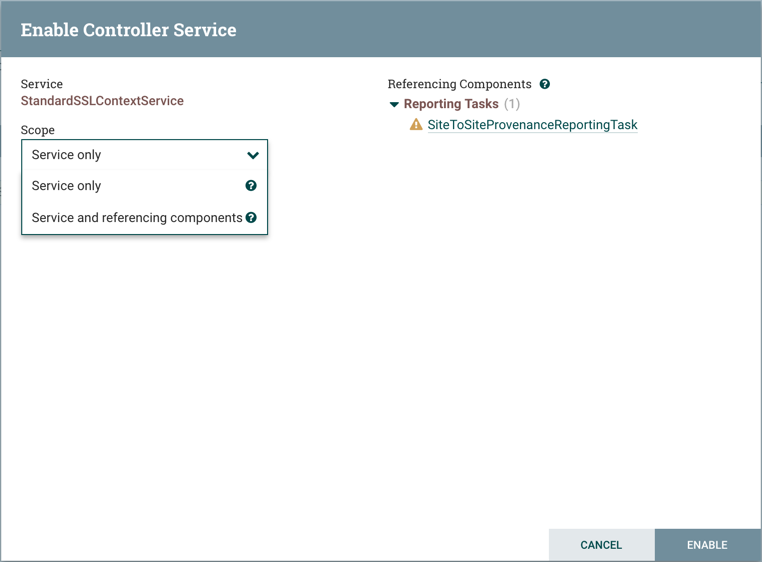
启用/禁用控制器服务
配置Controller Service后,必须启用它才能运行。使用控制器服务选项卡的最右侧列中的Enable按钮( )来执行此操作。为了修改现有或正在运行的控制器服务,DFM需要停止或禁用它(以及所有引用此Controller Service的组件)。使用Disable按钮(
)来执行此操作。为了修改现有或正在运行的控制器服务,DFM需要停止或禁用它(以及所有引用此Controller Service的组件)。使用Disable按钮( )执行此操作。DFM可以在禁用相关控制器服务时停止/禁用哪些依赖此控制器服务的组件,而不必搜寻引用该控制器服务的每个组件。启用控制器服务时,DFM可以选择启动或启用控制器服务和所有引用它的组件,也可以仅启动或启用控制器服务本身。
)执行此操作。DFM可以在禁用相关控制器服务时停止/禁用哪些依赖此控制器服务的组件,而不必搜寻引用该控制器服务的每个组件。启用控制器服务时,DFM可以选择启动或启用控制器服务和所有引用它的组件,也可以仅启动或启用控制器服务本身。
任务监控(Reporting Tasks)
报告任务在后台运行,以提供有关NiFi实例中发生情况的统计报告。DFM添加和配置报告任务,类似于Controller Services的过程。要添加报告任务,请从全局菜单中选择控制器设置。
这将显示NiFi设置窗口。选择报告任务选项卡,然后单击右上角的+按钮以创建新的报告任务。
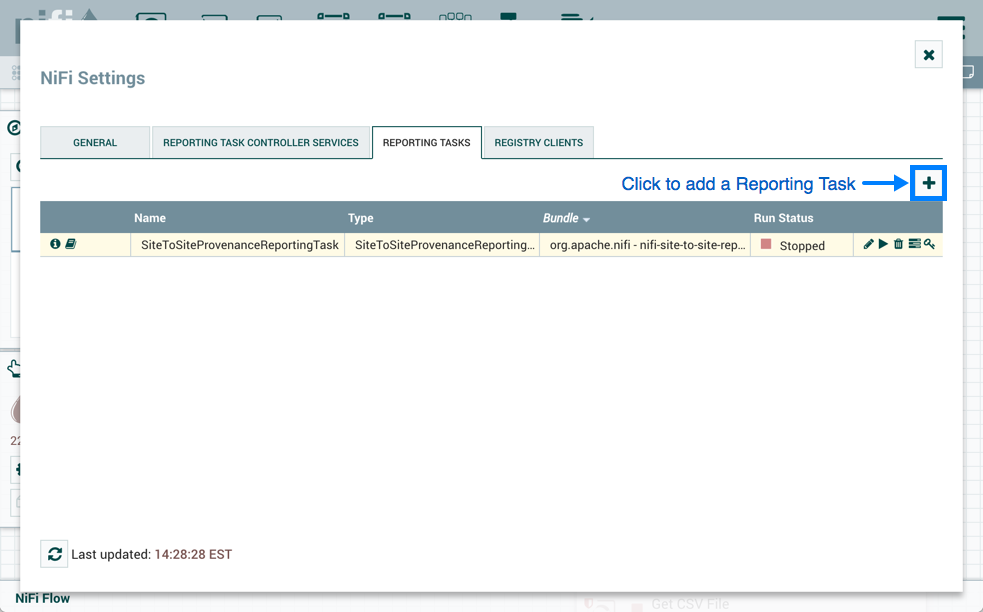
打开添加报告任务窗口。此窗口类似于添加处理器窗口。它提供了右侧可用报告任务的列表和标签云,显示了左侧用于报告任务的最常见类别标签。DFM可以单击标签云中的任何标签,以便将报告任务列表缩小到适合所需类别的那些。DFM还可以使用窗口右上角的过滤器字段来搜索所需的报告任务,或使用左上角的源(source)下拉列表按创建它们的组筛选列表。从列表中选择报告任务后,DFM可以在下面看到该任务的描述。选择所需的报告任务,然后单击添加,或者双击要添加的服务名称即可。
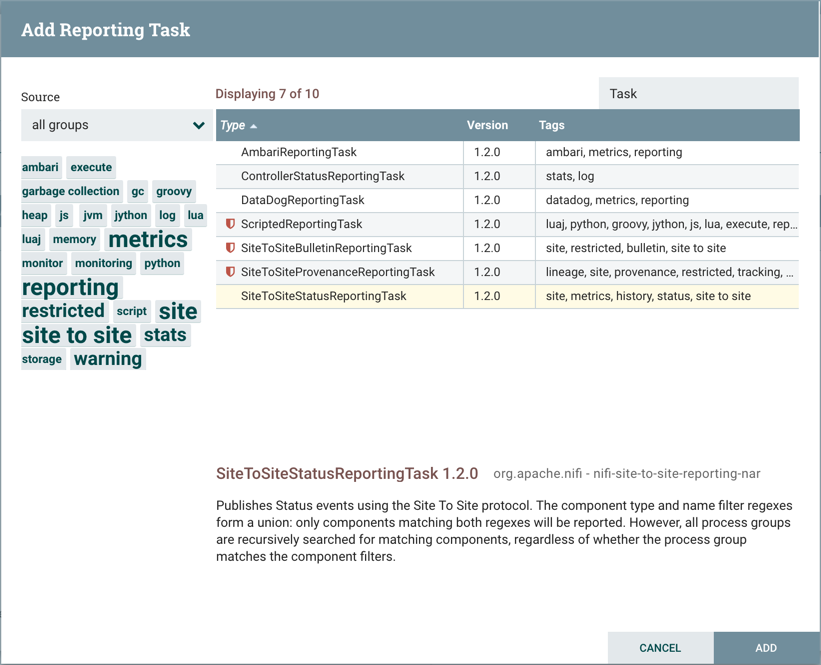
添加报告任务后,DFM可以通过单击Edit最右侧列中的按钮对其进行配置。在此列中的其他按钮包括Start,Remove,State和Access Policies。
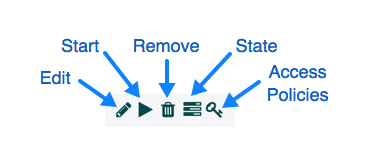
您可以获取有关通过点击报告任务信息View Details,Usage以及Alerts在左侧栏中的按钮。
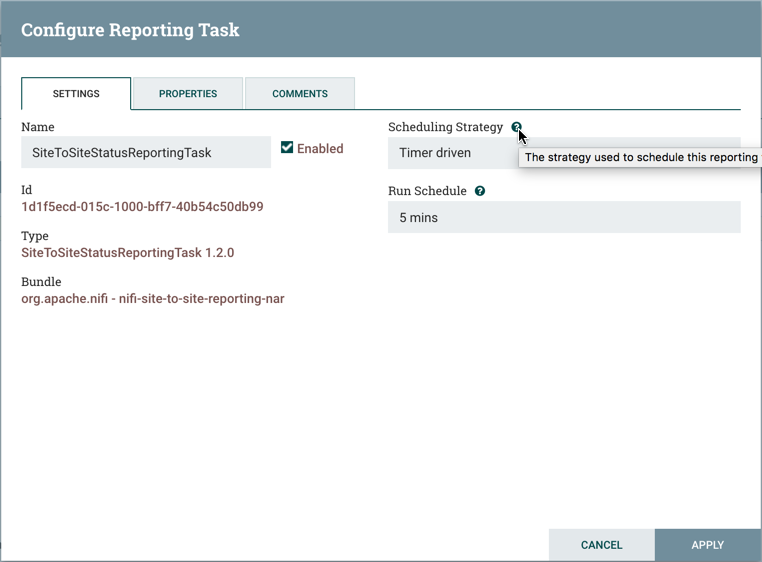
当DFM单击该Edit按钮时,将打开配置报告任务窗口。它有三个选项卡:设置,属性和注释。此窗口类似于配置处理器窗口。设置选项卡为DFM提供了一个位置,以便为报告任务提供唯一的名称(如果需要)。它还列出了任务的UUID,Type和Bundle信息,并提供了任务的Scheduling Strategy和Run Schedule的设置(类似于处理器中的相同设置)。DFM可以将鼠标悬停在问号图标上以查看有关每个设置的更多信息。
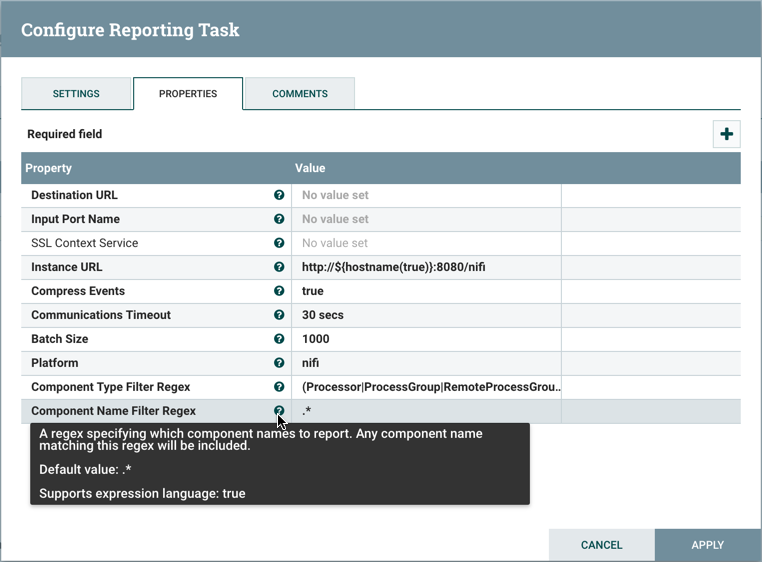
属性选项卡列出了可为任务配置的各种属性。DFM可以将鼠标悬停在问号图标上以查看有关每个属性的更多信息。
注释选项卡只是一个开放文本字段,其中DFM可能包含有关任务的注释。配置报告任务后,单击Apply按钮以应用配置并关闭窗口,或单击Cancel按钮取消更改并关闭窗口。
如果要运行"报告任务",请单击Start按钮
连接组件(Connecting Components)
将处理器和其他组件添加到画布并进行配置后,下一步是将它们彼此连接,以便让NiFi知道在处理完每个FlowFile后如何传输数据。这是通过在每个组件之间创建连接来实现的。当用户将鼠标悬停在组件的中心上时,会出现一个新的连接图标
用户将连接图标从一个组件拖动到另一个组件当用户释放鼠标时,会出现创建连接对话框。该对话框包含两个选项卡:详细信息和设置。它们将在下面详细讨论。请注意,可以绘制在同一处理器上循环的连接。如果DFM希望处理器在失败关系时尝试重新处理FlowFiles,这将非常有用。要创建这种类型的循环连接,只需将连接图标拖离,然后再返回到同一处理器,然后释放鼠标,出现相同的创建连接对话框。
细节
创建连接对话框的详细信息选项卡提供有关上下游组件的信息,包括组件名称,组件类型和组件所在的进程组:
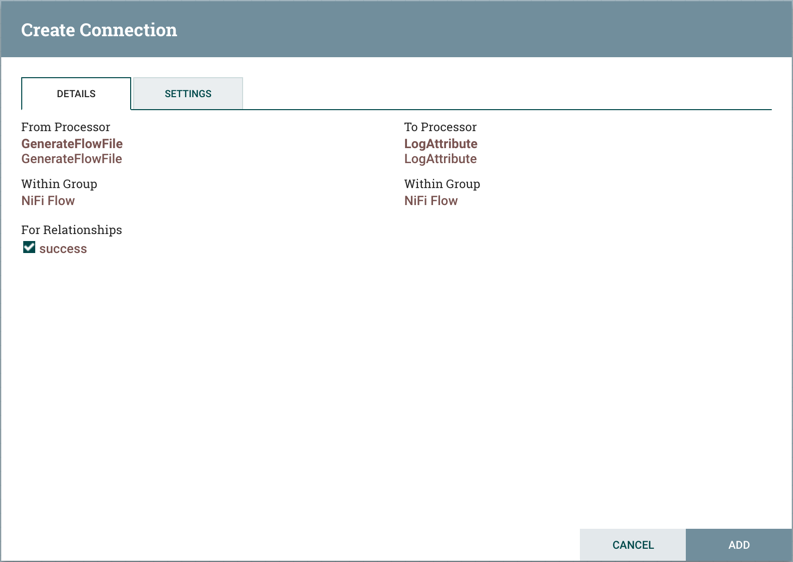
此外,此选项卡还提供了选择此Connection中应包含哪些关系的功能。必须至少选择一个关系。如果只有一个关系可用,则会自动选择它。
如果使用相同的关系添加多个Connections,则路由到该关系的任何FlowFile将自动clone,并且将向每个Connections发送一个副本。
设置
设置选项卡提供配置连接名称,FlowFile到期,背压阈值,负载平衡策略和优先级的功能:
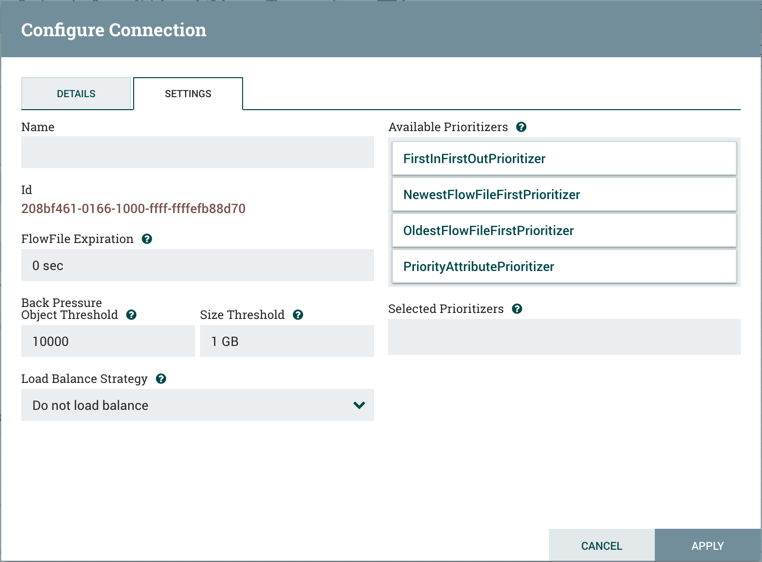
连接名称是可选的。如果未指定,则为Connection显示的名称将是Connection的活动关系的名称。
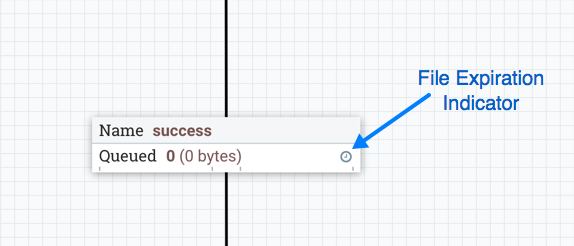
FlowFile到期
FlowFile到期是一个概念,通过该概念可以自动从流中删除无法及时处理的数据。在这种情况下,到期可以与优先级排序器一起使用,以确保首先处理最高优先级数据,然后可以丢弃在特定时间段(例如,一小时)内无法处理的任何内容。到期时间基于数据进入NiFi实例的时间。换句话说,如果给定连接上的文件到期时间设置为1小时,并且已经在NiFi实例中存在一小时的文件到达该连接,则该文件将过期。默认值为0 sec表示数据永不过期。当设置了0秒以外的文件到期时,连接标签上会出现一个小时钟图标,因此在查看画布上的流时,DFM可以一目了然地看到它。
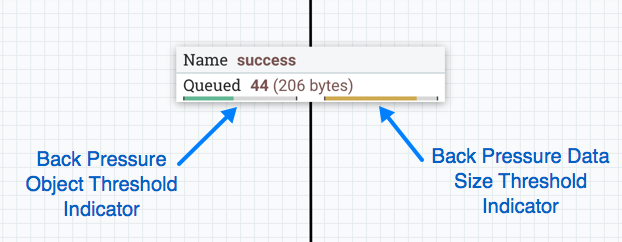
背压
NiFi为背压提供两种配置元素。这些阈值表示允许在队列中存在多少数据。这允许系统避免数据溢出。提供的第一个选项是Back pressure object threshold(背压对象阈值)。这是在应用背压之前可以在队列中的FlowFiles的数量。第二个配置选项是Back pressure data size threshold(背压数据大小阈值)。这指定了在应用反压之前应排队的最大数据量(大小)。通过输入数字后跟数据大小(B对于字节,KB对于千字节,MB对于兆字节,GB对于千兆字节或TB对于太字节)来配置此值。
默认情况下,添加的每个新连接都将具有默认的背压对象阈值10000 objects和背压数据大小阈值1 GB。可以通过修改nifi.properties文件中的相应属性来更改这些默认值。
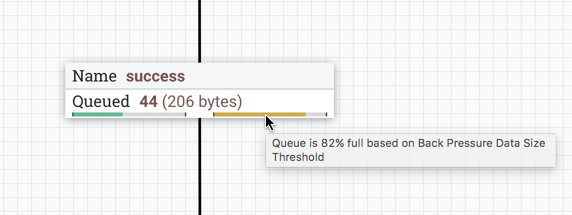
启用背压时,连接标签上会出现小进度条,因此在查看画布上的流时,DFM可以一目了然地看到它。进度条根据队列百分比更改颜色:绿色(0-60%),黄色(61-85%)和红色(86-100%)。
将鼠标悬停在条形图上会显示确切的百分比。
队列完全填满后,Connection将以红色突出显示。

负载均衡
负载平衡策略
为了在集群中的节点之间分配流中的数据,NiFi提供以下负载平衡策略:
不负载平衡:不在集群中的节点之间平衡FlowFile。这是默认值。
按属性划分:根据用户指定的FlowFile属性的值确定将给定FlowFile发送到哪个节点。具有相同Attribute值的所有FlowFile将发送到集群中的同一节点。如果目标节点与集群断开连接或无法通信,则数据不会故障转移到另一个节点。数据将排队,等待节点再次可用。此外,如果节点加入或离开集群需要重新平衡数据,则应用一致性散列以避免必须重新分发所有数据。
循环:FlowFiles将以循环方式分发到集群中的节点。如果节点与集群断开连接或无法与节点通信,则排队等待该节点的数据将自动重新分发到另一个节点。
单个节点:所有FlowFiles将发送到集群中的单个节点。它们被发送到哪个节点是不可配置的。如果节点与集群断开连接或无法与节点通信,则排队等待该节点的数据将保持排队,直到该节点再次可用。
除UI设置外,还有与负载平衡相关的集群节点属性,还必须在nifi.properties中进行配置。
NiFi会在重新启动时持久保存集群中的节点。这可以防止在所有节点都已连接之前重新分配数据。如果集群已关闭且不打算重新启动节点,则用户有责任通过UI中的集群对话框从集群中删除该节点(有关详细信息,请参阅管理节点)。
负载平衡压缩
选择负载平衡策略后,用户可以配置在集群中的节点之间传输时是否应压缩数据。
可以使用以下压缩选项:
不压缩:FlowFiles不会被压缩。这是默认值。
仅压缩属性:将压缩FlowFile属性,但不会压缩FlowFile内容。
压缩属性和内容:将压缩FlowFile属性和内容。
负载平衡指示器
为连接实施负载平衡策略后,连接负载平衡图标上 将显示负载平衡指示符:
将显示负载平衡指示符:
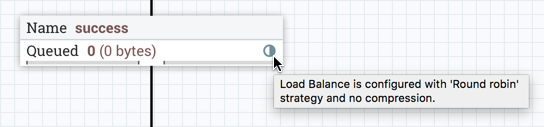
将鼠标悬停在该图标上将显示连接的负载平衡策略和压缩配置。此状态下的图标还表示连接中的所有数据都已在集群中分布。
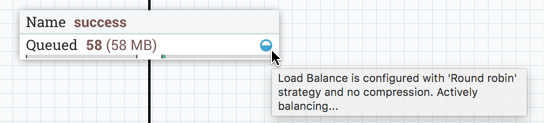
当在集群中的节点之间主动传输数据时,负载平衡指示器将更改方向和颜色:
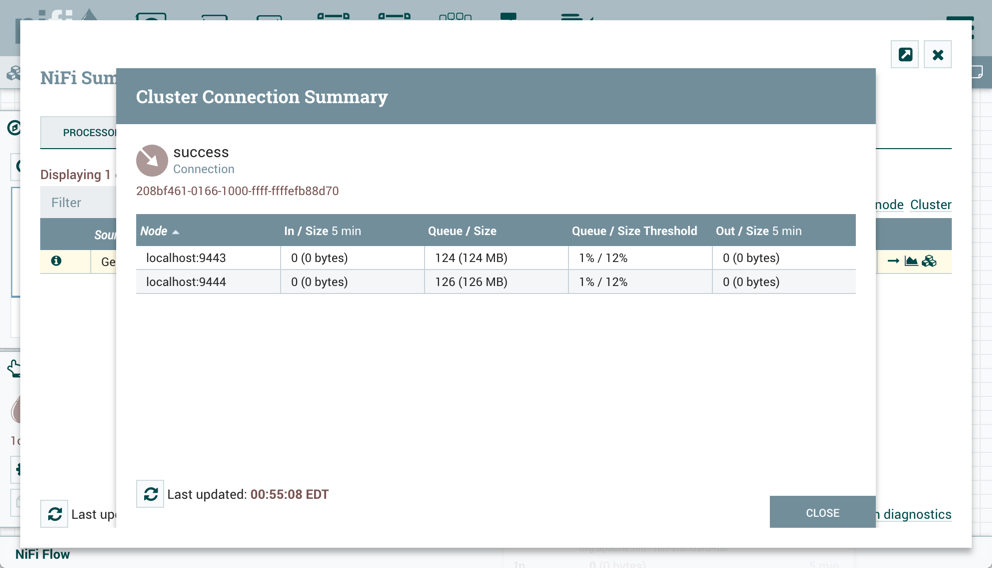
集群连接摘要
要查看在集群节点之间分配数据的位置,请从全局菜单中选择摘要。然后选择Connections选项卡和View Connection Details:
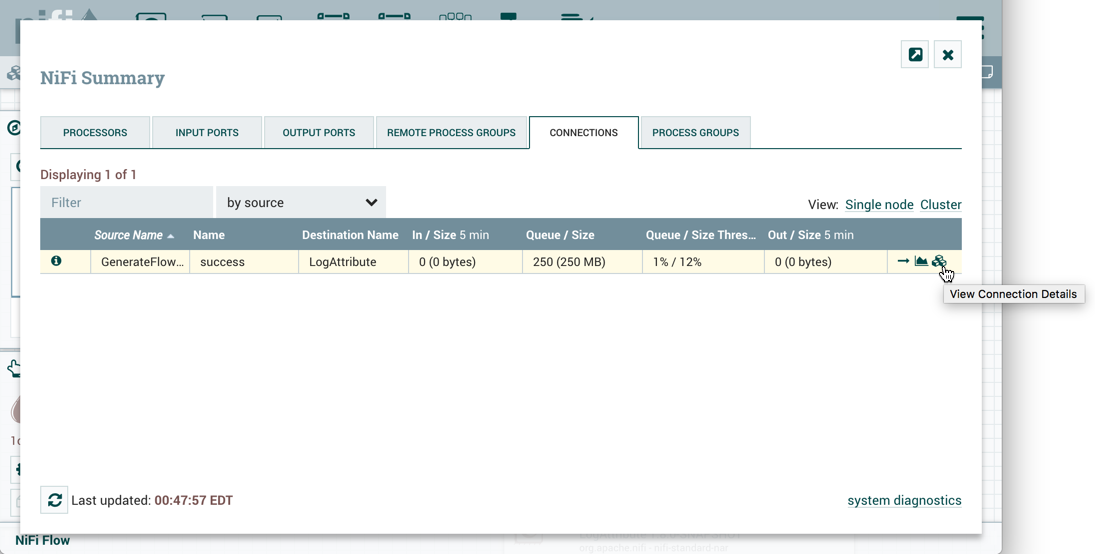
这将打开集群连接摘要对话框,该对话框显示集群中每个节点上的数据:
优先级
选项卡的右侧提供了对队列中数据进行优先级排序的功能,以便首先处理更高优先级的数据。优先级可以从顶部(可用的优先级排序器)拖动到底部(选择的优先级排序器)。可以选择多个优先级排序器。位于所选优先级列表顶部的优先级排序是最高优先级。如果两个FlowFiles根据此优先级排序器具有相同的值,则第二个优先级排序器将确定首先处理哪个FlowFile,依此类推。如果不再需要优先级排序器,则可以将其从选定的优先级排序器列表拖动到可用的优先级排序器列表。
可以使用以下优先顺序:
FirstInFirstOutPrioritizer:给定两个FlowFiles,首先处理首先到达连接的FlowFiles。
NewestFlowFileFirstPrioritizer:给定两个FlowFiles,将首先处理数据流中最新的FlowFiles。
OldestFlowFileFirstPrioritizer:给定两个FlowFiles,将首先处理数据流中最旧的FlowFiles。这是在没有选择优先级的情况下使用的默认方案。
PriorityAttributePrioritizer:给定两个FlowFiles,将提取名为priority的属性。将首先处理具有最低优先级值的那个。
请注意,应使用UpdateAttribute处理器在FlowFiles到达具有此优先级设置的连接之前将priority属性添加到FlowFiles。
如果只有一个具有该属性,它将首先出现。
priority属性的值可以是字母数字,其中"a"将出现在"z"之前,"1"出现在"9"之前
如果priority属性无法解析为long型数字,则将使用unicode字符串排序。例如:"99"和"100"将被排序,因此带有"99"的流文件首先出现,但"A-99"和"A-100"将排序,因此带有"A-100"的流文件首先出现。
配置了负载平衡策略后,连接除了本地队列外,每个节点都有一个队列。优先排序器将独立地对每个队列中的数据进行排序。
更改配置和上下文菜单选项
在两个组件之间建立连接之后,可以更改连接的配置,并且可以将连接移动到新目的地;但是,必须先停止连接任一侧的处理器,然后才能进行配置或目标更改。
要更改连接的配置或以其他方式与连接交互,请右键单击连接以打开连接上下文菜单。
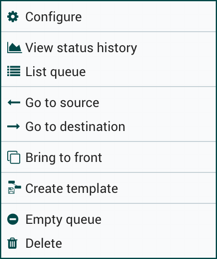
可以使用以下选项:
Configure:此选项允许用户更改连接的配置。
View status history:此选项打开连接统计信息随时间的图形表示。
List queue:此选项列出可能正在等待处理的FlowFiles队列。
Go to source:如果画布上连接的源组件和目标组件之间有很长的距离,则此选项很有用。通过单击此选项,画布视图将跳转到连接源。
Go to destination:与"转到源"选项类似,此选项将视图更改为画布上的目标组件,如果两个连接的组件之间存在较长距离,则此选项可能很有用。
Bring to front:如果其他东西(例如另一个连接)与其重叠,则此选项将连接带到画布的前面。
Empty queue:此选项允许DFM清除可能正在等待处理的FlowFiles队列。当DFM不关心从队列中删除数据时,此选项在测试期间特别有用。选择此选项后,用户必须确认是否要删除队列中的数据。
Delete:此选项允许DFM删除两个组件之间的连接。请注意,必须先停止连接两侧的组件,并且连接必须为空才能删除。
弯曲连接
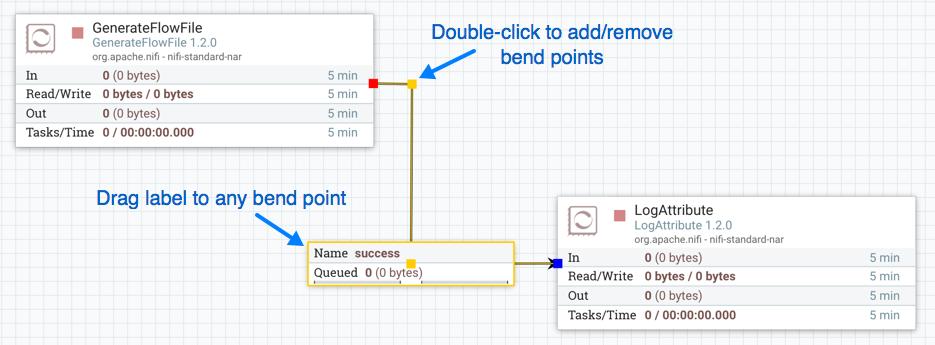
要向现有连接添加弯曲点(或弯头),只需双击要弯曲点所在位置的连接即可。然后,您可以使用鼠标抓住弯曲点并拖动它,以便以所需的方式弯曲连接。您可以根据需要添加任意数量的弯曲点。您还可以使用鼠标将连接上的标签拖动并移动到任何现有折弯点。要删除折弯点,只需再次双击即可。
处理器验证
在尝试启动处理器之前,确保处理器的配置有效非常重要。状态指示器显示在处理器的左上角。如果处理器无效,指示器将显示黄色警告指示器,并带有感叹号,表示存在问题:
在这种情况下,使用鼠标悬停在指示器图标上将提供工具提示,显示处理器的所有验证错误。一旦解决了所有验证错误,状态指示器将变为Stop图标,表示处理器有效并准备启动但当前未运行:
站点到站点(s2s)
当从一个NiFi实例向另一个实例发送数据时,可以使用许多不同的协议。但是,首选协议是NiFi站点到站点协议。站点到站点可以轻松安全高效地将数据传输到一个NiFi实例中的节点或从一个NiFi实例中的节点或数据生成应用程序传输到另一个NiFi实例或其他消费应用程序中的节点。
使用站点到站点提供以下好处:
易于配置
- 输入远程NiFi实例的URL后,将自动发现可用端口(端点)并在下拉列表中提供
安全
可扩展
- 随着远程集群中的节点发生更改,将自动检测这些更改,并在集群中的所有节点上扩展数据。
高效
- 站点到站点允许立即发送批量的FlowFiles,以避免建立连接和在对等点之间进行多次往返请求的开销。
可靠
- 校验由发送方和接收方自动生成,并在数据传输后进行比较,以确保没有发生损坏。如果校验和不匹配,则会取消交易并再次尝试。
自动加载平衡
- 当节点联机或退出远程集群,或节点的负载变得更重或更轻时,将自动调整定向到该节点的数据量。
FlowFiles保留属性
- 当通过此协议传输FlowFile时,所有FlowFile的属性都会随之自动传输。这在许多情况下是非常有利的,因为由一个NiFi实例确定的所有上下文和丰富随数据传播,使得数据易于路由并且允许用户容易地检查数据。
适应性强
- 随着新技术和新想法的出现,处理站点到站点通信的协议能够随之改变。当与远程NiFi实例建立连接时,执行握手以协商将使用哪种协议和协议版本。这允许添加新功能,同时仍保持与所有旧实例的向后兼容性。此外,如果在协议中发现漏洞或缺陷,它允许更新NiFi版本的禁止通过受损版本的协议进行通信。
站点到站点是在两个NiFi实例之间传输数据的协议。两端可以是独立的NiFi或NiFi集群。在本节中,NiFi实例启动通信称为站点到站点客户端NiFi实例,另一端启动为站点到站点服务器NiFi实例,以阐明每个NiFi实例所需的配置。
NiFi实例可以是站点到站点协议的客户端和服务器,但是,它只能是特定站点到站点通信中的客户端或服务器。例如,如果有三个NiFi实例A,B和C.A将数据推送到B,B从C拉取数据。那么B不仅是A和B之间通信的服务器,还是B和C中的客户端。
在数据处理过程中知晓哪个NiFi实例将是客户端或服务器并相应地配置每个实例是非常重要的。以下是基于数据流方向在哪一方运行的组件的摘要:
推送:客户端将数据发送到远程进程组,服务器通过输入端口接收数据
拉:客户端从远程进程组接收数据,服务器通过输出端口发送数据
配置站点到站点客户端NiFi实例
远程进程组:为了通过站点到站点与远程NiFi实例进行通信,只需将远程进程组拖到画布上,然后输入远程NiFi实例的URL(有关远程进程组组件的更多信息) ,请参阅 本指南的远程进程组传输部分。)URL与用于转到该实例的用户界面的URL相同。此时,您可以使用与将处理器连接到处理器或本地进程组的连接相同的方式将连接拖到远程进程组或从远程进程组拖出连接。拖动连接时,您将会选择要连接的端口。请注意,远程进程组最多可能需要一分钟才能确定哪些端口可用。
如果从远程进程组开始拖动连接,则显示的端口将是远程组的输出端口,因为这表示您将从远程实例中提取数据。如果连接在远程进程组上结束,则显示的端口将是远程组的输入端口,因为这意味着您将数据推送到远程实例。
如果远程实例配置为使用安全数据传输,您将只看到您有权与之通信的端口。有关配置NiFi以安全运行的信息,请参阅" 系统管理员指南"。
传输协议:在远程进程组创建或配置对话框中,您可以选择用于站点到站点通信的传输协议,如下图所示:
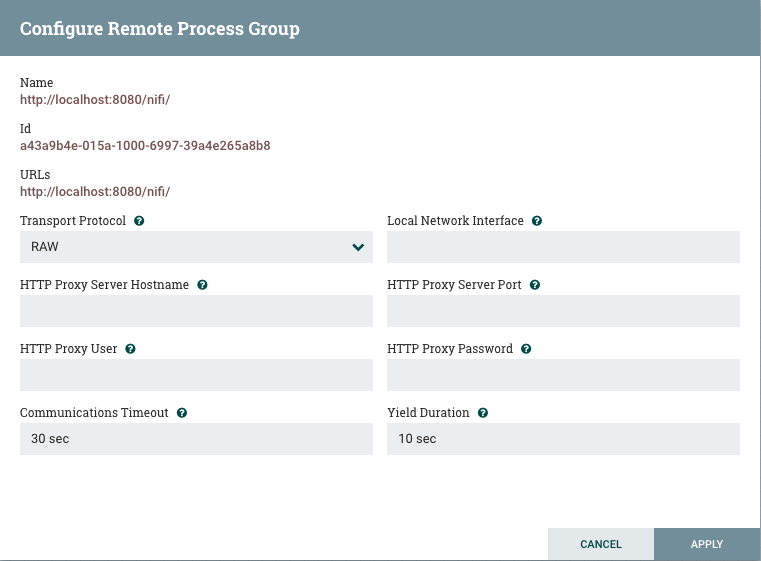
默认情况下,它设置为RAW,它使用专用端口,使用原始套接字通信。如果远程NiFi实例位于仅允许通过HTTP(S)协议进行访问或仅可从特定HTTP代理服务器访问的受限网络中,则HTTP传输协议特别有用。对于通过HTTP代理服务器进行访问,支持BASIC和DIGEST身份验证。
本地网络接口:在某些情况下,可能需要优先选择一个网络接口而不是另一个网络接口。例如,如果存在有线接口和无线接口,则有线接口可能是优选的。可以通过指定要在此框中使用的网络接口的名称来配置。如果输入的值无效,则远程进程组将无效,并且在解决此问题之前不会与其他NiFi实例通信。
配置站点到站点服务器NiFi实例
检索站点到站点详细信息:如果您的NiFi正在安全运行,为了让另一个NiFi实例从您的实例中检索信息,需要将其添加到Global Access"retrieve site-to-site details"策略。这将允许另一个实例查询您的实例以获取详细信息,例如名称,描述,可用对等体(集群时的节点),统计信息,OS端口信息以及可用的输入和输出端口。在安全实例中使用输入和输出端口需要额外的策略配置,如下所述。
输入端口:为了允许另一个NiFi实例将数据推送到本地实例,您只需将输入端口拖到画布的根进程组即可。输入端口名称后,它将添加到您的流程中。您现在可以右键单击"输入端口"并选择"配置",以便调整用于端口的名称和并发任务数。
如果将站点到站点配置为安全运行,则需要管理端口的"receive data via site-to-site"组件访问策略。只有已添加到策略的用户才能与端口通信。
输出端口:与输入端口类似,DataFlow Manager可以选择将输出端口添加到根进程组。输出端口允许授权的NiFi实例远程连接到您的实例并从输出端口提取数据。配置输出端口和管理端口的访问策略将再次允许DFM控制允许的并发任务数,以及授权哪些用户从正在配置的实例中提取数据。
除了NiFi的其他实例之外,一些其他应用程序可以使用站点到站点客户端来将数据推送到NiFi实例或从NiFi实例接收数据。例如,NiFi提供Apache Storm spout和Apache Spark Receiver,它们能够从NiFi的根组输出端口提取数据。
有关如何在NiFi实例上启用和配置站点到站点的信息,请参阅系统管理员指南的站点到站点属性部分 。
有关如何配置访问策略的信息,请参阅系统管理员指南的访问属性部分 。
数据流程示例
本节介绍了构建数据流所需的步骤。现在,把它们放在一起。以下示例数据流仅包含两个处理器:GenerateFlowFile和LogAttribute。这些处理器通常用于测试,但它们也可用于构建快速流程以用于演示目的,并查看NiFi的运行情况。
将GenerateFlowFile和LogAttribute处理器拖到画布并连接它们(使用上面提供的指南)后,按如下所示进行配置:
Generate FlowFile
在调度选项卡上,将运行计划设置为:5秒。请注意,GenerateFlowFile处理器可以非常快速地创建许多FlowFiles;这就是为什么设置运行计划很重要,这样这个流程就不会让NiFi运行的系统不堪重负。
在属性选项卡上,将文件大小设置为:10 KB
Log Attribute
在设置选项卡上的自动终止关系下,选中成功旁边的复选框。这将在此处理器成功处理后终止FlowFiles。
同样在设置选项卡上,将公告级别设置为"info"。这样,当数据流运行时,此处理器将显示公告图标(请参阅处理器的剖析),用户可以使用鼠标将鼠标悬停在其上以查看处理器正在记录的属性。
数据流应如下所示:

现在请参阅以下有关如何启动和停止数据流的部分。数据流运行时,请务必记下每个处理器正面显示的统计信息(请参阅处理器的剖析)。
DataFlow的命令和控制
将组件添加到NiFi画布时,它处于停止状态。为了使组件被触发,必须启动组件。一旦启动,组件可以随时停止。从停止状态,可以配置,启动或禁用该组件。
启动组件
要启动组件,必须满足以下条件:
组件的配置必须有效。
组件的所有已定义关系必须连接到另一个组件或自动终止。
必须停止该组件。
必须启用该组件。
该组件必须没有活动任务。有关活动任务的详细信息,请参阅"解剖......"段下的数据流的监控(处理器的剖析,进程组的解剖,远程进程组的解剖)。
可以通过选择要启动的所有组件然后单击操作选项板中的Start按钮( )或右键单击单个组件并从上下文菜单中选择启动选项来启动组件。
)或右键单击单个组件并从上下文菜单中选择启动选项来启动组件。
如果启动进程组,则将启动该进程组中的所有组件(包括子进程组),无效或禁用的组件除外。
一旦启动,处理器的状态指示器将变为播放符号( )。
)。
停止组件
组件可以在运行时停止。通过右键单击组件并从上下文菜单中单击停止选项,或者通过选择组件并单击操作选项板中的Stop按钮( )来停止组件。
)来停止组件。
如果进程组已停止,则将停止进程组(包括子进程组)中的所有组件。
停止后,组件的状态指示器将更改为停止符号( )。
)。
停止组件不会中断其当前正在运行的任务。相反,它会停止安排要执行的新任务。活动任务的数量显示在处理器的右上角(有关详细信息,请参阅处理器的剖析)。
启用/禁用组件
启用组件后,即可启动它。例如,用户可以选择在组件仍然是正在组装的数据流的一部分时禁用组件。通常,如果不打算运行组件,则禁用该组件,而不是将其置于停止状态。这有助于区分有意未运行的组件、可能已暂时停止的组件(例如,更改组件的配置),和无意中从未重新启动。
当需要重新启用组件时,可以通过选择组件并单击操作选项板中的Enable按钮( )来启用它。仅当禁用所选组件时,此选项才可用。或者,可以通过选中处理器配置对话框的设置选项卡中的启用选项旁边的复选框或端口的配置对话框来启用组件。
)来启用它。仅当禁用所选组件时,此选项才可用。或者,可以通过选中处理器配置对话框的设置选项卡中的启用选项旁边的复选框或端口的配置对话框来启用组件。
启用后,组件的状态指示器将更改为Invalid( )或Stopped(),具体取决于组件是否有效。
)或Stopped(),具体取决于组件是否有效。
然后,通过选择组件并单击操作选项板中的Disable按钮( ),或清除处理器配置对话框的设置选项卡中的启用选项旁边的复选框或端口的配置对话框,可以禁用组件。
),或清除处理器配置对话框的设置选项卡中的启用选项旁边的复选框或端口的配置对话框,可以禁用组件。
只能启用和禁用端口和处理器。
远程流程组传输
远程进程组提供了一种向远程NiFi实例发送数据或从中检索数据的机制。将远程进程组(RPG)添加到画布时,会添加"Transmission Disabled",如左上角的图标( )所示。当传输被禁用时,可以通过右键单击RPG并单击启用传输菜单项来启用它。这将导致有连接的所有端口开始传输数据。这将导致状态指示灯变为Transmission Enabled图标(
)所示。当传输被禁用时,可以通过右键单击RPG并单击启用传输菜单项来启用它。这将导致有连接的所有端口开始传输数据。这将导致状态指示灯变为Transmission Enabled图标( )。
)。
如果与远程进程组通信时出现问题,则可能会在左上角显示警告指示符()。使用鼠标将鼠标悬停在此警告指示器上将提供有关该问题的更多信息。
单独端口传输
有时,DFM可能希望仅为远程进程组中的特定端口启用或禁用传输。这可以通过右键单击远程进程组并选择远程端口菜单项来完成。这提供了一个配置对话框,可以从中配置每个端口:
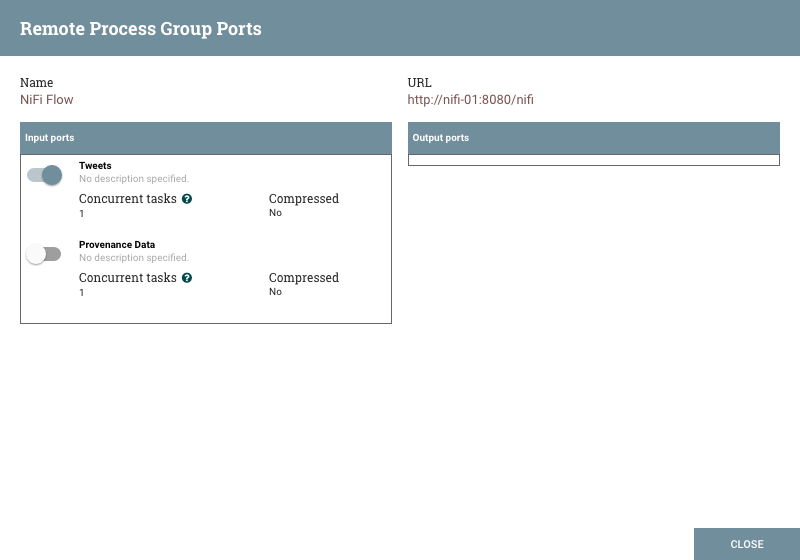
左侧列出了NiFi远程实例允许发送数据的所有输入端口。右侧列出了此实例能够从中提取数据的所有输出端口。如果远程实例正在使用安全通信(NiFi实例的URL以https://,而不是http://)开头,则不会显示远程实例未对此实例提供的任何端口。
如果此对话框中未显示预期显示的端口,请确保实例具有适当的权限,并且远程进程组的流是最新的。可以通过关闭端口配置对话框并查看远程进程组的右下角来检查。显示上次刷新流的日期。如果流程似乎已过时,可以通过右键单击远程进程组并选择"刷新流程"来更新它。(有关更多信息,请参阅远程进程组的解剖)。
每个端口都显示端口名称,后跟其描述,当前配置的并发任务数,以及是否将压缩发送到此端口的数据。此信息的左侧是用于打开或关闭端口的开关。那些没有连接到它们的连接的端口显示为灰色:
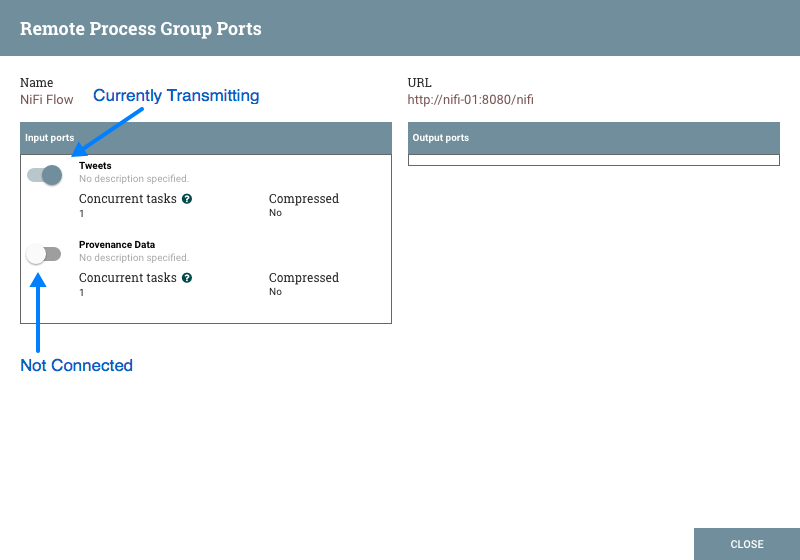
on/off 开关提供了一种机制,可以独立地启用和禁用远程过程组中每个端口的传输。可以通过单击编辑 on/off开关下方的铅笔图标 来配置已连接但当前未传输的端口 。单击此图标将允许DFM更改并发任务的数量,以及在向此端口传输数据时是否应使用压缩。
来配置已连接但当前未传输的端口 。单击此图标将允许DFM更改并发任务的数量,以及在向此端口传输数据时是否应使用压缩。
在DataFlow中导航
关于dataflow,NiFi提供了各种机制。NiFi用户界面部分描述了在NiFi画布中导航的各种方法;但是,一旦画布上存在dataflow,就会有其他方法从一个组件到另一个组件。当流中存在多个流程组时,面包屑会显示在屏幕的底部,从而提供在它们之间导航的方法。此外,要进入当前在画布上可见的进程组,只需双击它,就会向下钻取它。Connections还提供了一种在流程中从一个位置跳转到另一个位置的方法,右键单击连接并选择"Go to source"或"Go to destination"以跳转到连接的一端或另一端。这在大型复杂数据流中非常有用,其中连接线可能很长并且跨越画布的大部分区域。最后,所有组件都提供在流程中向前或向后跳跃的能力。右键单击任何组件(例如,处理器,进程组,端口等),然后选择"Upstream connections"或"Downstream connections",会打开一个对话框窗口,显示用户可以跳转到的可用上游或下游连接。当尝试沿向后方向跟踪数据流时,这尤其有用。通常很容易从头到尾跟踪数据流的路径,向下钻取到嵌套的流程组;但是,在反方向上跟踪数据流可能更加困难。
组件链接
超链接可用于直接导航到NiFi画布上的组件。在配置多租户授权时,这尤其有用。例如,可以将URL提供给用户以将其定向到他们具有特权的特定进程组。
NiFI实例的默认URL是 http://hostname:8080/nifi 指向根进程组。在画布上选择组件后,将使用表单中组件的进程组ID和组件ID更新URL http://hostname:8080/nifi/?processGroupId=UUID&componentIds=UUIDs 。在以下屏幕截图中,进程组PG1中的GenerateFlowFile处理器是所选组件:
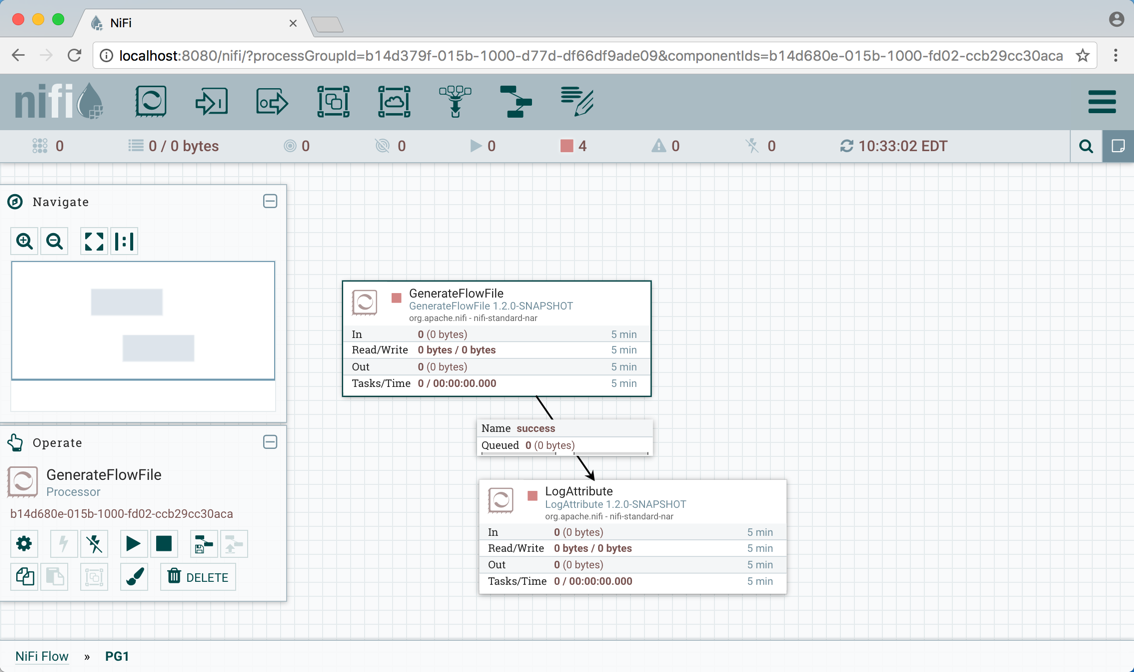
支持链接到画布上的多个组件,但限制URL的长度不能超过2000个字符。
组件对齐
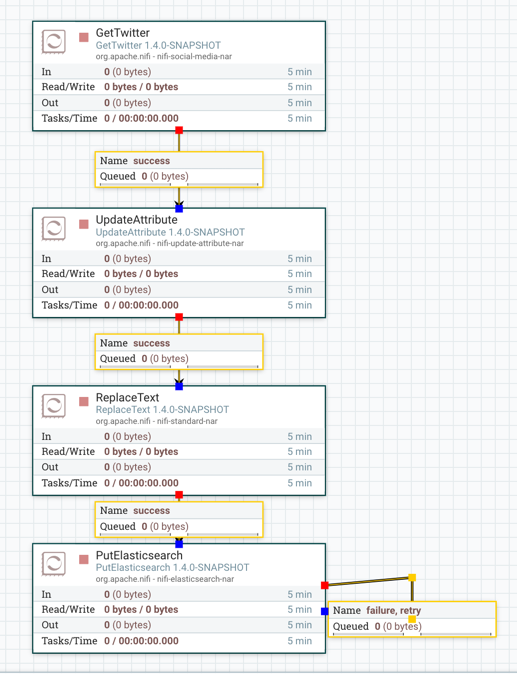
NiFi画布上的组件可以对齐,以更精确地排列数据流。为此,首先选择要对齐的所有组件。然后右键单击以查看上下文菜单,并根据所需结果选择"Align vertically(垂直对齐)"或"Align horizontally(水平对齐)"。
垂直对齐
以下是在画布上垂直对齐组件的示例。选中所有组件后,右键单击:
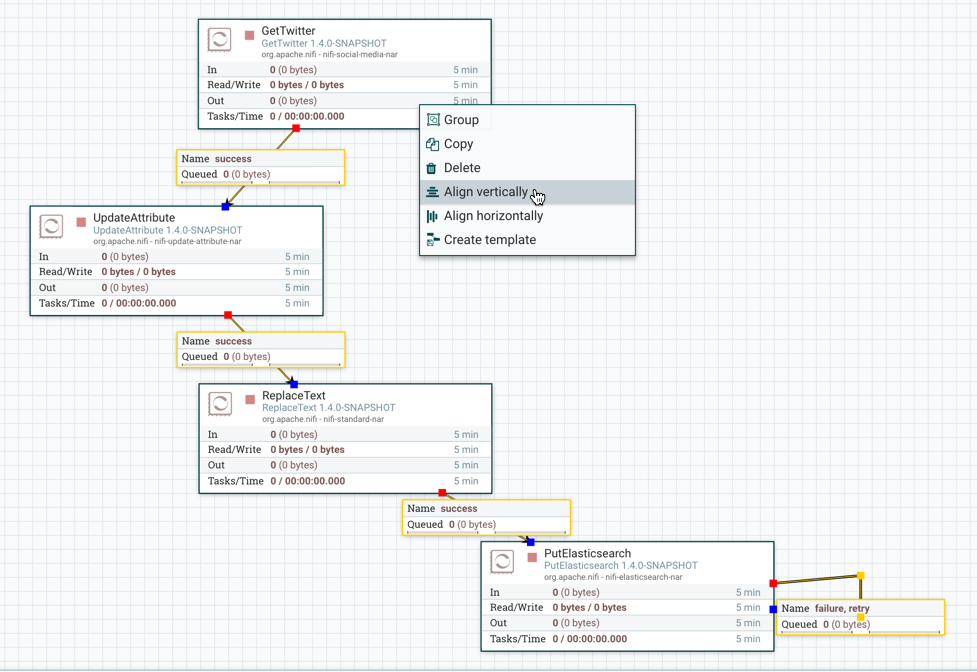
并选择垂直对齐以获得以下结果:
水平对齐
以下是在画布上水平对齐组件的示例。选中所有组件后,右键单击:
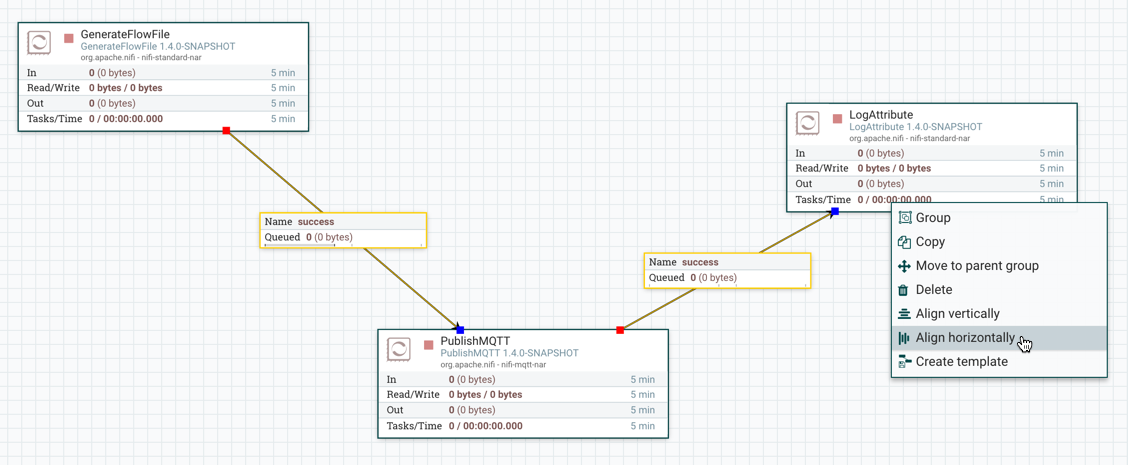
并选择水平对齐以获得以下结果:

监控DataFlow
NiFi提供有关DataFlow的大量信息,以便监控其健康状况。状态栏提供有关整体系统运行状况的信息(请参阅NiFi用户界面)。处理器,进程组和远程进程组提供有关其操作的细粒度详细信息。连接和进程组提供有关其队列中数据量的信息。摘要页面以表格格式提供有关画布上所有组件的信息,还提供包括磁盘使用情况,CPU利用率以及Java堆和垃圾收集信息的系统诊断。在集群环境中,此信息可以按节点使用,也可以作为整个集群中的聚合使用。我们将在下面探讨每个监控工件。
处理器的剖析
NiFi提供有关画布上每个处理器的大量信息。下图显示了处理器的解剖结构:

该图像概述了以下元素:
处理器类型:NiFi提供多种不同类型的处理器,以便执行各种任务。每种类型的处理器都旨在执行一项特定任务。处理器类型(在此示例中为PutFile)描述了此处理器执行的任务。在这种情况下,处理器将FlowFile写入磁盘 - 或者将FlowFile放入文件。
公告指示器:当处理器记录某个事件已发生时,它会生成一个公告,以通过用户界面通知正在监控NiFi的人员。DFM能够通过更新处理器配置对话框的设置选项卡中的公告级别字段来配置应在用户界面中显示的公告。默认值为WARN,这意味着UI中仅显示警告和错误。除非此处理器存在公告,否则此图标不存在。当它出现时,用鼠标悬停在图标上将提供一个工具提示,说明处理器和公告级别提供的消息。如果NiFi的实例是集群的,它还将显示发布公告的节点。
状态指示灯:显示处理器的当前状态。以下指标是可能的:
- 正在运行:处理器当前正在运行。
- 已停止:处理器有效并已启用但未运行。
- 无效:处理器已启用但当前无效且无法启动。将鼠标悬停在此图标上将提供工具提示,指示处理器无效的原因。
- 已禁用:处理器未运行,在启用之前无法启动。此状态不表示处理器是否有效。
处理器名称:这是处理器的用户定义名称。默认情况下,Processor的名称与Processor Type相同。在示例中,此值为"Copy to /review"。
活动任务:此处理器当前正在执行的任务数。此数字受处理器配置对话框的计划选项卡中的并发任务设置的约束。在这里,我们可以看到处理器当前正在执行一项任务。如果NiFi实例是集群的,则此值表示当前正在集群中的所有节点上执行的任务数。
5分钟统计:处理器以表格形式显示几种不同的统计数据。这些统计数据中的每一个都代表过去五分钟内完成的工作量。如果NiFi实例是集群的,则这些值表示在过去五分钟内所有节点组合完成了多少工作。这些指标是:
In:处理器从其传入Connections的队列中提取的数据量。此值表示为count size,其中count是从队列中提取的FlowFiles的数量,size是这些FlowFiles内容的总大小。在此示例中,处理器已从输入队列中提取了29个FlowFiles,总计14.16兆字节(MB)。
Read/Write:处理器从磁盘读取并写入磁盘的FlowFile内容的总大小。这提供了有关此处理器所需的I/O性能的有用信息。某些处理器可能只读取数据而不写入任何内容,而某些处理器不会读取数据但只会写入数据。其他可能既不会读取也不会写入数据,而某些处理器会读取和写入数据。在这个例子中,我们看到在过去的五分钟内,这个处理器读取了4.88 MB的FlowFile内容,并且写了4.88 MB。这是我们所期望的,因为这个处理器只是将FlowFile的内容复制到磁盘。但请注意,这与从输入队列中提取的数据量不同。这是因为它从输入队列中提取的某些文件已经存在于输出目录中,并且处理器配置为在发生这种情况时将FlowFiles路由到失败。因此,对于那些已经存在于输出目录中的文件,数据既不会被读取也不会被写入磁盘。
Out:处理器已传输到其出站连接的数据量。这不包括处理器自行删除的FlowFiles,也不包括路由到自动终止的连接的FlowFiles。与上面的"In"指标一样,此值表示为count size,其中count是已转移到出站Connections的FlowFiles的数量,size是这些FlowFiles内容的总大小。在此示例中,所有关系都配置为自动终止,因此不会报告任何FlowFiles已被转出。
Tasks/Time:此处理器在过去5分钟内被触发运行的次数,以及执行这些任务所花费的时间。时间格式为hour:minute:second。请注意,所花费的时间可能超过五分钟,因为许多任务可以并行执行。例如,如果处理器计划运行60个并发任务,并且每个任务都需要一秒钟才能完成,则所有60个任务可能会在一秒钟内完成。但是,在这种情况下,我们会看到时间指标显示它需要60秒,而不是1秒。这个时间可以被认为是"系统时间",或换句话说,
进程组的剖析
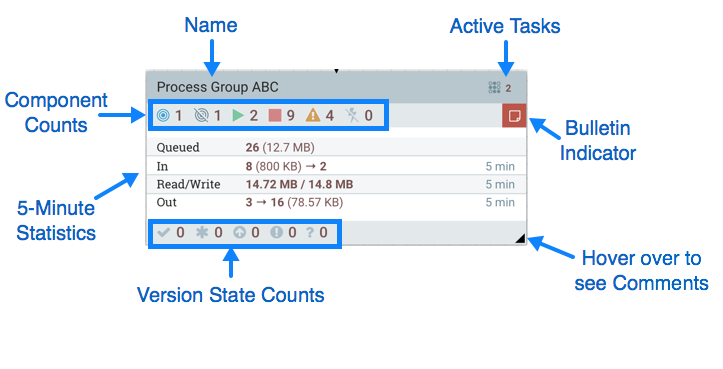
进程组提供了一种机制,用于将组件组合到一个逻辑构造中,以便以更高级别更容易理解的方式组织DataFlow。下图突出显示了构成Process Group解剖结构的不同元素:
过程组由以下元素组成:
名称:这是进程组的用户定义名称。将进程组添加到画布时,将设置此名称。稍后可以通过右键单击"进程组"并单击"配置"菜单选项来更改名称。在此示例中,进程组的名称是"Process Group ABC"。
公告指示器:当进程组的子组件发布公告时,该公告也会传播到组件的父进程组。当任何组件具有活动公告时,将显示此指示符,允许用户使用鼠标将鼠标悬停在图标上以查看公告。
活动任务:此进程组中组件当前正在执行的任务数。在这里,我们可以看到Process Group当前正在执行两项任务。如果NiFi实例是集群的,则此值表示当前正在集群中的所有节点上执行的任务数。
统计信息:流程组提供有关过程组在过去5分钟内处理的数据量以及当前在流程组中排队的数据量的统计信息。以下元素包含流程组的"统计"部分:
队列:当前在进程组中排队的FlowFiles数。此字段表示为count(size),其中count是当前在Process Group中排队的FlowFiles的数量,size是这些FlowFiles内容的总大小。在此示例中,Process Group当前有26个FlowFiles排队,总大小为12.7兆字节(MB)。
In:在过去5分钟内通过其所有输入端口传输到Process Group的FlowFiles数。此字段表示为count / size→ports,其中count是过去5分钟内进入Process Group的FlowFiles的数量,size是这些FlowFiles内容的总大小, ports是输入端口的数量。在此示例中,8个FlowFiles已进入进程组,总大小为800 KB,并且存在两个输入端口。
Read/Write:进程组中的组件已从磁盘读取并写入磁盘的FlowFile内容的总大小。这提供了有关此Process Group所需的I / O性能的有用信息。在此示例中,我们看到在过去五分钟内,此Process Group中的组件读取了14.72 MB的FlowFile内容,并写入了14.8 MB。
Out:在过去5分钟内通过其输出端口传输出Process Group的FlowFiles数。此字段表示为ports→count(size),其中ports是输出端口的数量,count是过去5分钟内退出Process Group的FlowFiles的数量和size是FlowFiles内容的总大小。在此示例中,有三个输出端口,16个FlowFiles已退出进程组,其总大小为78.57 KB。
组件计数:组件计数元素提供有关进程组中每种类型的组件数量的信息。以下提供了有关这些图标及其含义的信息:
- 传输端口:当前配置为将数据传输到远程NiFi实例或从远程NiFi实例提取数据的远程进程组端口的数量。
- 非传输端口:当前连接到此进程组中的组件但当前已禁用其传输的远程进程组端口的数量。
- 运行组件:当前在此进程组中运行的处理器,输入端口和输出端口的数量。
- 已停止的组件:当前未运行但有效且已启用的处理器,输入端口和输出端口的数量。这些组件已准备好启动。
- 无效组件:已启用但当前未处于有效状态的处理器,输入端口和输出端口的数量。这可能是由于配置错误或缺少关系造成的。
- 已禁用组件:当前已禁用的处理器,输入端口和输出端口的数量。这些组件可能有效,也可能无效。如果启动了进程组,则这些组件不会导致任何错误,但不会启动。
版本状态计数:版本状态计数元素提供有关进程组中有多少版本化进程组的信息。有关更多信息,请参阅版本状态
注释:将流程组添加到画布时,将为用户提供指定注释的选项,以便提供有关流程组的信息。稍后可以通过右键单击"进程组"并单击"配置"菜单选项来更改注释。
远程进程组的剖析
创建DataFlow时,通常需要将数据从一个NiFi实例传输到另一个实例。在这种情况下,NiFi的远程实例可以被视为进程组。因此,NiFi提供了远程过程组的概念。从用户界面,远程进程组看起来类似于进程组。但是,不是显示有关远程进程组的内部工作和状态的信息(例如队列大小),而是呈现有关远程进程组的信息与此NiFi实例与远程实例之间发生的交互有关。
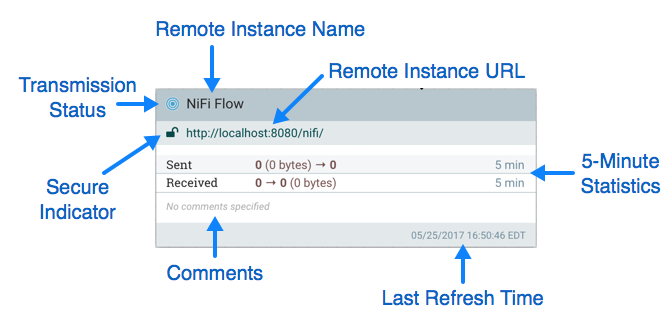
上图显示了组成远程进程组的不同元素。在这里,我们提供有关所提供信息的图标和详细信息的说明。
传输状态:传输状态指示当前是否启用此NiFi实例与远程实例之间的数据传输。
如果任何输入端口或输出端口当前配置为发送,则显示的图标将是Transmission Enabled图标( )如果 当前连接的所有输入端口和输出端口都已停止,则传输已禁用图标( )。远程实例名称:这是远程实例报告的NiFi实例的名称。首次创建远程进程组时,在获取此信息之前,此处将显示远程实例的URL。
远程实例URL:这是远程进程组指向的远程实例的URL。将远程进程组添加到画布并且无法更改时,将输入此URL。
安全指示器:此图标指示与远程NiFi实例的通信是否安全。如果与远程实例的通信是安全的,则将通过锁定图标(
 )指示 。如果通信不安全,将通过未锁定图标指示(
)指示 。如果通信不安全,将通过未锁定图标指示( )。如果通信是安全的,则在远程实例的管理员授予访问权限之前,此NiFi实例将无法与远程实例通信。每当将远程进程组添加到画布时,这将自动发起请求,以便在远程实例上创建此NiFi实例的用户。在远程实例上的管理员将用户添加到系统并向用户添加NiFi角色之前,此实例将无法与远程实例通信。如果通信不安全,远程进程组可以从任何人接收数据,并且在NiFi实例之间传输数据时不会对数据进行加密。
)。如果通信是安全的,则在远程实例的管理员授予访问权限之前,此NiFi实例将无法与远程实例通信。每当将远程进程组添加到画布时,这将自动发起请求,以便在远程实例上创建此NiFi实例的用户。在远程实例上的管理员将用户添加到系统并向用户添加NiFi角色之前,此实例将无法与远程实例通信。如果通信不安全,远程进程组可以从任何人接收数据,并且在NiFi实例之间传输数据时不会对数据进行加密。5分钟统计信息:显示远程进程组的两个统计信息:已发送和已接收。这两种格式都是count size格式,其中count是在前五分钟内发送或接收的FlowFiles的数量,size是这些FlowFiles内容的总大小。
注释:为远程进程组提供的注释不是由此NiFi的用户添加的注释,而是由远程实例的管理员添加的注释。这些评论表明了NiFi实例的整体目的。
上次刷新时间:从远程实例中提取并在用户界面中的远程进程组上呈现的信息会在后台定期刷新。此元素指示最后一次刷新的时间,或者如果信息在相当长的时间内未刷新,则该值将更改为指示远程流不是最新的。通过右键单击远程进程组并选择"刷新流程"菜单项,可以触发NiFi以启动刷新此信息。
队列交互
必要时可以查看连接中排队的FlowFiles。队列列表通过List queueConnection的上下文菜单打开。该列表将根据配置的优先级返回活动队列中的前100个FlowFiles。即使源和目标正在运行,也可以执行列表。
此外,单击最左侧列中的Details按钮( )可以查看列表中Flowfile的详细信息。从这里,可以使用FlowFile详细信息和属性以及用于下载或查看内容的按钮。仅在nifi.content.viewer.url已配置内容时才能查看内容。如果Connection的源或目标正在运行,则所需的FlowFile可能不再位于活动队列中。
)可以查看列表中Flowfile的详细信息。从这里,可以使用FlowFile详细信息和属性以及用于下载或查看内容的按钮。仅在nifi.content.viewer.url已配置内容时才能查看内容。如果Connection的源或目标正在运行,则所需的FlowFile可能不再位于活动队列中。
必要时,还可以删除连接中排队的FlowFiles。通过Empty queueConnection的上下文菜单启动FlowFiles的delete。如果源和目标正在运行,也可以执行此操作。
摘要页面
虽然NiFi画布对于了解如何布置配置的DataFlow非常有用,但在尝试辨别系统状态时,此视图并不总是最佳的。为了帮助用户了解DataFlow在更高级别的运行方式,NiFi提供了摘要页面。此页面位于用户界面右上角的"全局菜单"中。有关此工具栏位置的详细信息,请参阅NiFi用户界面部分。
通过从全局菜单中选择摘要来打开摘要页面。这将打开摘要表对话框:
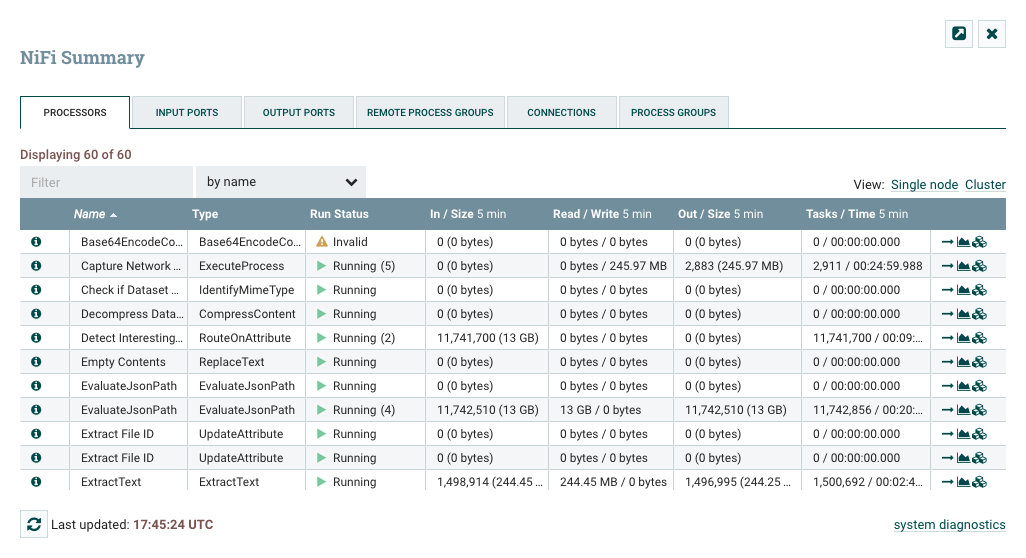
此对话框提供有关画布上每个组件的大量信息。下面,我们在对话框中注释了不同的元素,以便更容易地讨论对话框。
摘要页面主要由一个表组成,该表提供有关画布上每个组件的信息。此表上方是一组五个选项卡,可用于查看不同类型的组件。表中提供的信息与为画布上的每个组件提供的信息相同。可以通过单击列的标题对表中的每个列进行排序。有关详细上显示的类型的信息,请参见处理器的剖析,一个进程组的剖析,和一个远程进程组的剖析。
摘要页面还包含以下元素:
Bulletin Indicator:与整个用户界面中的其他位置一样,当此图标存在时,将鼠标悬停在图标上将提供有关生成的公告的信息,包括消息,严重性级别,公告生成的时间以及(在集群环境中)生成公告的节点。与"摘要"表中的所有列一样,可以通过单击标题对显示公告的列进行排序,以便所有当前存在的公告显示在列表顶部。
Details:单击详细信息图标将为用户提供组件的详细信息。此对话框与用户右键单击组件并选择查看配置菜单项时提供的对话框相同。
Go To:单击此按钮将关闭摘要页面,并将用户直接带到NiFi画布上的组件。这可能会更改用户当前所在的进程组。如果已在新的浏览器选项卡或窗口中打开摘要页面(通过单击"Pop Out"按钮,如下所述),则此图标不可用。
Status History:单击状态历史记录图标将打开一个新对话框,其中显示为此组件呈现的统计信息的历史视图。有关更多信息,请参阅组件的历史统计部分。
Refresh:该Refresh按钮允许用户刷新显示的信息,而无需关闭对话框并再次打开它。上次刷新信息的时间显示在Refresh按钮右侧。页面上的信息不会自动刷新。
Filter:Filter元素允许用户通过键入全部或部分条件(例如处理器类型或处理器名称)来过滤摘要表的内容。可用的过滤器类型根据所选选项卡而不同。例如,如果查看处理器选项卡,则用户可以按名称或类型进行过滤。查看连接选项卡时,用户可以按源,名称或目标名称进行筛选。更改文本框的内容时,将自动应用过滤器。文本框下方是表中表中有多少条目与过滤器匹配以及表中存在多少条目的指示符。
Pop-Out:监视流时,能够在单独的浏览器选项卡或窗口中打开摘要表是有帮助的。按钮旁边的Pop-Out按钮Close将导致在新的浏览器选项卡或窗口中打开整个摘要对话框(具体取决于浏览器的配置)。页面弹出后,对话框将在原始浏览器选项卡/窗口中关闭。在新选项卡/窗口中,"Pop-Out"按钮和"Go To"按钮将不再可用。
System Diagnostics:系统诊断窗口提供有关系统在系统资源利用率方面的执行情况的信息。虽然这主要适用于管理员,但在此视图中提供了它,因为它确实提供了系统摘要。此对话框显示CPU利用率,磁盘空闲程度以及特定于Java的度量标准(如内存大小和利用率)以及垃圾收集信息等信息。
组件的历史统计
虽然摘要表和画布显示了与过去五分钟内组件性能相关的数字统计信息,但查看历史统计信息通常也很有用。通过右键单击组件并选择状态历史记录菜单选项或单击摘要页面中的状态历史记录( 有关详细信息,请参阅摘要页面),可以获得此信息。
存储的历史信息量可在NiFi属性中配置,但默认为24 hours。有关特定配置信息,请参阅系统管理员指南的组件状态存储库。打开状态历史记录对话框时,它会提供历史统计信息的图表:
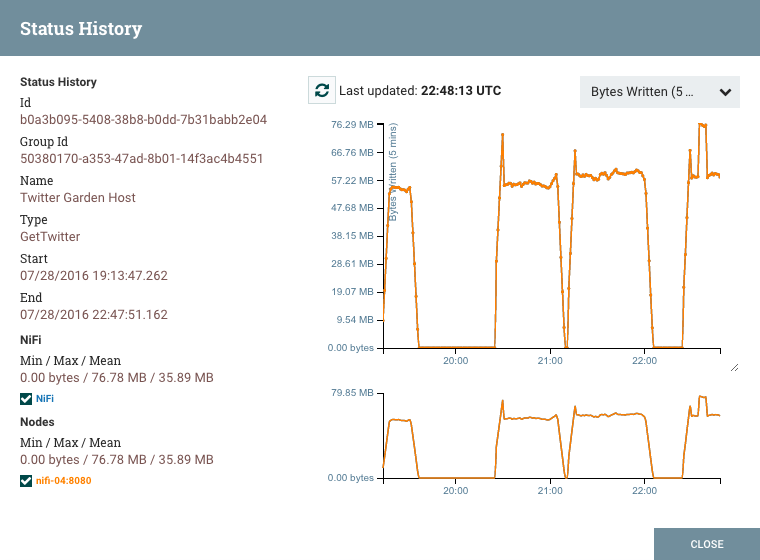
对话框的左侧提供有关统计信息所用组件的信息,以及绘制统计信息的文本表示。左侧提供以下信息:
Id:正在显示统计信息的组件的ID。
Group Id:组件所在的进程组的ID。
Name:要显示统计信息的组件的名称。
Component-Specific Entries:显示每种不同类型组件的信息。例如,对于处理器,将显示处理器的类型。对于Connection,将显示源和目标名称和ID。
Start:图表上显示的最早时间。
End:图表上显示的最新时间。
Min/Max/Mean:显示最小值,最大值和平均值(算术平均值或平均值)。如果选择了任何时间范围,这些值仅基于所选时间范围。如果对此NiFi实例进行聚类,则会为整个集群以及每个单独节点显示这些值。在集群环境中,每个节点以不同的颜色显示。这也用作图形的图例,显示图形中显示的每个节点的颜色。将鼠标悬停在集群上或图例中的其中一个节点上也会使相应的节点在图形中变为粗体。
对话框的右侧提供了下表中要呈现的不同类型度量标准的下拉列表。顶部图形较大,以便提供更容易阅读的信息呈现。在该图的右下角是一个小手柄( ),可以拖动它来调整图形的大小。也可以拖动对话框的空白区域以移动整个对话框。
),可以拖动它来调整图形的大小。也可以拖动对话框的空白区域以移动整个对话框。
底部图表更短,并提供选择时间范围的能力。在此处选择时间范围将使顶部图形仅显示所选的时间范围,但是以更详细的方式显示。此外,这将导致重新计算左侧的最小值/最大值/平均值。通过在图形上拖动矩形创建选择后,双击所选部分将使选择在垂直方向上完全展开(即,它将选择此时间范围内的所有值)。单击底部图形而不拖动将删除选择。
版本化DataFlow
当NiFi连接到NiFi注册表时,可以在进程组级别对数据流进行版本控制。有关NiFi Registry使用和配置的更多信息,请参阅 https://nifi.apache.org/docs/nifi-registry-docs/index.html 上的文档。
连接到NiFi注册表
要将NiFi连接到注册表,请从全局菜单中选择控制器设置。
这将显示NiFi设置窗口。选择注册表客户端选项卡,然后单击右上角的+按钮以注册新的注册表客户端。
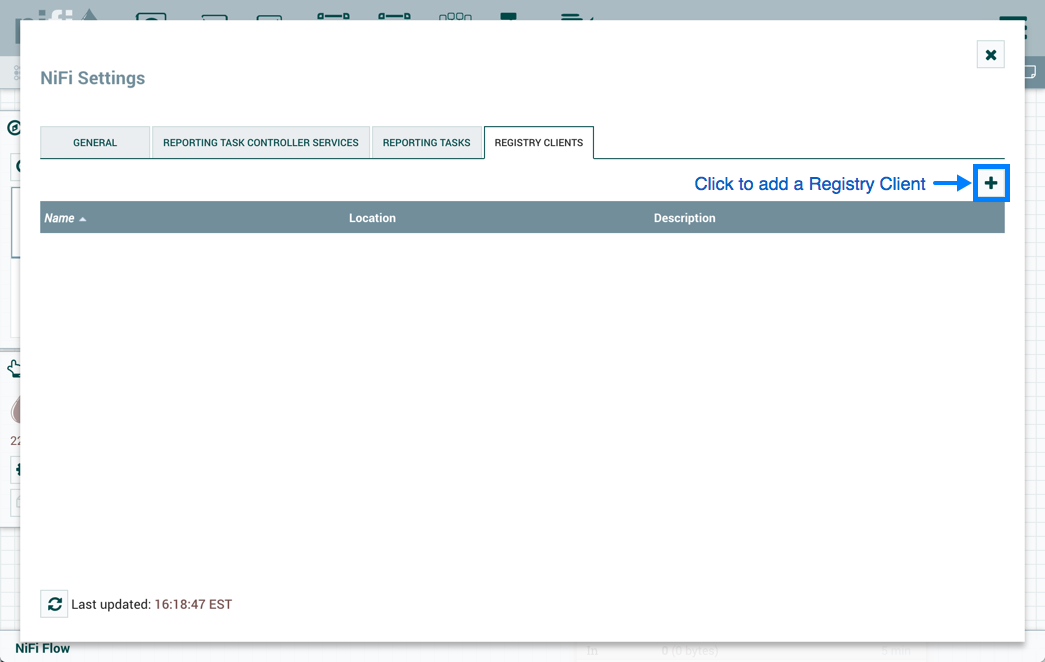
在添加注册表客户端窗口中,提供名称和URL。
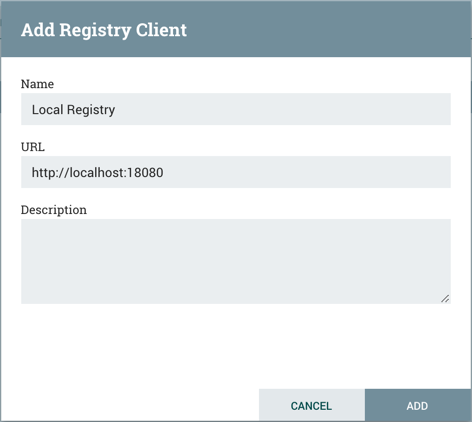
单击"Add"以完成注册。
版本化流程在注册表桶中存储和组织。注册管理员配置的存储桶策略和特权限定了用户可以从中导入版本化流的哪些存储桶以及用户可以将版本化流存储到哪些存储桶。有关存储桶策略和特权的信息可以在NiFi注册表用户指南(https://nifi.apache.org/docs/nifi-registry-docs/html/user-guide.html)中找到。
版本国家
版本化的进程组存在以下状态:
 Up to date:流程的版本是最新的。
Up to date:流程的版本是最新的。 Locally modified:已进行本地更改。
Locally modified:已进行本地更改。 Stale:可以使用更新版本的流程。
Stale:可以使用更新版本的流程。 Locally modified and stale:已进行本地更改,并且可以使用更新版本的流。
Locally modified and stale:已进行本地更改,并且可以使用更新版本的流。 Sync failure:无法将流与注册表同步。
Sync failure:无法将流与注册表同步。
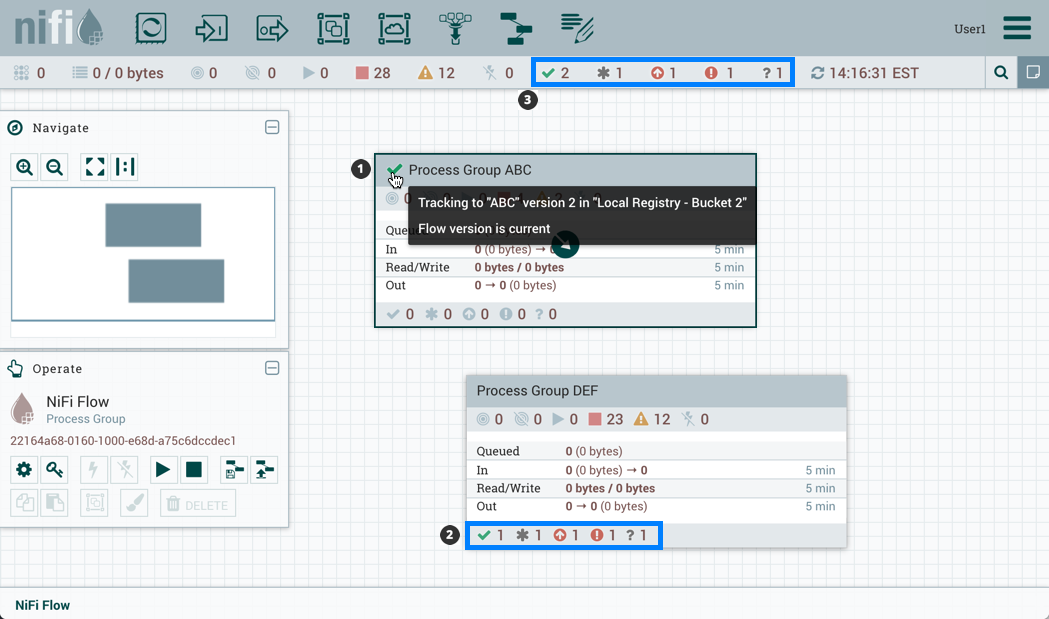
显示版本状态信息:
进程组名称旁边的版本化进程组本身。将鼠标悬停在状态图标上会显示有关版本化流程的其他信息。
在进程组的底部,用于进程组中包含的版本化流。
在UI顶部的状态栏中,用于根进程组中包含的版本化流。
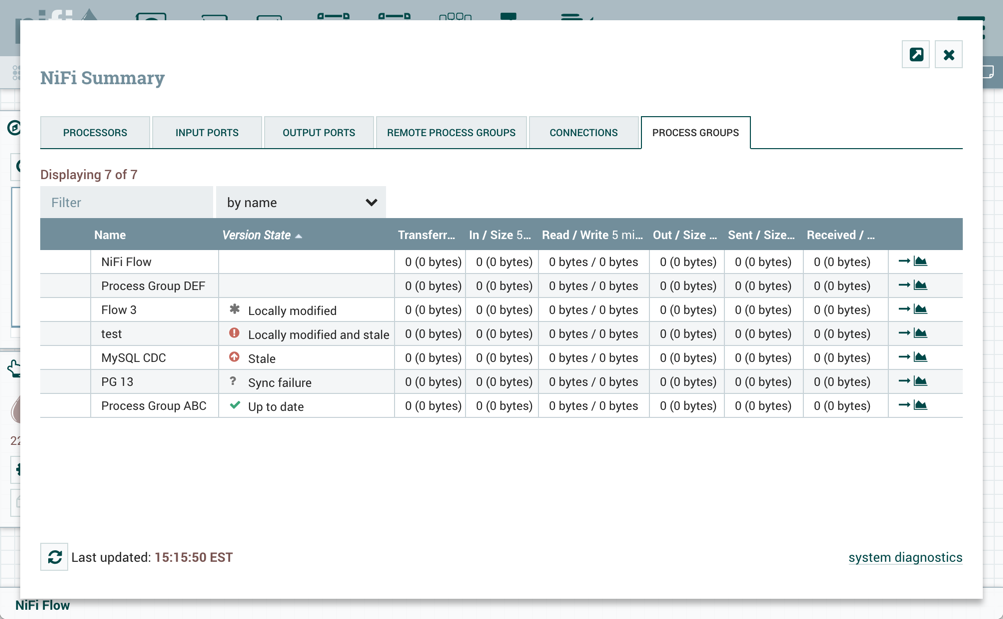
版本状态信息也显示在摘要页面的进程组选项卡中。
要查看最新版本状态,可能需要右键单击NiFi画布并从上下文菜单中选择刷新
导入版本化流程
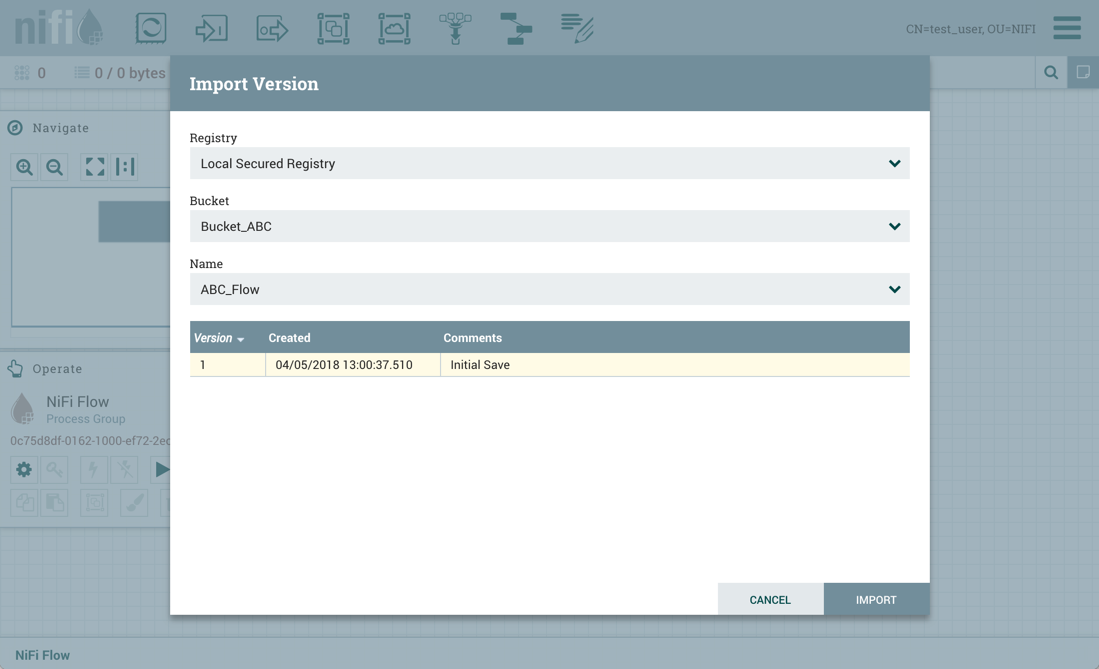
当NiFi实例连接到注册表时,"Import"链接将出现在添加进程组对话框中。
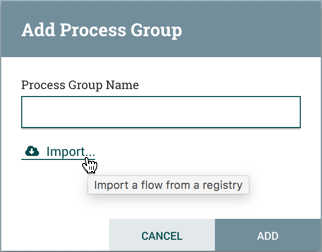
选择链接将打开导入版本对话框。
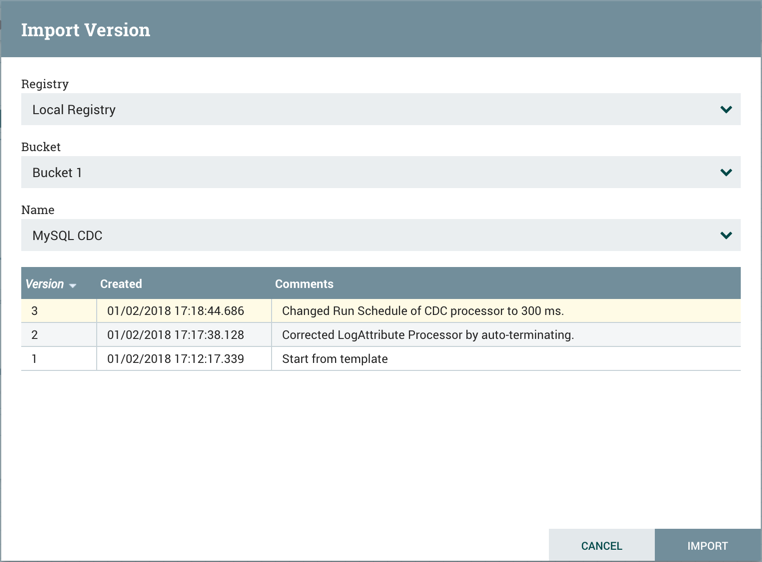
已连接的注册表将显示为注册表下拉菜单中的选项。对于选定的注册表,用户有权访问的存储桶将显示为存储桶下拉菜单中的选项。所选存储桶中的流的名称将显示为名称下拉菜单中的选项。选择要导入的流的所需版本,然后为要放置在画布上的数据流选择"Import"
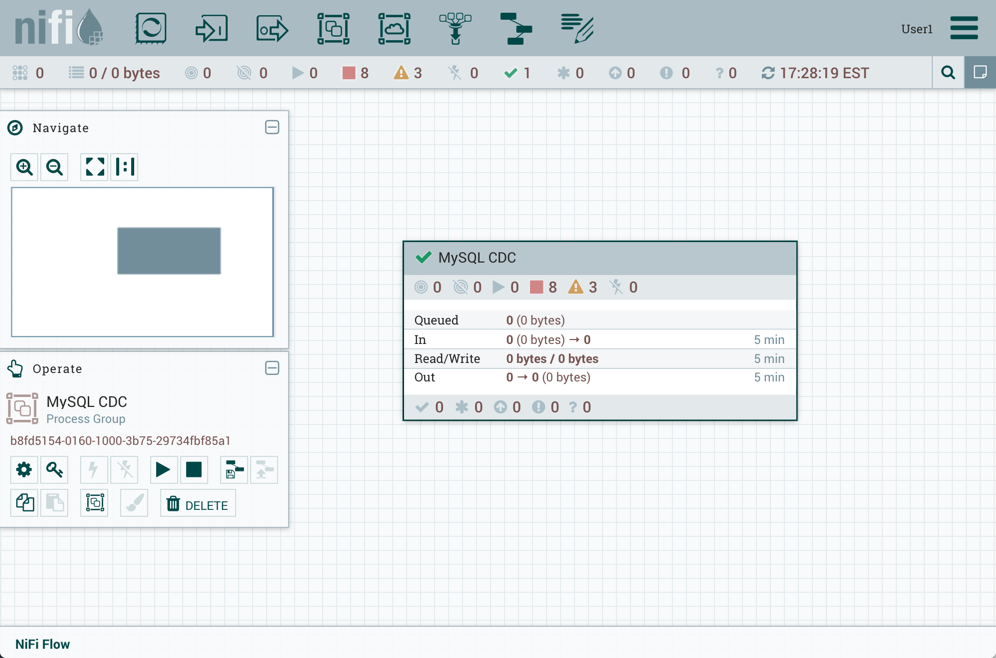
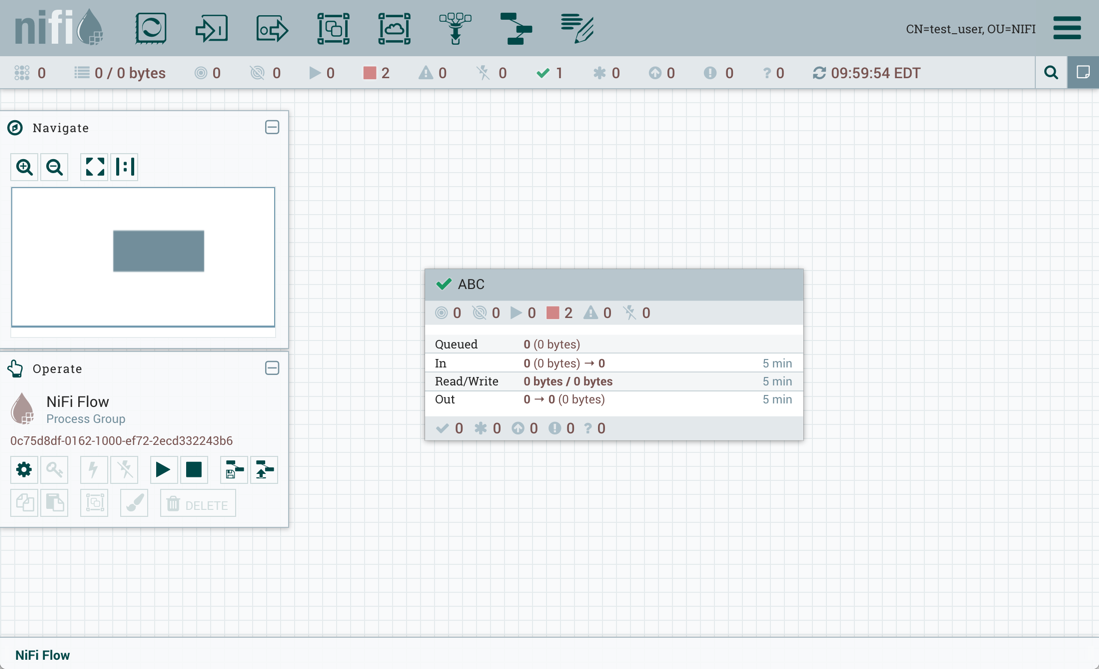
由于此示例中导入的版本是最新版本(MySQL CDC,版本3),因此版本化进程组的状态为"最新"()。如果导入的版本是旧版本,则状态将为"Stale"()。
启动版本控制
要将进程组置于版本控制之下,请右键单击进程组,然后在上下文菜单中选择"版本→启动版本控制"。
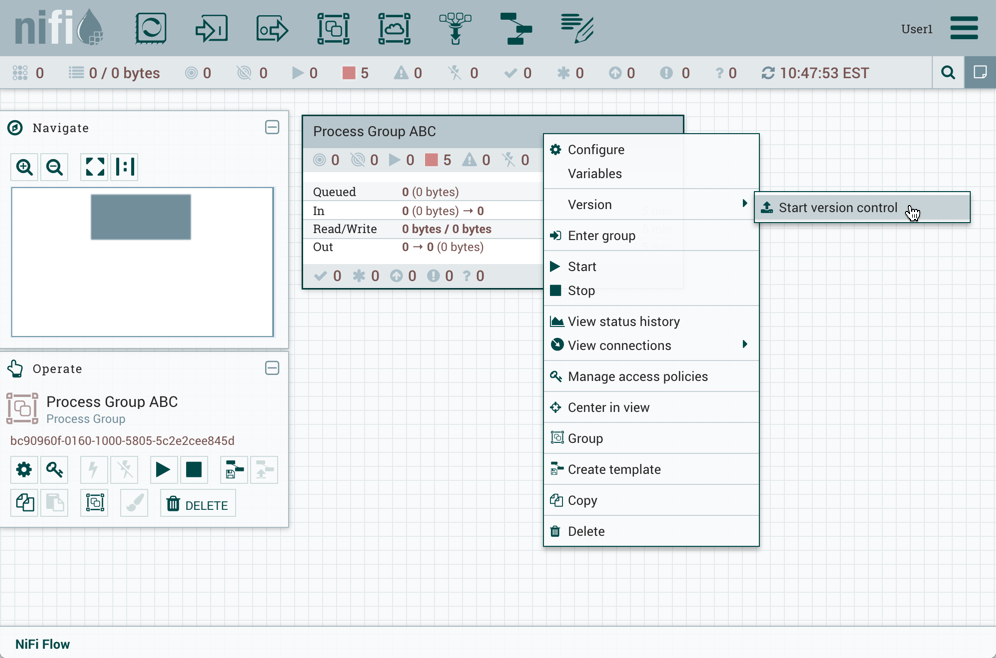
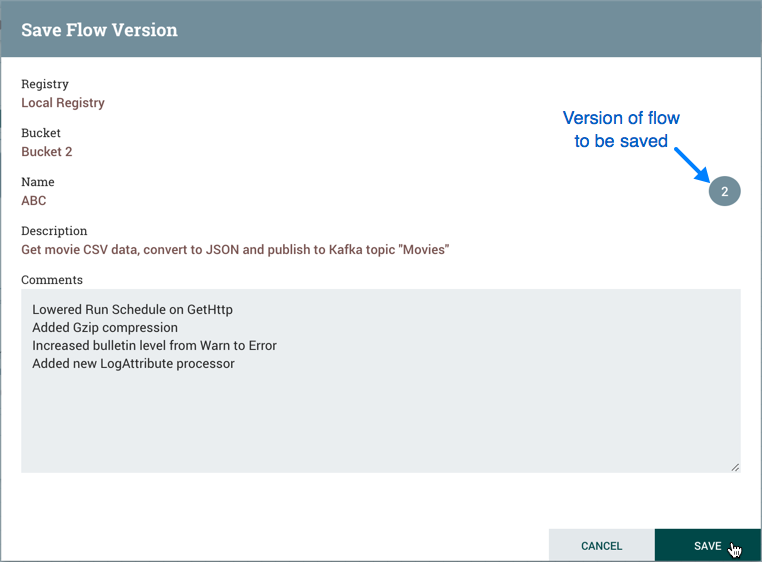
在Save Flow Version窗口中,选择Registry and Bucket并输入Flow的名称。如果需要,请为"描述"和"注释"字段添加内容。
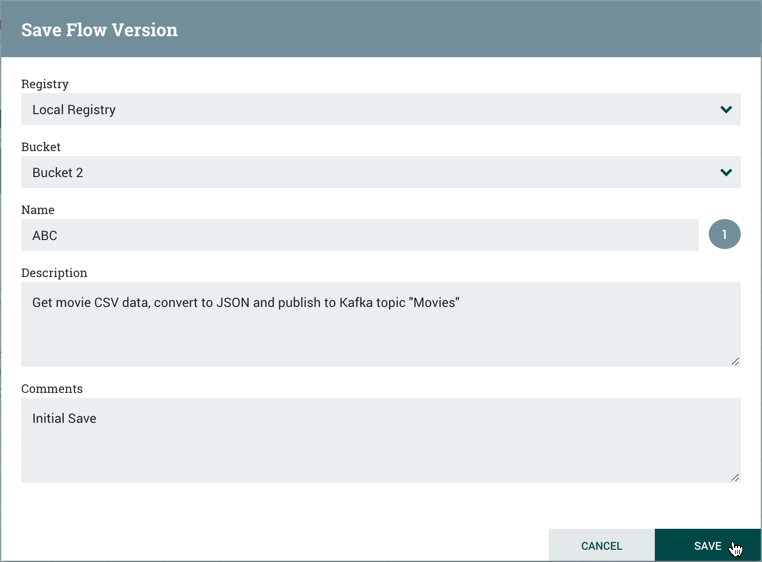
选择保存并保存流的版本1。
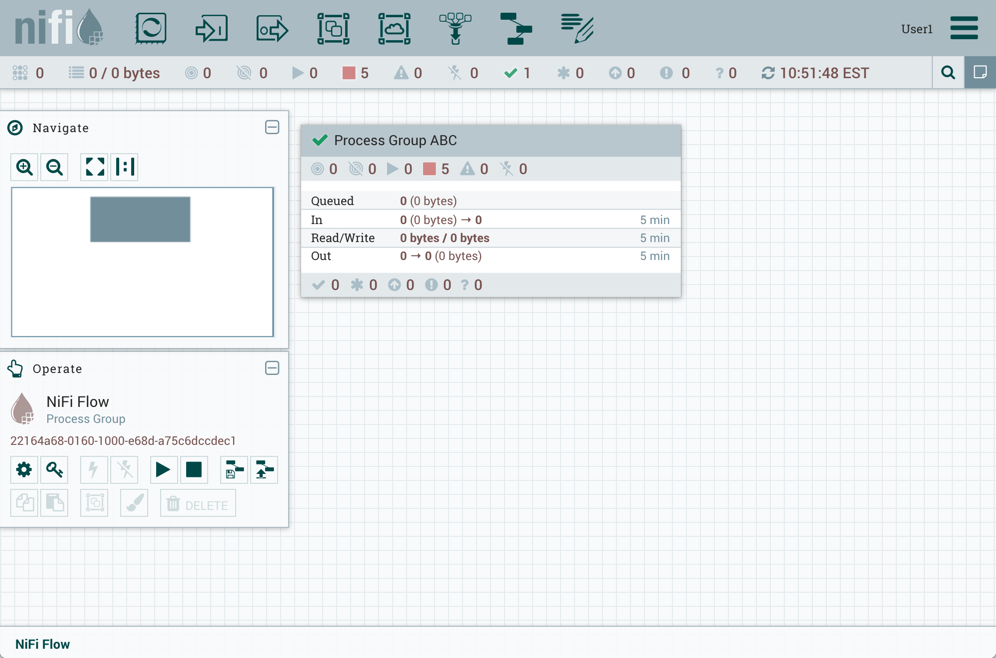
作为流的第一个和最新版本,版本化进程组的状态为"Up to date"()。
根进程组不能置于版本控制之下。
管理本地更改
当对版本化的进程组进行更改时,组件的状态将更新为"Locally modified"()。DFM可以显示,还原或提交本地更改。右键单击进程组时,可以在上下文菜单中选择这些选项:
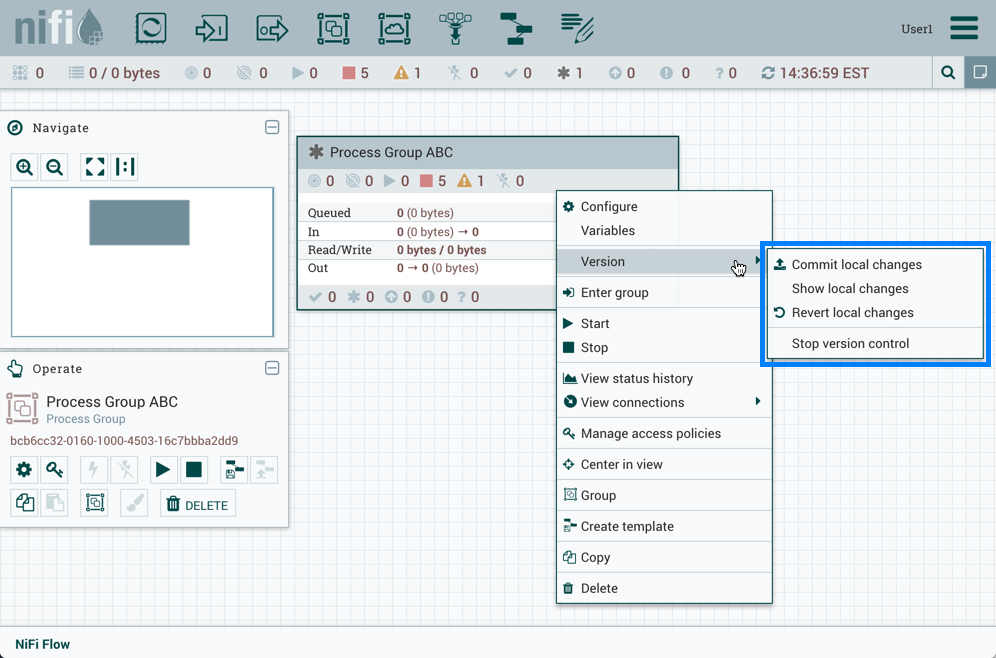
或者右键单击进程组内的画布:
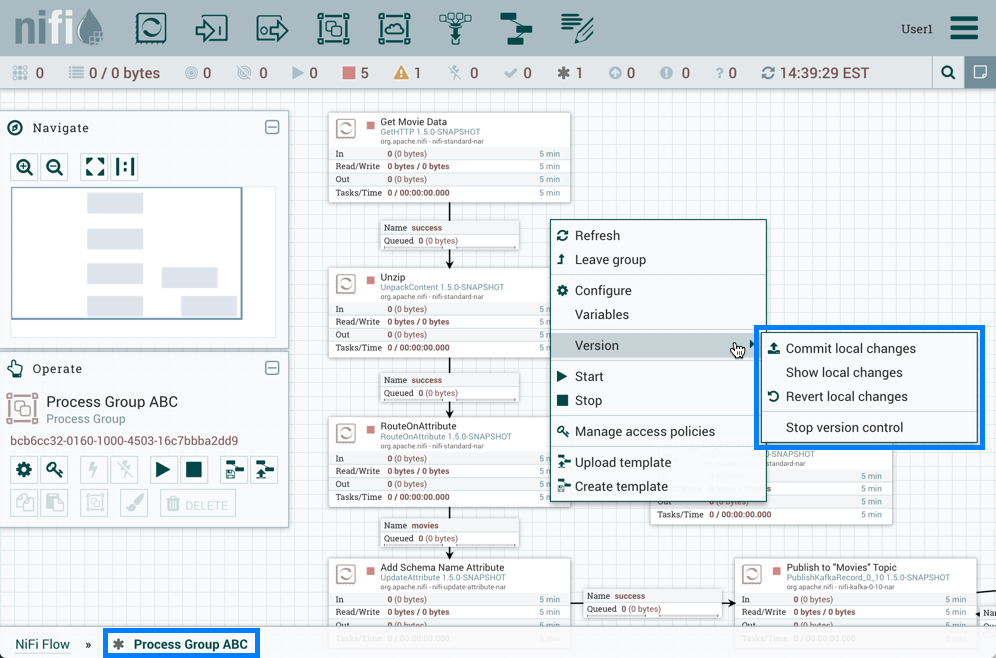
以下操作不被视为本地更改:
禁用/启用处理器和控制器服务
停止/启动处理器
修改敏感属性值
修改远程进程组URL
更新引用不存在的控制器服务的处理器以引用外部可用的控制器服务
创建,修改或删除变量
创建变量不会触发本地更改,因为创建变量本身并未改变流程处理的任何内容。必须创建或修改使用新变量的组件,这将触发本地更改。修改变量不会触发本地更改,因为变量值在每个环境中都是不同的。导入版本化流时,假定需要一次性操作来设置特定于给定环境的变量。删除变量不会触发本地更改,因为需要修改引用该变量的组件,这将触发本地更改。
变量不支持敏感值,并且在对流程组进行版本控制时将包含变量。有关更多信息,请参阅版本化流程中的变量。
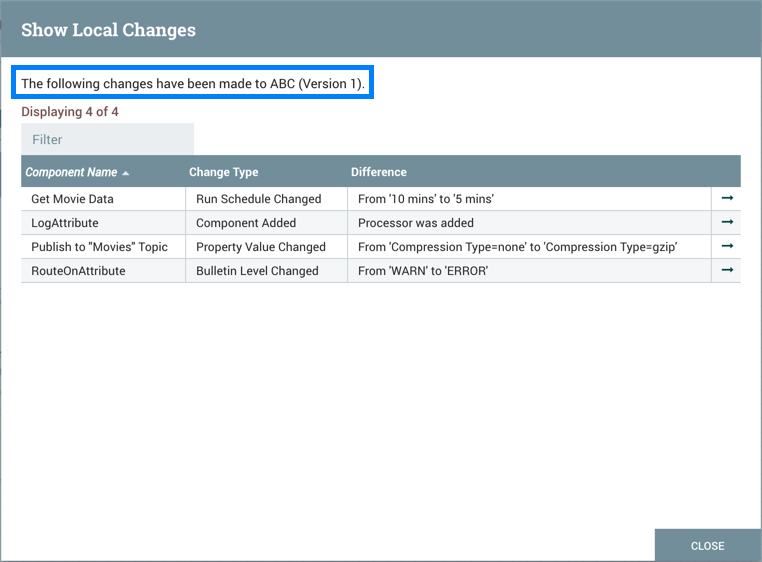
显示本地更改
通过从上下文菜单中选择"Version→Show local changes",可以在显示本地更改对话框中查看对版本化过程组所做的本地更改。
您可以通过选择去其行中的 图标来导航到组件。
图标来导航到组件。
如管理本地更改部分中所述,有些例外可以检查哪些操作是本地更改。此外,对同一属性的多次更改将仅显示为列表中的一个更改,因为更改是通过区分进程组的当前状态和"显示本地更改"对话框中记录的进程组的已保存版本来确定的。
还原本地更改
通过从上下文菜单中选择"Version→Revert local changes",还原对版本化进程组所做的本地更改。还原本地更改对话框显示DFM在启动还原之前要查看和考虑的本地更改列表。选择"Revert"以删除所有更改。
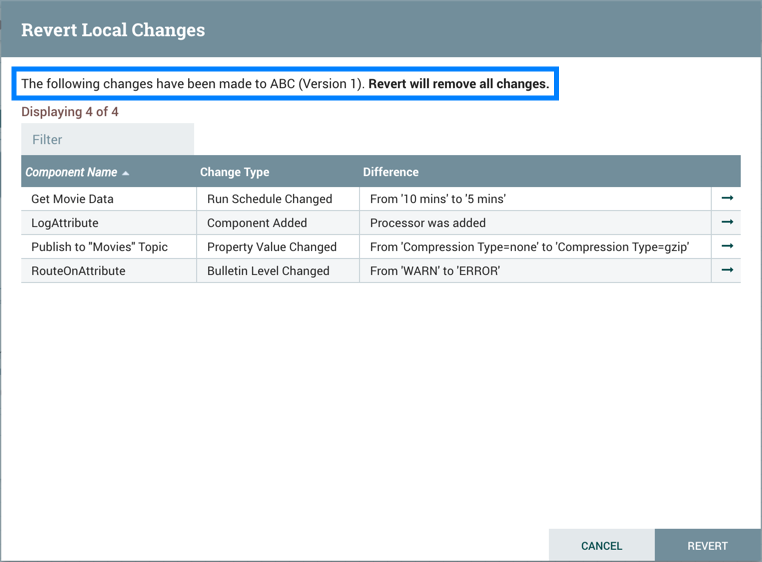
您可以通过选择去其行中的""图标来导航到组件。
如管理本地更改部分中所述,有些例外可以将可更改的本地更改作为操作。此外,对同一属性的多次更改将仅显示为列表中的一个更改,因为更改是通过区分进程组的当前状态和"还原本地更改"对话框中记录的进程组的已保存版本来确定的。
提交本地更改
要提交和保存流版本,请从上下文菜单中选择"Version→Commit local changes"。在保存流版本对话框中,根据需要添加注释,然后选择"Save"。
更改版本
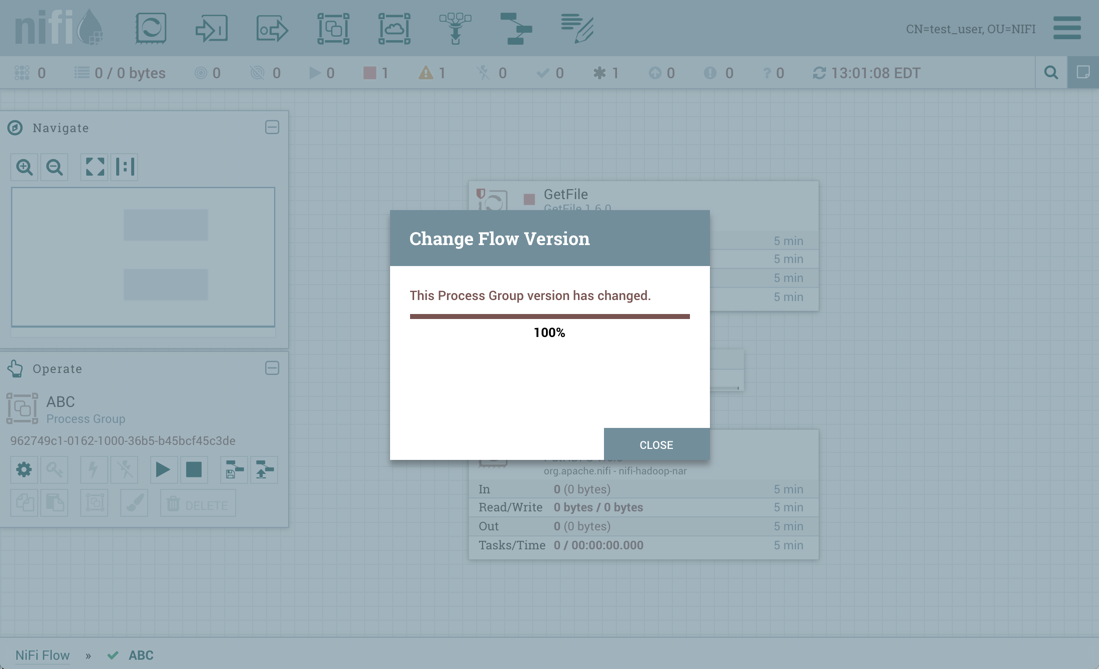
要更改流的版本,请右键单击版本化的流程组,然后选择"Version→Change version"。
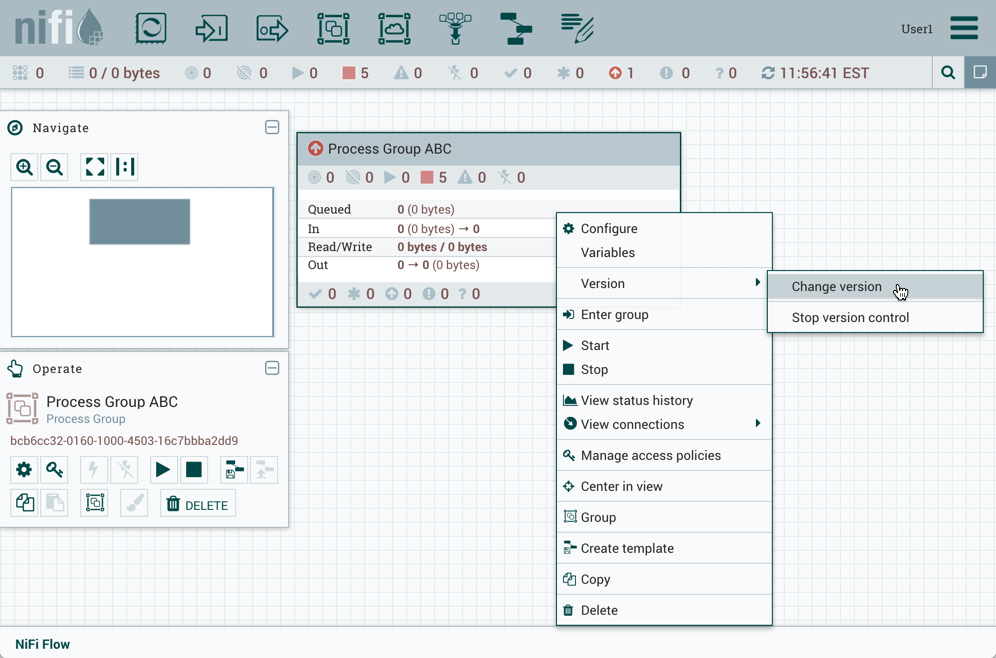
在更改版本对话框中,选择所需的版本并选择"Change":
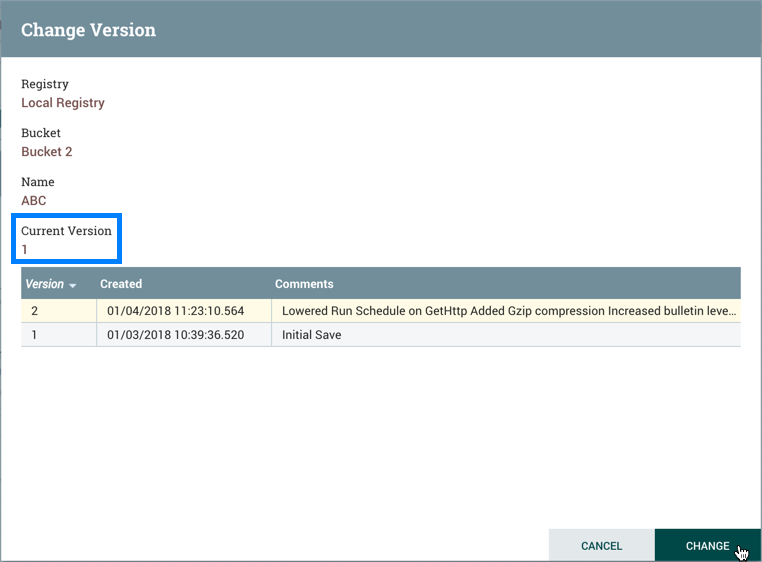
流的版本已更改:
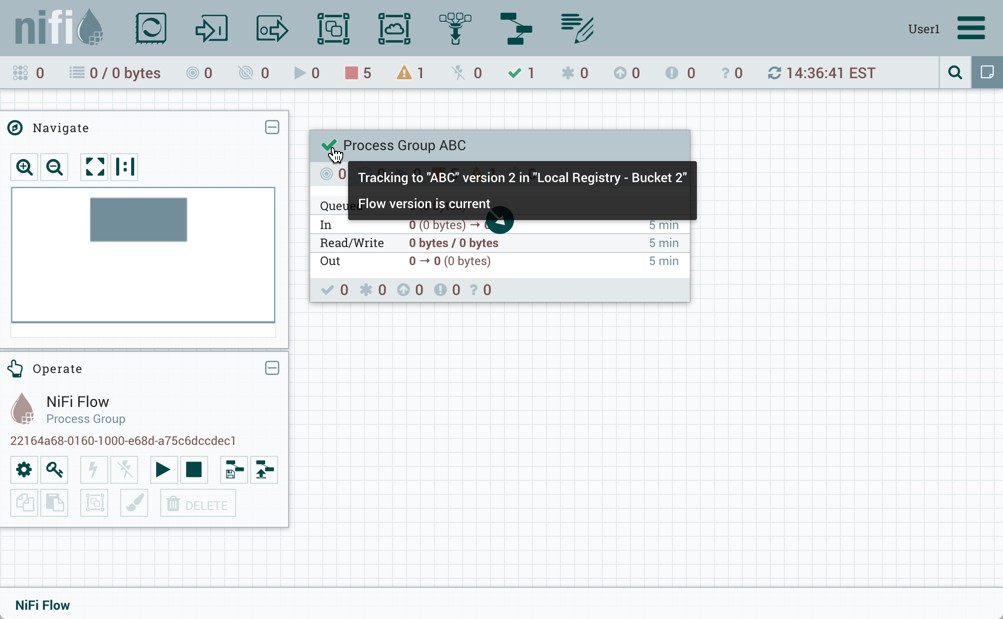
在所示示例中,版本化流程从较旧版本升级到较新版本。但是,版本化流程也可以回滚到旧版本。
要使"更改版本"成为可用选择,需要还原对进程组的本地更改。
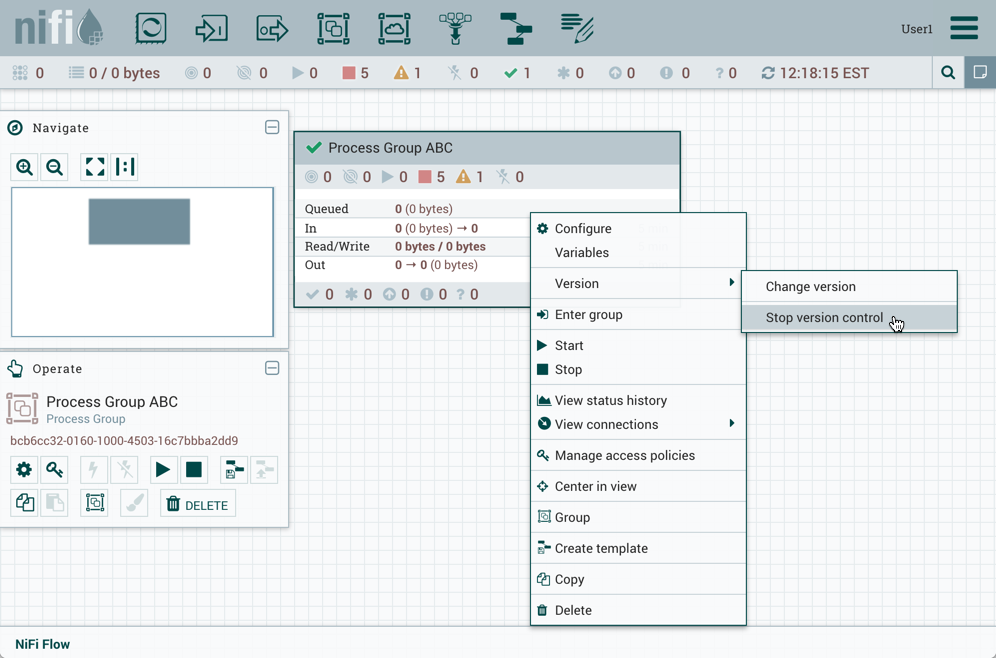
停止版本控制
要停止对流的版本控制,请右键单击版本化的进程组,然后选择"Version→Stop version control":
在停止版本控制对话框中,选择"Disconnect"。
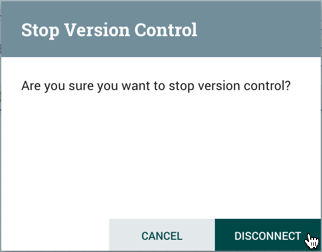
确认从版本控制中删除进程组。

嵌套版本化流程
版本化进程组可以包含其他版本化进程组。但是,如果父进程组包含也具有本地更改的子进程组,则无法还原或保存对父进程组的本地更改。必须首先还原子进程组,或者为要在父进程组上执行的操作提交其更改。
版本化流程中的变量
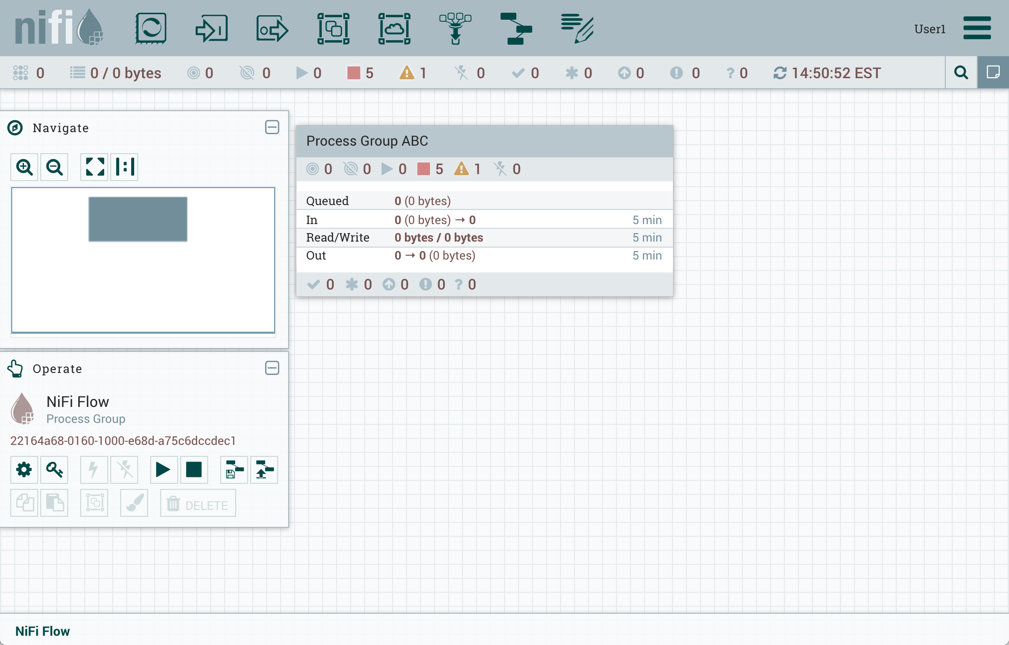
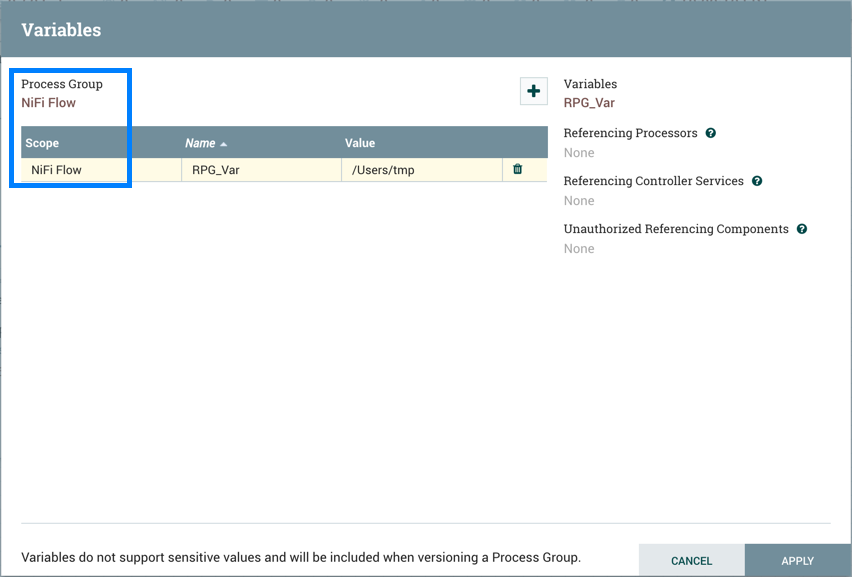
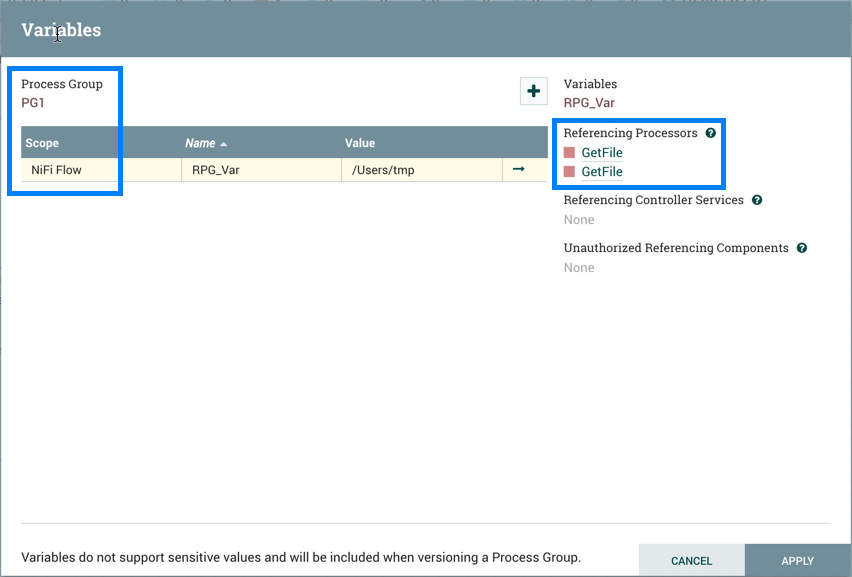
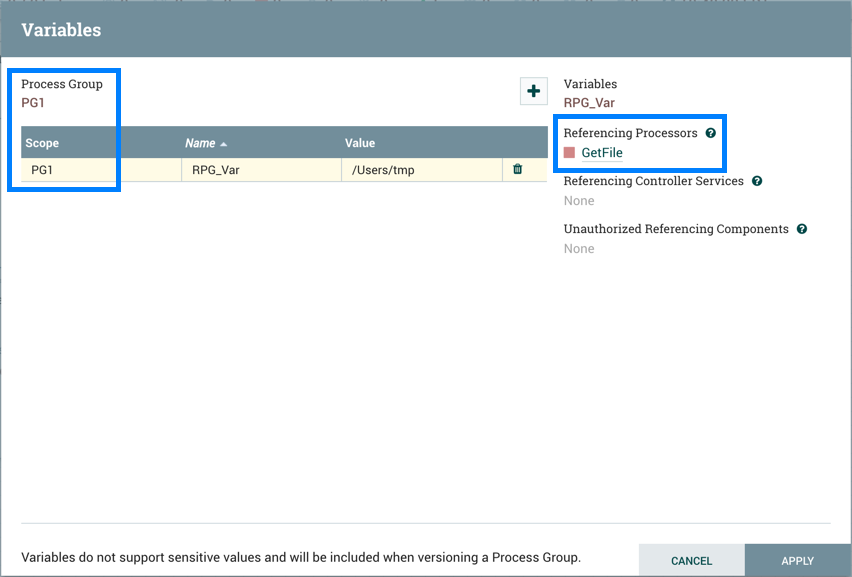
当进程组置于版本控制之下时,会包含变量。如果导入的版本化流引用了未在版本化进程组中定义的变量,则在变量存在时保留引用。如果引用的变量不存在,则将在进程组中定义变量的副本。为了说明,假设变量"RPG_Var"在根进程组中定义:
创建进程组PG1:
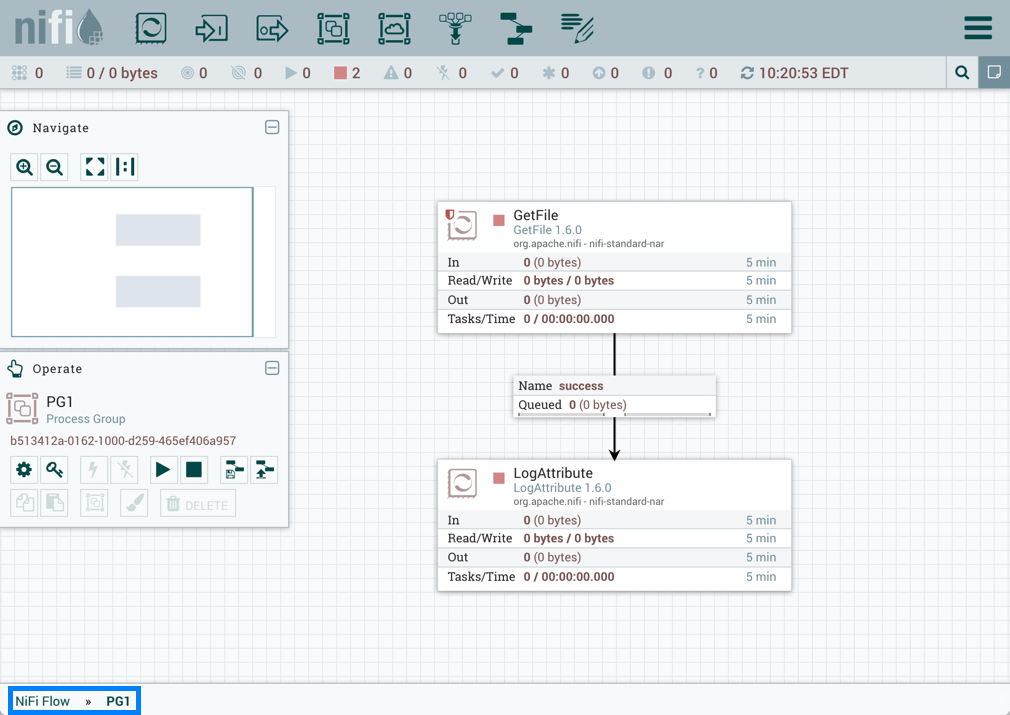
PG1中的GetFile处理器引用变量"RPG_Var":
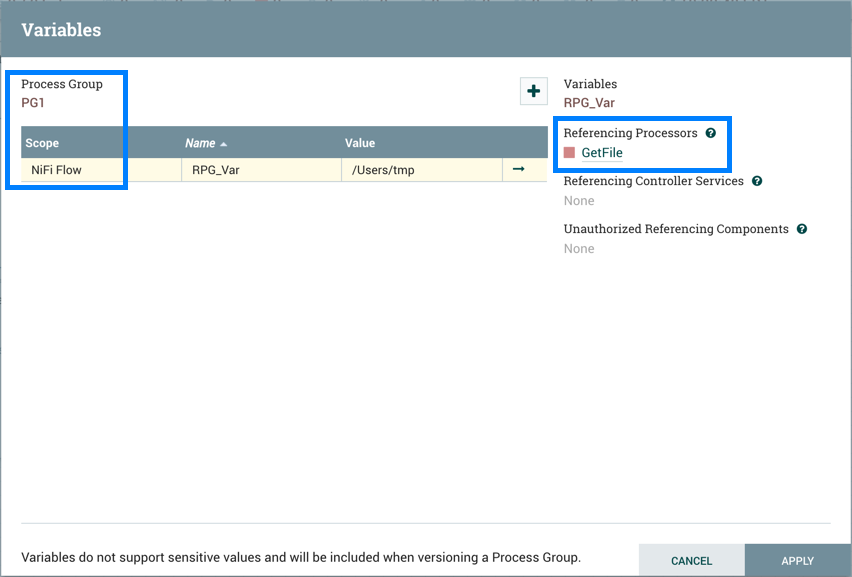
PG1保存为版本化流程:
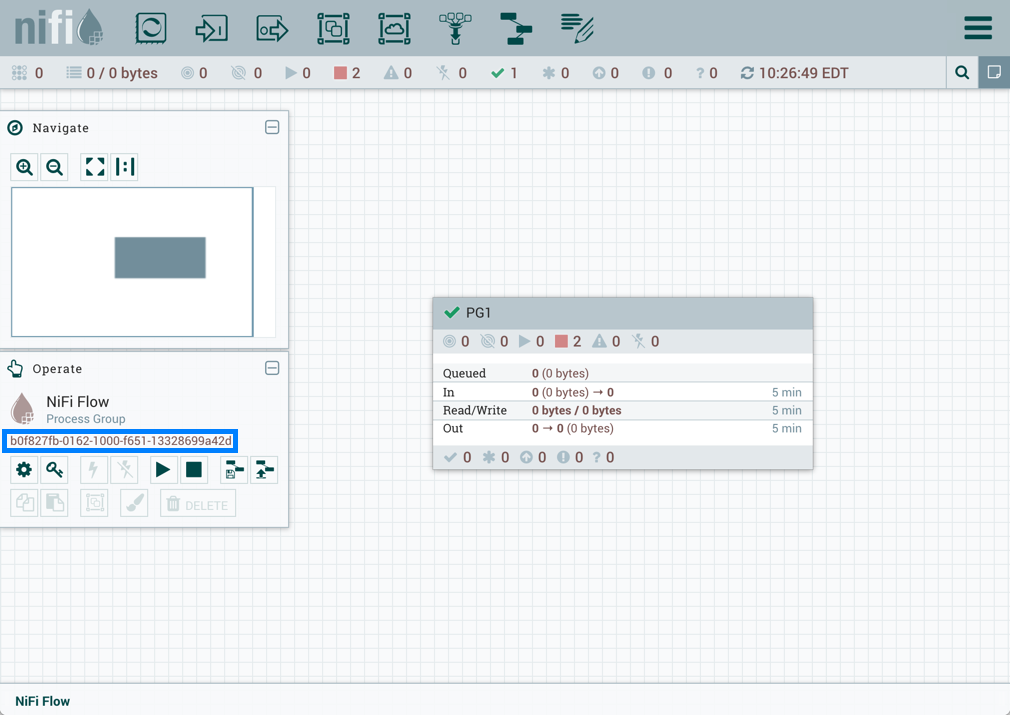
如果PG1版本化流程导入到同一个NiFi实例中:
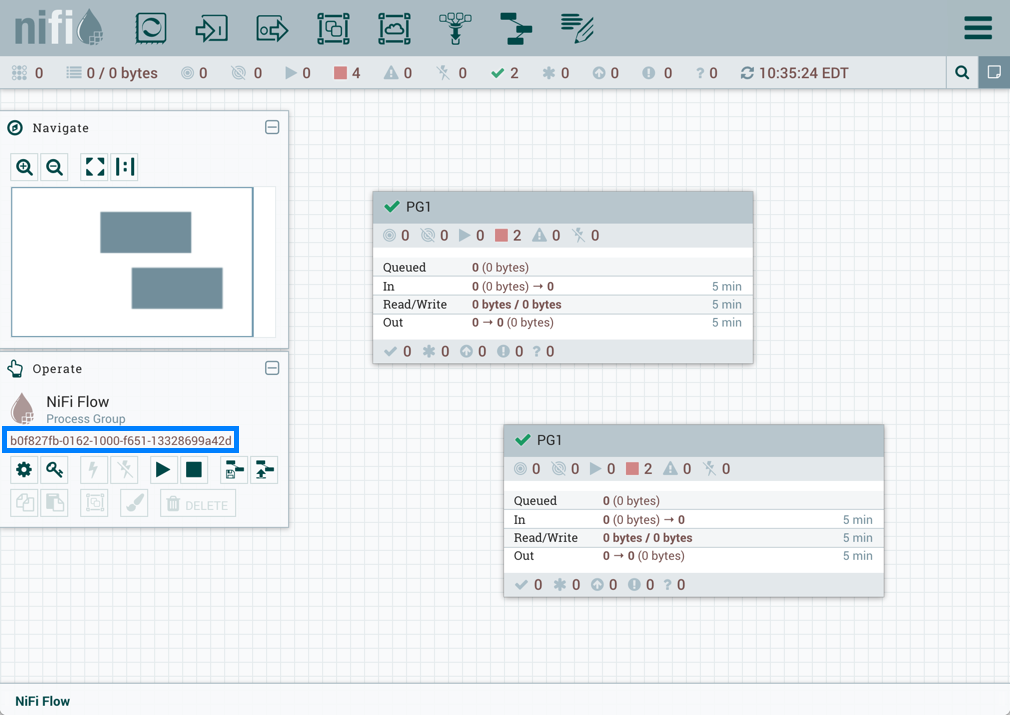
添加的GetFile处理器还将引用根进程组中存在的"RPG_Var"变量:
如果PG1版本化流程导入到不存在"RPG_Var"的不同NiFi实例中:
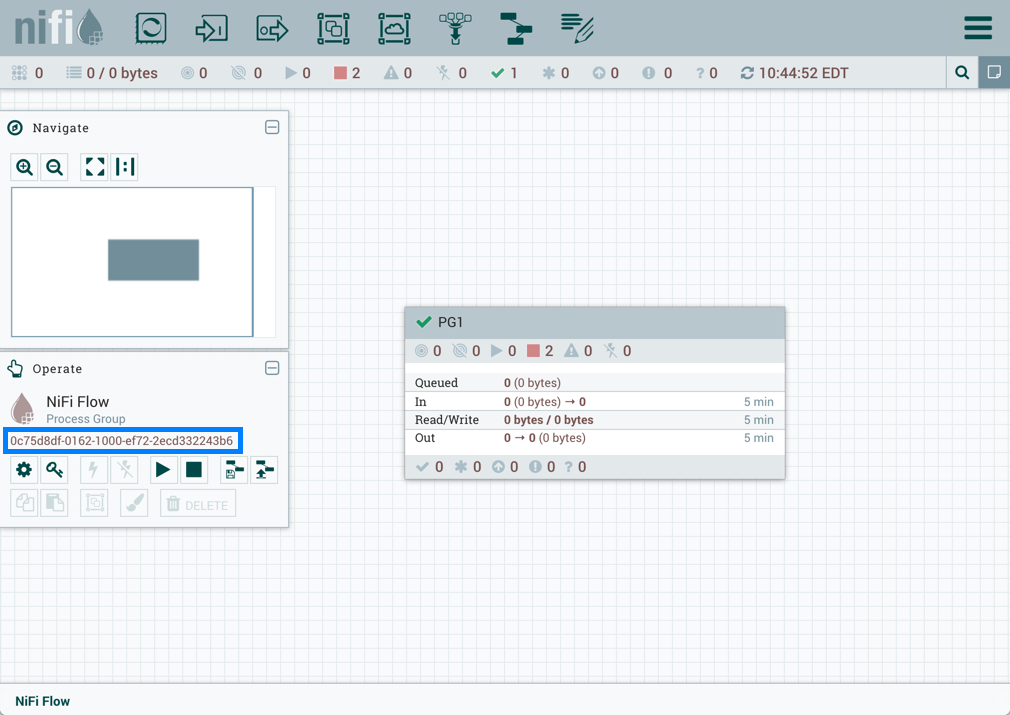
在PG1进程组中创建"RPG_Var"变量:
版本化流程中受限制的组件
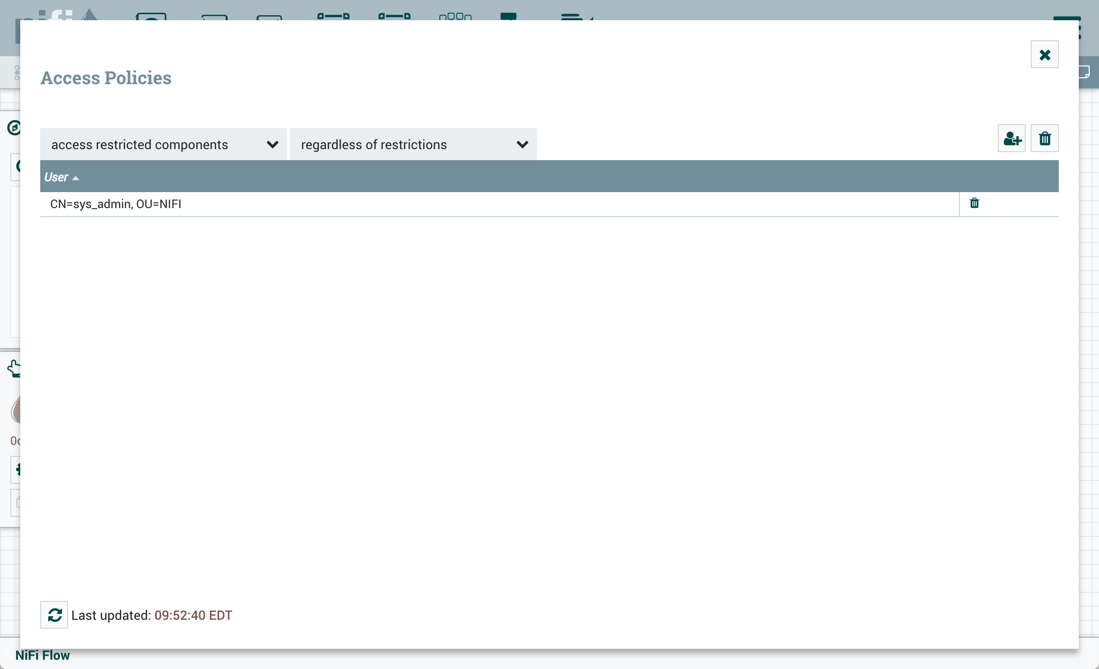
要导入版本化流程或还原版本化流程中的本地更改,用户必须能够访问版本化流程中的所有组件。因此,如果要在版本化流程中使用受限组件,则建议在根进程组级别创建受限组件。让我们通过一些示例来说明此配置的好处。假设如下:
有两个用户"sys_admin"和"test_user"可以访问查看和修改根进程组。
"sys_admin"可以访问所有受限制的组件。
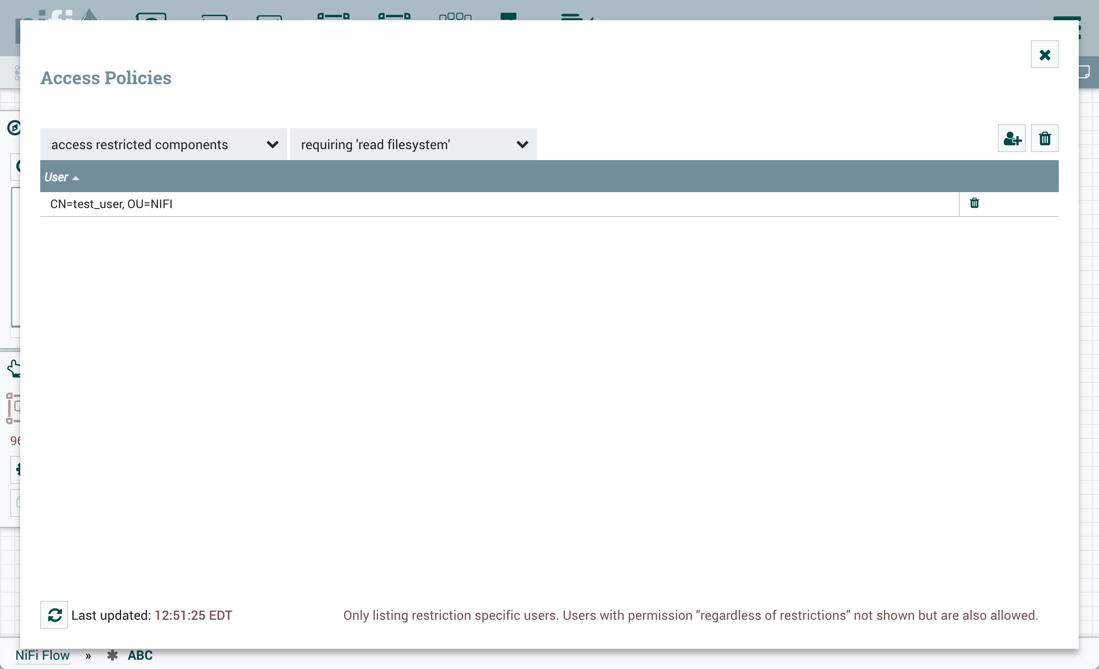
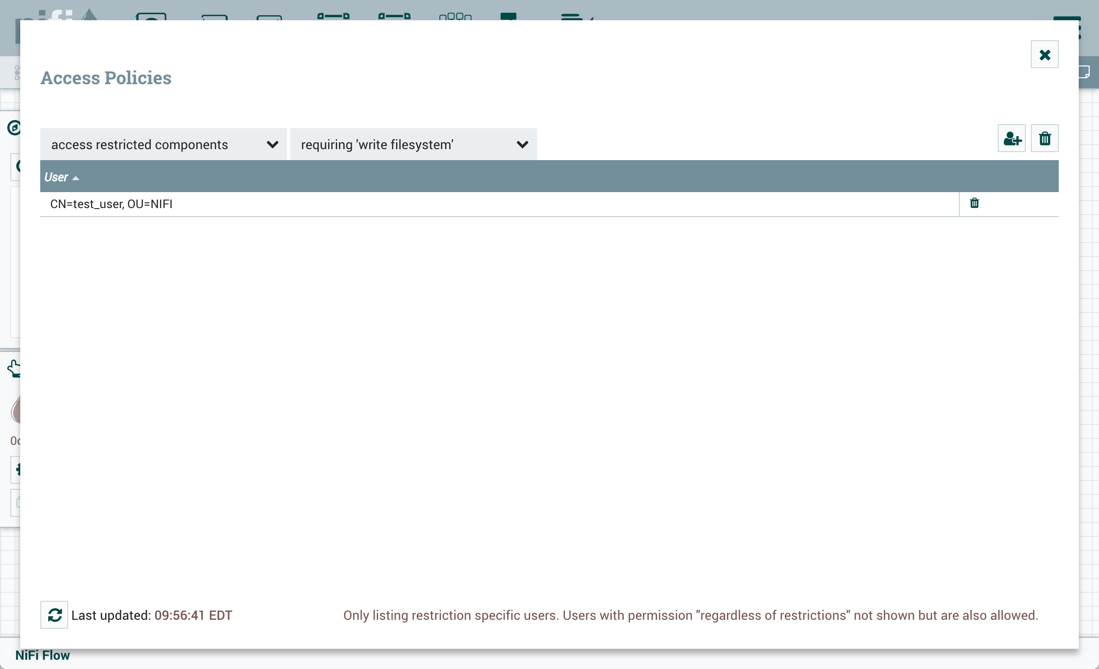
- "test_user"可以访问需要"read filesystem"和"write filesystem"的受限组件。
根进程组中创建的受限制的控制器服务
在第一个示例中,sys_admin在根进程组级别创建KeytabCredentialsService控制器服务。
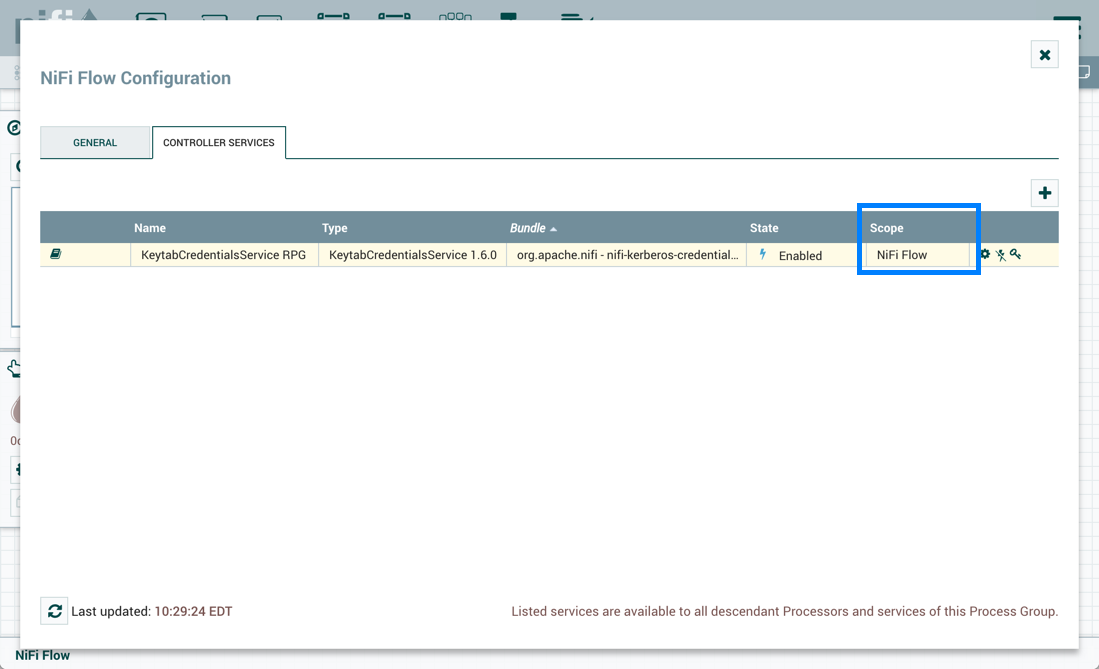
KeytabCredentialService控制器服务是一个受限制的组件,需要"access keytab"权限:
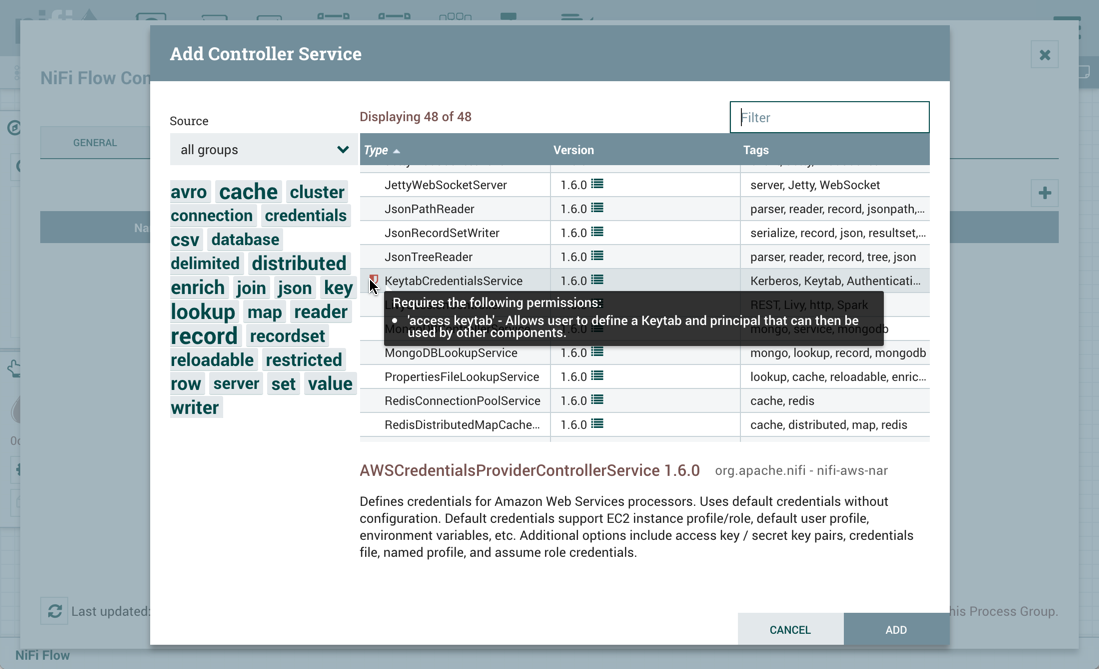
Sys_admin使用GetFile和PutHDFS处理器创建一个包含流的进程组ABC:
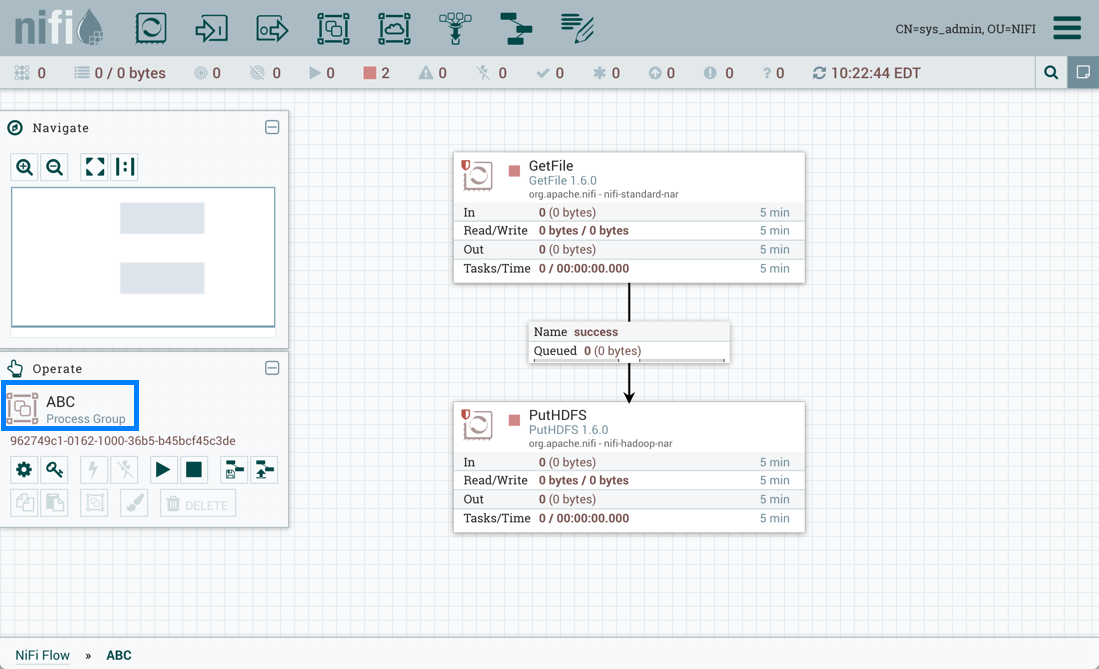
GetFile处理器是一个受限制的组件,需要"read filesystem"和"write filesystem"权限:
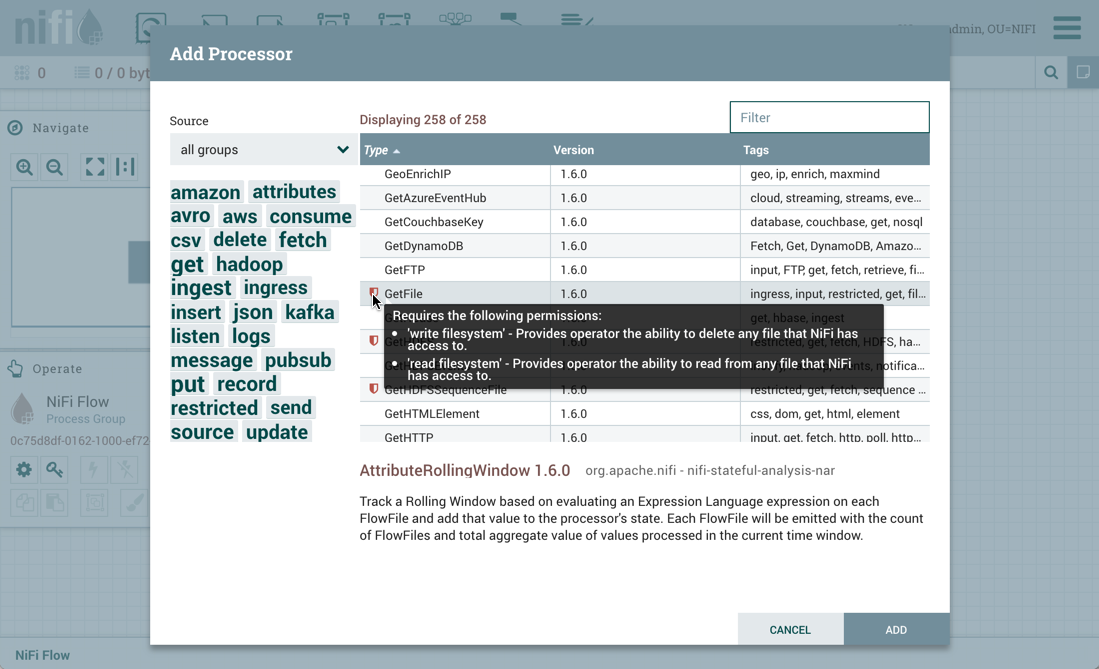
PutHDFS是一个受限制的组件,需要"read filesystem"权限:
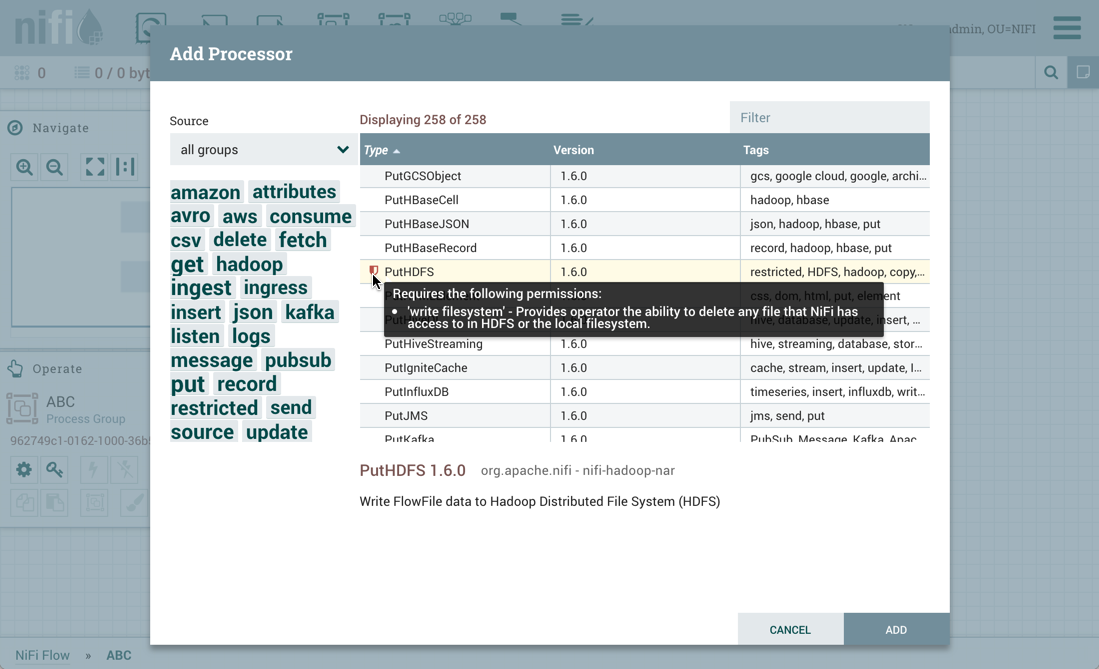
PutHDFS处理器配置为使用根进程组级别KeytabCredentialsService控制器服务:
Sys_admin将进程组保存为版本化流:
Test_user通过删除KeytabCredentialsService控制器服务来更改流程:
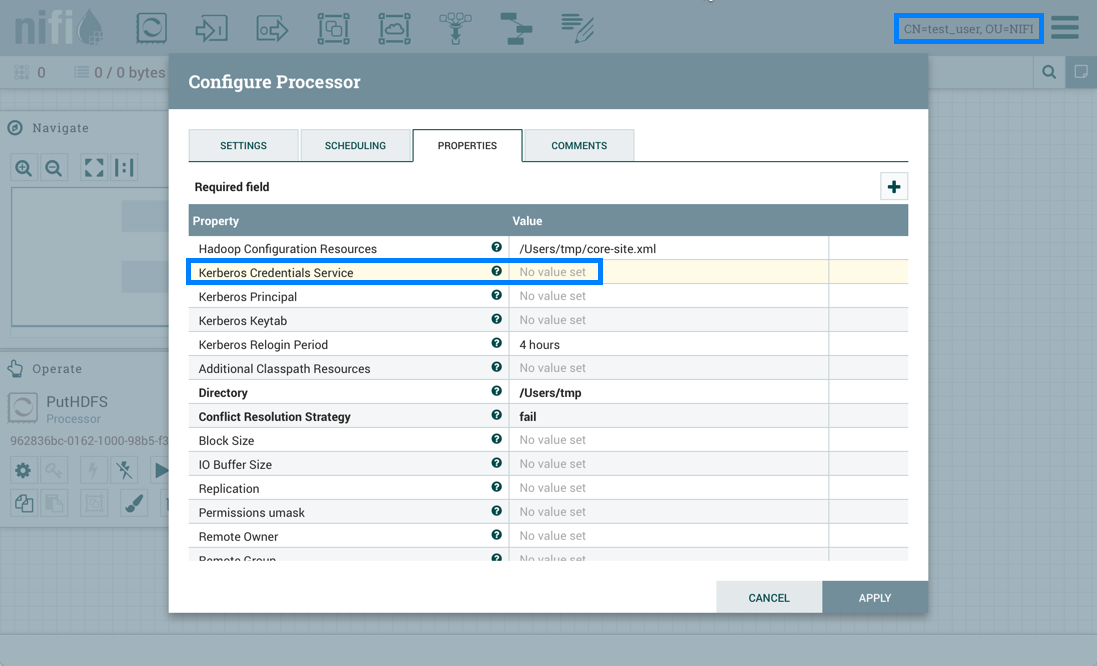
如果test_user选择还原此更改:
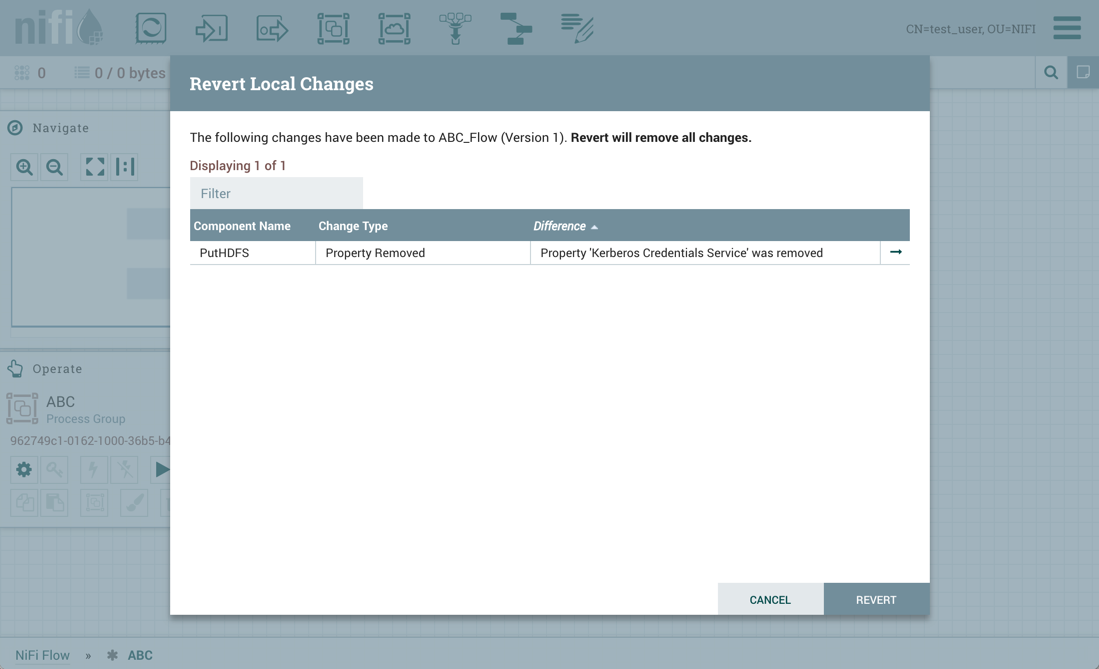
恢复成功:
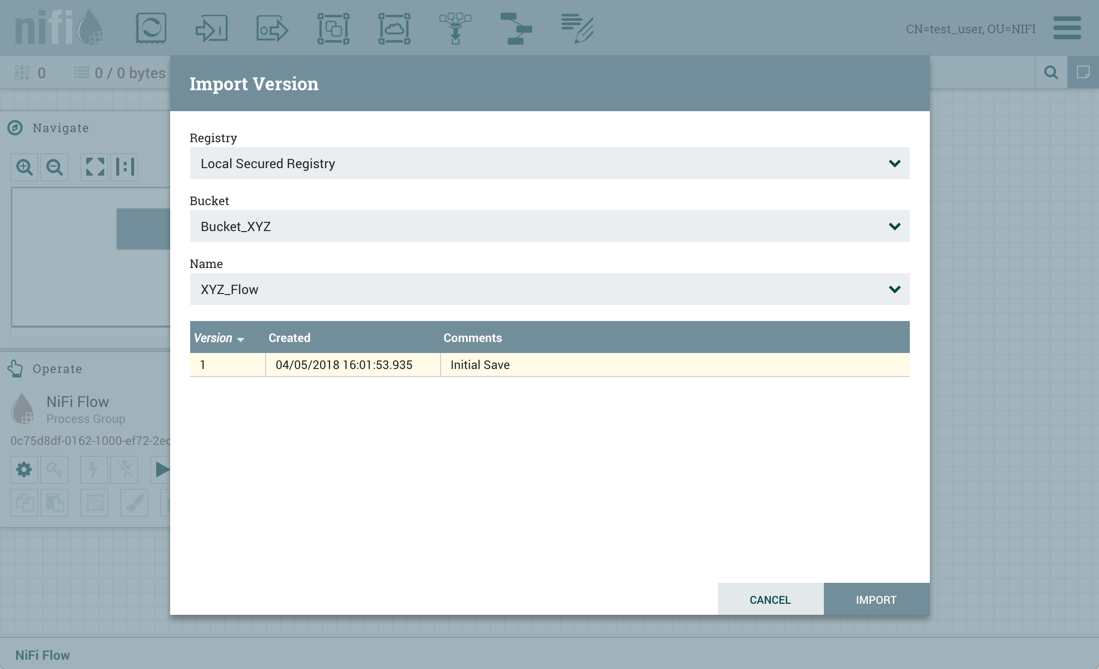
此外,如果test_user选择导入ABC版本化流程:
导入成功:
流程组中创建的受限制的控制器服务
现在,考虑第二种情况,即在进程组级别创建控制器服务。
Sys_admin创建一个进程组XYZ:
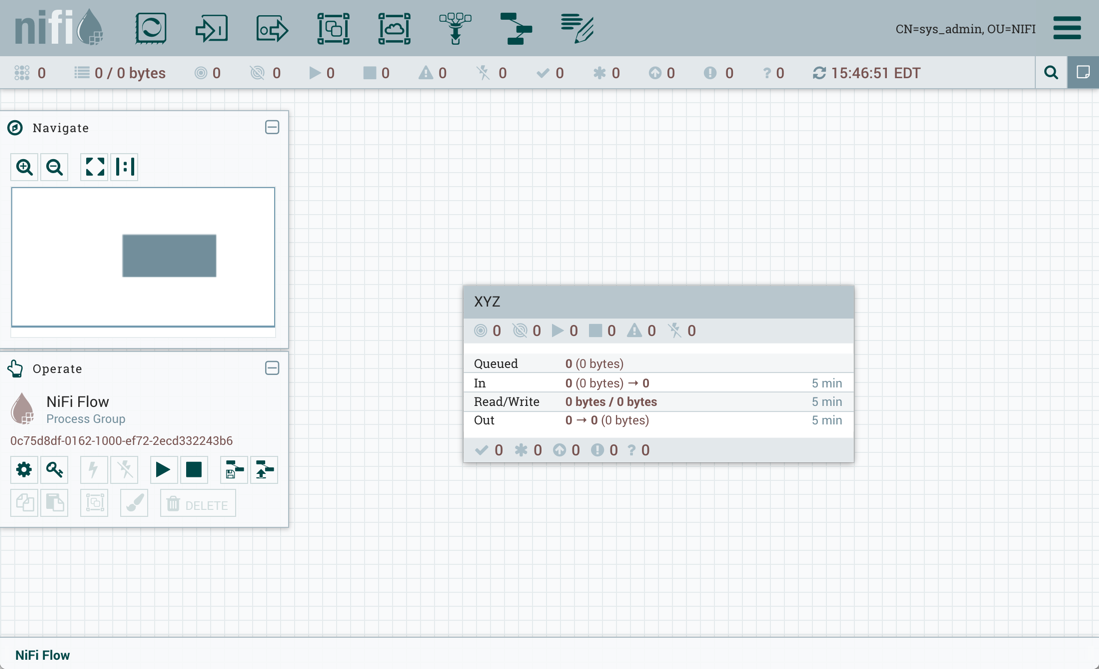
Sys_admin在进程组级别创建KeytabCredentialsService控制器服务:
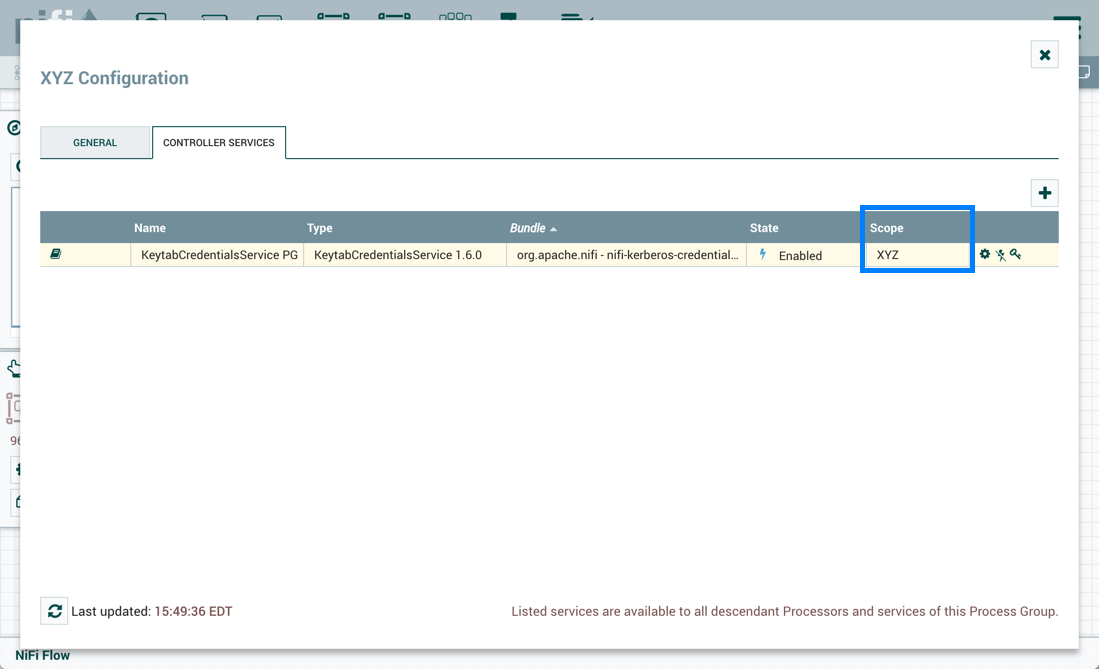
在进程组中创建相同的GetFile和PutHDFS流:
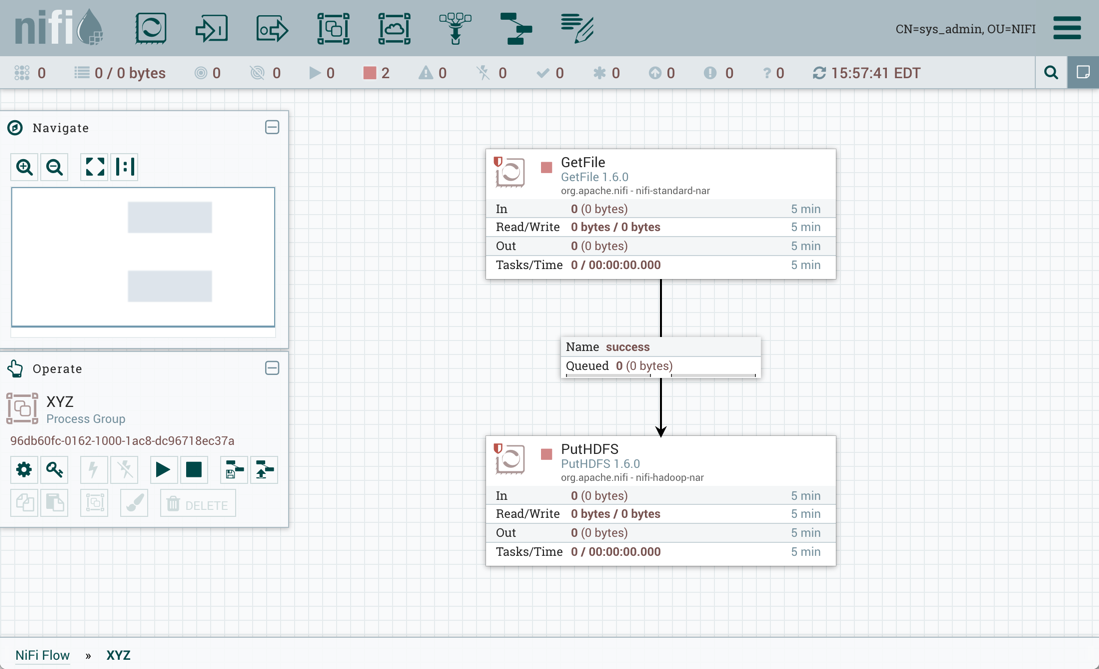
但是,PutHDFS现在引用了进程组级控制器服务:
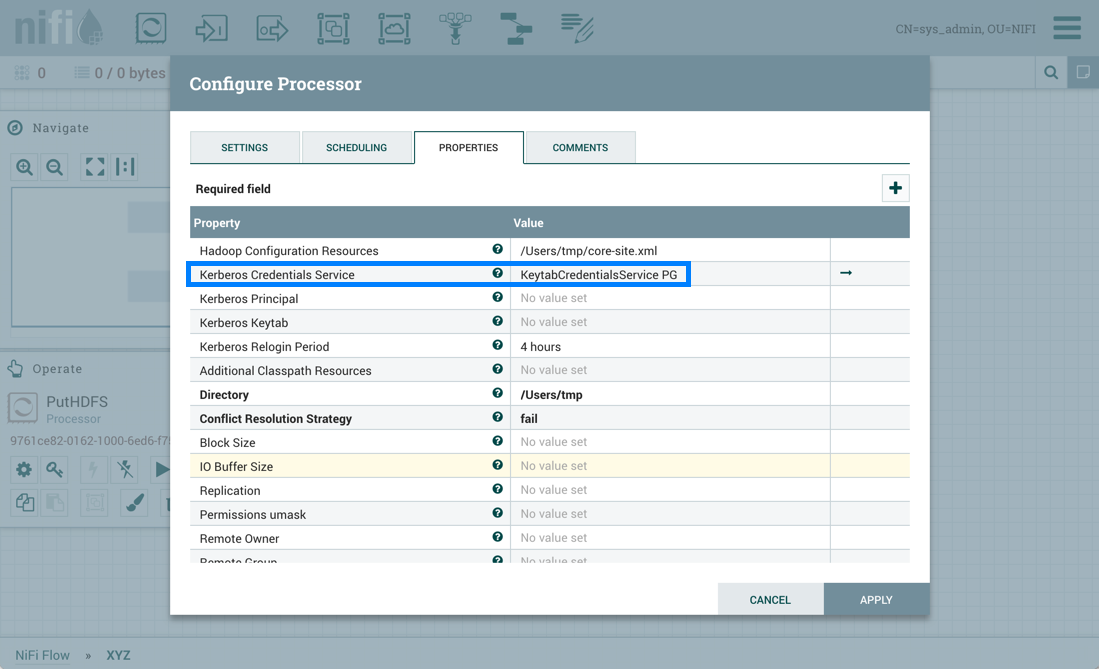
Sys_admin将进程组保存为版本化流。
Test_user通过删除KeytabCredentialsService控制器服务来更改流。但是,使用此配置,如果test_user尝试还原此更改:
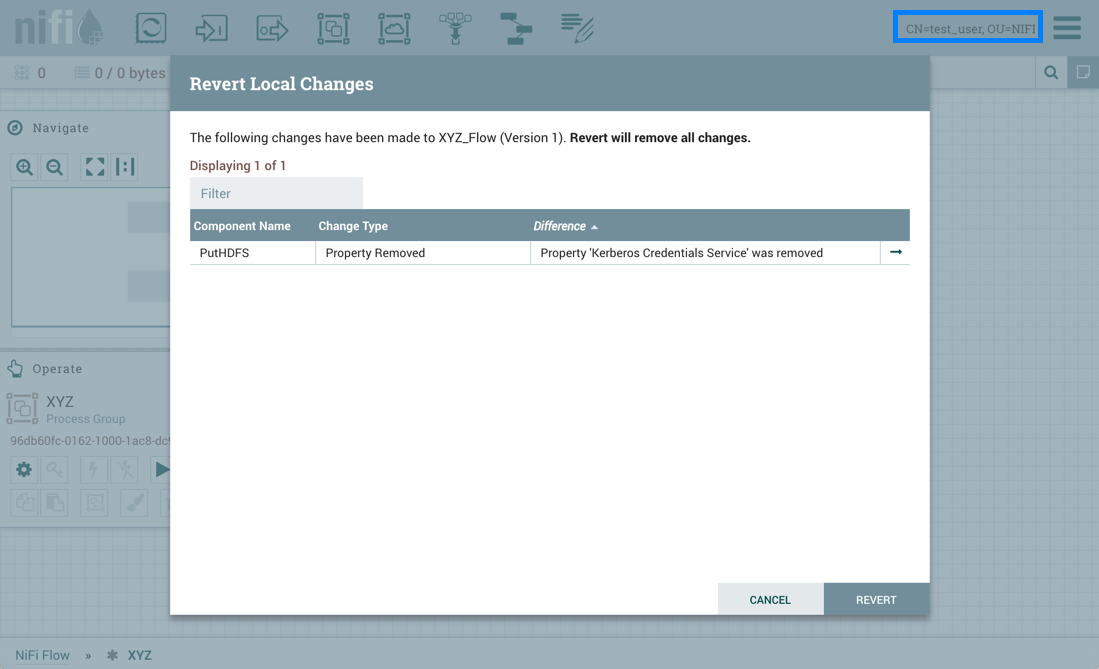
恢复不成功,因为test_user没有KeytabCredentialService控制器服务所需的"访问密钥表"权限:
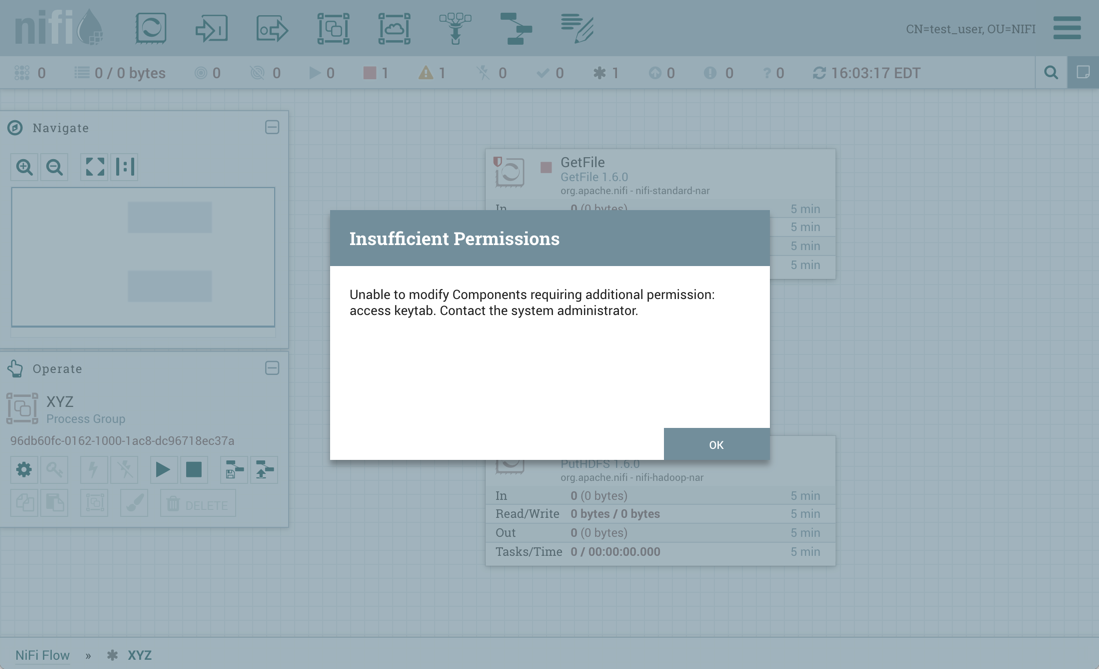
同样,如果test_user尝试导入XYZ版本化流程:
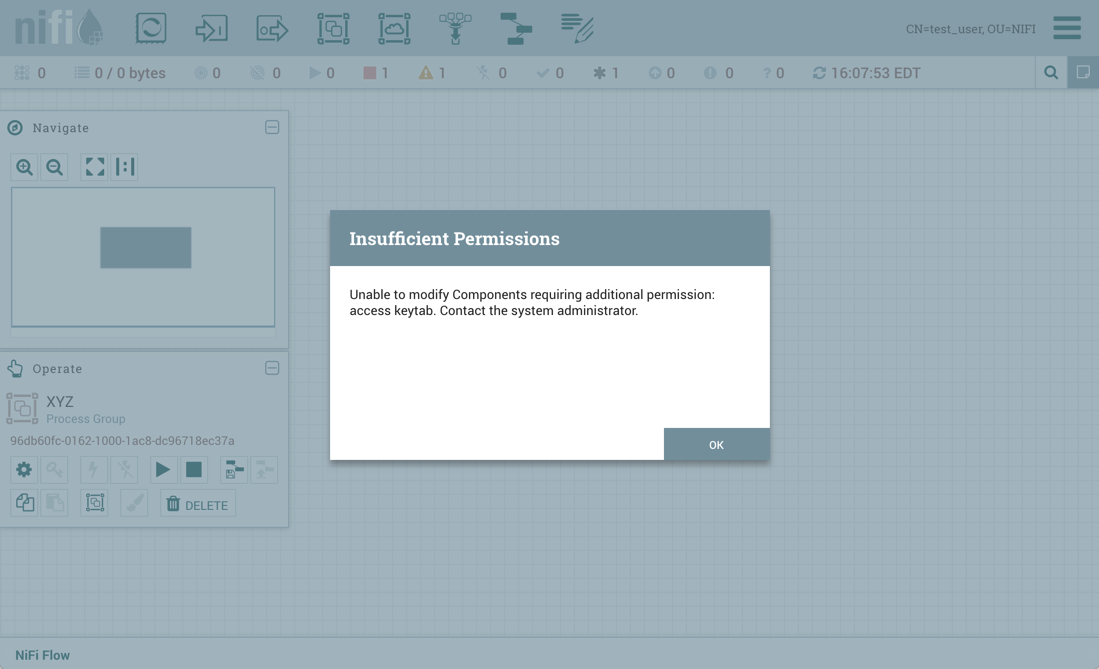
导入失败:
模板
DFM能够使用NiFi构建非常大且复杂的DataFlow。这是通过使用基本组件实现的:处理器,漏斗,输入/输出端口,进程组和远程进程组。这些可以被认为是构建DataFlow的最基本构建块。但是,有时候,如果需要重复多次相同的逻辑,使用这些小的构建块会变得乏味。
为了解决这个问题,NiFi提供了模板的概念。模板是将这些基本构建块组合成更大的构建块的一种方式。创建DataFlow后,可以将其中的一部分组成模板。然后可以将此模板拖到画布上,也可以将其导出为XML文件并与其他人共享。然后可以将从其他人处接收的模板导入NiFi实例并拖动到画布上。
创建模板
要创建模板,请选择要作为模板一部分的组件,然后单击 操作选项板中的 Create Template( )按钮(有关操作选项板的更多信息,请参阅NiFi用户界面)。
)按钮(有关操作选项板的更多信息,请参阅NiFi用户界面)。
单击此按钮而不选择任何内容将创建一个包含当前进程组的所有内容的模板。这意味着在根进程组上创建一个没有选择任何内容的模板将创建一个包含整个流的模板。
单击此按钮后,将提示用户提供模板的名称和可选说明。每个模板都必须具有唯一的名称。输入名称和可选说明后,单击该Create按钮将生成模板并通知用户模板已成功创建,或者如果由于某种原因无法创建模板,则提供相应的错误消息。
请务必注意,如果任何Templated处理器具有敏感属性(例如密码),则该敏感属性的值不会包含在模板中。因此,在将模板拖动到画布上时,如果新创建的处理器缺少其敏感属性的值,则它们可能无效。此外,如果连接的源或目标未包含在模板中,则在制作模板时选择的任何连接都不包含在模板中。
导入模板
在收到从另一个NiFi导出的模板后,使用该模板所需的第一步是将模板导入到此NiFi实例中。您可以将模板导入到具有相应授权的任何Process Group。
在Operate Palette中,单击Upload Template( )按钮(有关Operate Palette的更多信息,请参阅NiFi用户界面)。这将显示"上载模板"对话框。单击查找图标并使用文件选择对话框选择要上载的模板文件。选择文件,然后单击Upload。单击该Upload按钮将尝试将模板导入此NiFi实例。如果导入模板时出现问题,上载模板对话框将更新为显示成功或错误消息。
)按钮(有关Operate Palette的更多信息,请参阅NiFi用户界面)。这将显示"上载模板"对话框。单击查找图标并使用文件选择对话框选择要上载的模板文件。选择文件,然后单击Upload。单击该Upload按钮将尝试将模板导入此NiFi实例。如果导入模板时出现问题,上载模板对话框将更新为显示成功或错误消息。
实例化模板
创建模板(请参阅创建模板)或导入模板(请参阅导入模板)后,就可以将其实例化,或添加到画布中。这是通过将模板图标()从组件工具栏(请参阅NiFi用户界面)拖到画布上来完成的。
这将显示一个对话框,用于选择要添加到画布的模板。选择要添加的模板后,只需单击Add按钮即可。模板将添加到画布中,模板的左上角放置在用户放置模板图标的任何位置。
这使得新实例化的模板的内容被选中。如果出现错误,并且不再需要此模板,则可能会将其删除。
管理模板
NiFi模板最强大的功能之一是能够轻松地将模板导出到XML文件并导入已导出的模板。这提供了一种非常简单的机制,用于与其他人共享部分DataFlow。您可以从全局菜单中选择模板(请参阅NiFi用户界面)以打开一个对话框,其中显示当前可用的所有模板,过滤模板以仅查看感兴趣的模板,导出和删除模板
导出模板
创建模板后,可以在"模板管理"页面中与其他人共享。要导出模板,请在表中找到模板。如果有几个可用的话,右上角的过滤器可用于帮助查找相应的模板。然后单击Download按钮( )。这会将模板作为XML文件下载到您的计算机。然后可以将此XML文件发送给其他人并导入到其他NiFi实例中(请参阅导入模板)。
)。这会将模板作为XML文件下载到您的计算机。然后可以将此XML文件发送给其他人并导入到其他NiFi实例中(请参阅导入模板)。
删除模板
一旦确定不再需要模板,就可以从模板管理页面轻松删除它。要删除模板,请在表格中找到它(如果有几个可用,可以使用右上角的过滤器查找相应的模板)并单击Delete按钮()。这将提示确认。确认删除后,模板将从此表中删除,不再可用于添加到画布。
数据来源
在监视数据流时,用户通常需要一种方法来确定特定数据对象(FlowFile)的发生情况。NiFi的Data Provenance页面提供了该信息。由于NiFi在对象流经系统时记录和索引数据来源详细信息,因此用户可以执行搜索,进行故障排除并实时评估数据流合规性和优化等内容。默认情况下,NiFi每五分钟更新一次此信息,但这是可配置的。
要访问Data Provenance页面,请从Global Menu中选择"Data Provenance"。这将打开一个对话框窗口,允许用户查看可用的最新数据源文件信息,搜索特定项目的信息,并过滤搜索结果。还可以打开其他对话框窗口以查看事件详细信息,在数据流中的任何位置重放数据,以及查看数据的沿袭或流程路径的图形表示。(这些功能将在下面详细介绍。)
启用授权后,访问Data Provenance信息需要"查询出处"全局策略以及生成事件的组件的"查看出处"组件策略。此外,访问包含FlowFile属性和内容的事件详细信息需要为生成事件的组件"查看数据"组件策略。
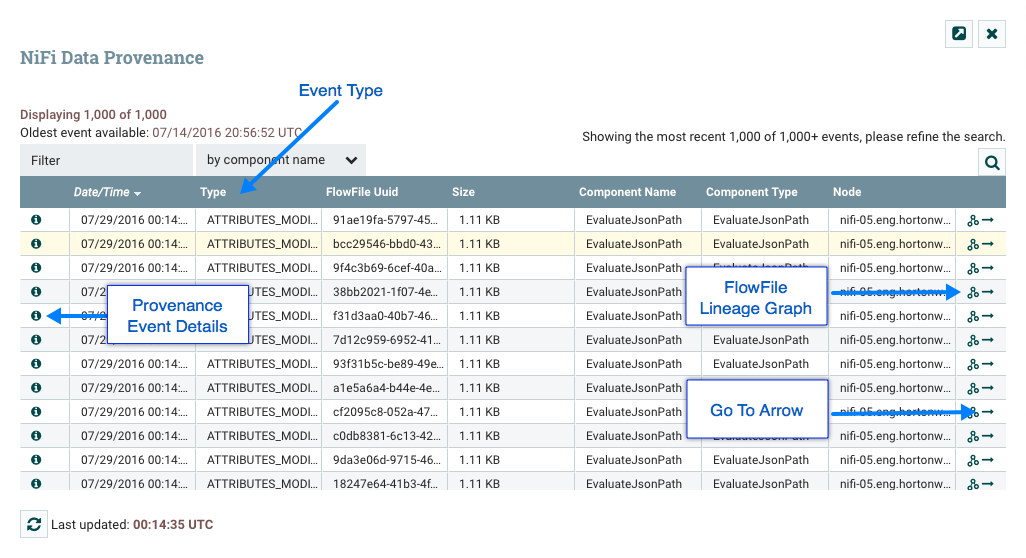
种源事件
以某种方式处理FlowFile的数据流中的每个点都被视为"起源事件"。根据数据流设计,会发生各种类型的起源事件。例如,当数据进入流程时,会发生RECEIVE事件,并且当数据从流程中发出时,会发生SEND事件。可能会发生其他类型的处理事件,例如克隆数据(CLONE事件),路由(ROUTE事件),修改(CONTENT_MODIFIED或ATTRIBUTES_MODIFIED事件),拆分(FORK事件),与其他数据对象(JOIN事件)相结合,并最终从流程中删除(DROP事件)。
起源事件类型是:
| 种源事件 | 描述 |
|---|---|
| ADDINFO | 当添加其他信息(例如新链接到新URI或UUID)时,表示源项事件 |
| ATTRIBUTES_MODIFIED | 表示以某种方式修改了FlowFile的属性 |
| CLONE | 表示FlowFile与其父FlowFile完全相同 |
| CONTENT_MODIFIED | 表示以某种方式修改了FlowFile的内容 |
| CREATE | 表示FlowFile是从未从远程系统或外部进程接收的数据生成的 |
| DOWNLOAD | 表示用户或外部实体下载了FlowFile的内容 |
| DROP | 表示由于对象到期之外的某些原因导致对象生命结束的起源事件 |
| EXPIRE | 表示由于未及时处理对象而导致对象生命结束的起源事件 |
| FETCH | 指示使用某些外部资源的内容覆盖FlowFile的内容 |
| FORK | 表示一个或多个FlowFiles是从父FlowFile派生的 |
| JOIN | 表示单个FlowFile是通过将多个父FlowFiles连接在一起而派生的 |
| RECEIVE | 表示从外部进程接收数据的来源事件 |
| REPLAY | 表示重放FlowFile的originance事件 |
| ROUTE | 表示FlowFile已路由到指定的关系,并提供有关FlowFile路由到此关系的原因的信息 |
| SEND | 表示将数据发送到外部进程的originance事件 |
| UNKNOWN | 表示原产地事件的类型未知,因为尝试访问该事件的用户无权知道该类型 |
搜索Events
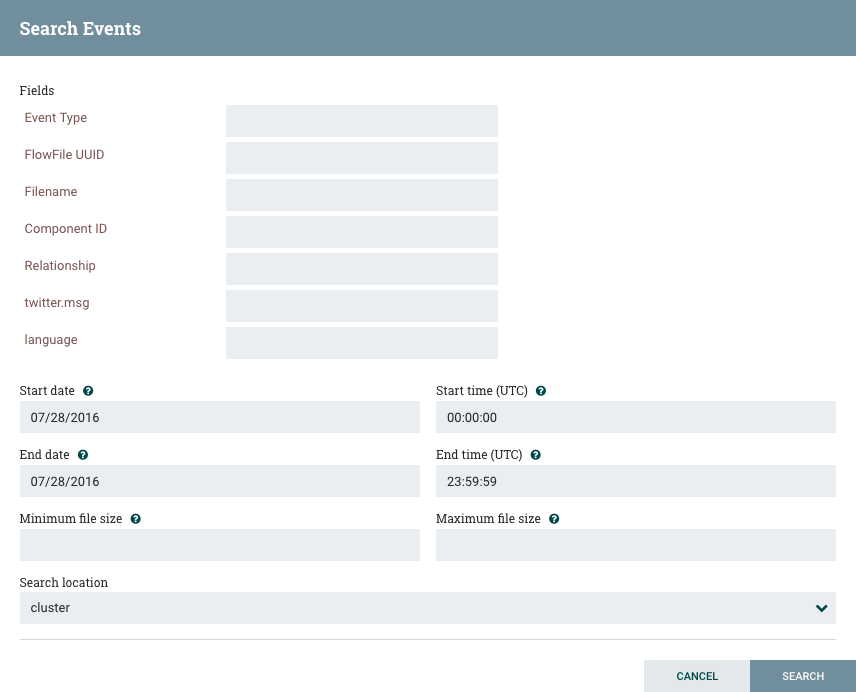
在Data Provenance页面中执行的最常见任务之一是搜索给定的FlowFile以确定它发生了什么。为此,请单击数据源页面右上角的Search按钮。这将打开一个对话框窗口,其中包含用户可以为搜索定义的参数。参数包括感兴趣的处理事件,区分FlowFile或产生事件的组件的特征,搜索的时间范围以及FlowFile的大小。
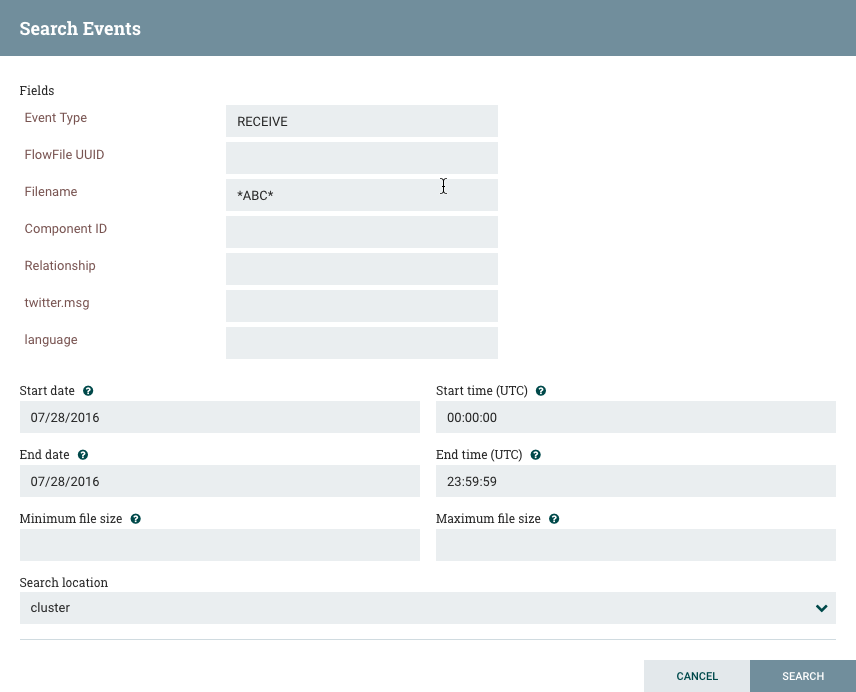
例如,要确定是否收到特定的FlowFile,请搜索"RECEIVE"的事件类型,并包含FlowFile的标识符,例如其uuid或文件名。星号(*)可用作任意数量字符的通配符。因此,要确定在2015年1月6日的任何时间是否收到了文件名中任何位置带有"ABC"的FlowFile,可以执行下图所示的搜索:
Event详情
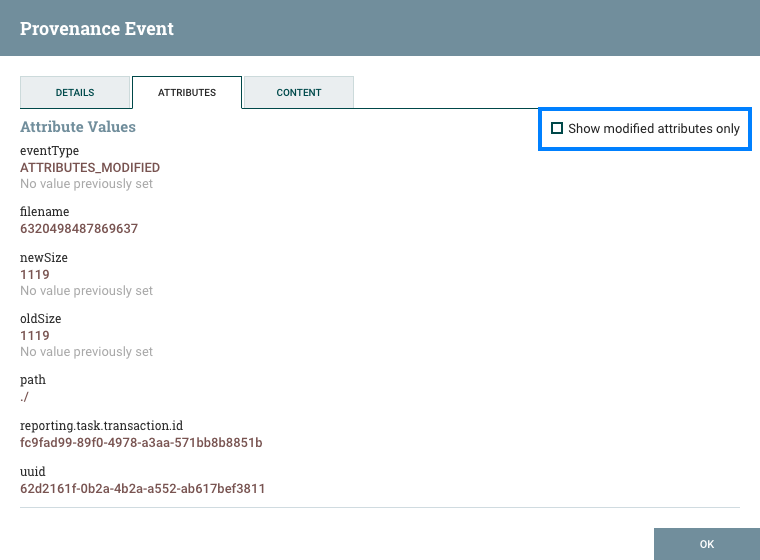
在Data Provenance页面的最左侧列中View Details,每个事件都有一个图标()。单击此按钮将打开一个对话框窗口,其中包含三个选项卡:详细信息,属性和内容。
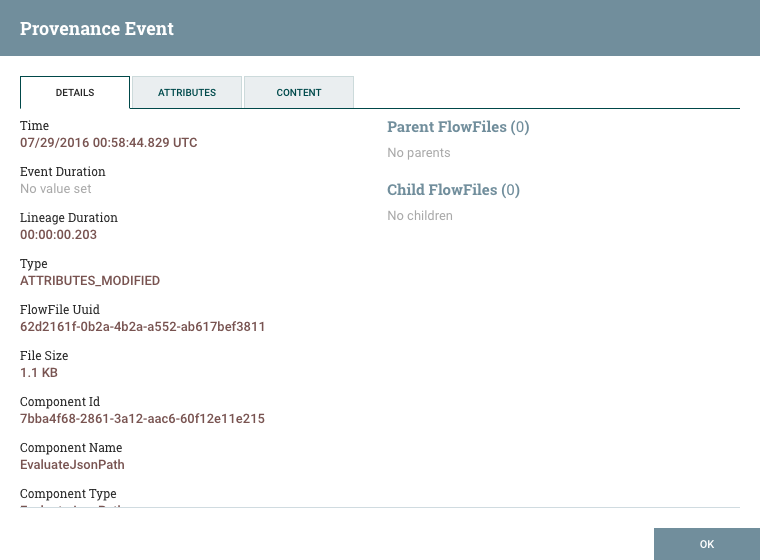
详细信息选项卡显示有关事件的各种详细信息,例如事件发生的时间,事件的类型以及生成事件的组件。显示的信息将根据事件类型而有所不同。此选项卡还显示有关已处理的FlowFile的信息。除了显示在详细信息选项卡左侧的FlowFile的UUID之外,与详细信息选项卡右侧显示的与该FlowFile相关的任何父文件或子级FlowFile的UUID也显示在该详细信息选项卡的右侧。
属性选项卡显示流程中该点上FlowFile中存在的属性。为了仅查看由于处理事件而修改的属性,用户可以选择属性选项卡右上角仅显示已修改旁边的复选框。
重播FlowFile
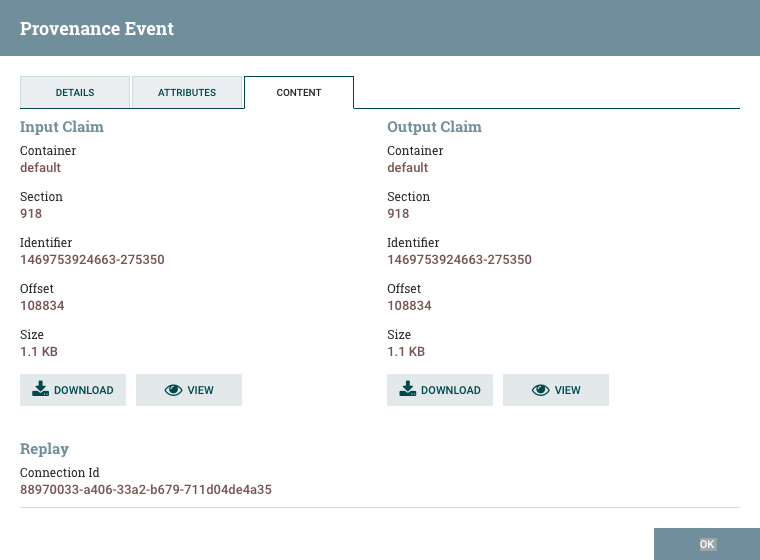
DFM可能需要在数据流中的某个点检查FlowFile的内容,以确保按预期处理它。如果没有正确处理,DFM可能需要调整数据流并再次重放FlowFile。查看详细信息对话框窗口的内容选项卡是DFM可以执行这些操作的位置。"内容"选项卡显示有关FlowFile内容的信息,例如其在内容存储库中的位置及其大小。此外,用户可以在此处单击Download按钮以下载流程中此时存在的FlowFile内容的副本。用户还可以单击该Submit按钮以在流程中的此时重放FlowFile。点击后Submit,FlowFile被发送到为生成此处理事件的组件提供的连接。
查看FlowFile Lineage
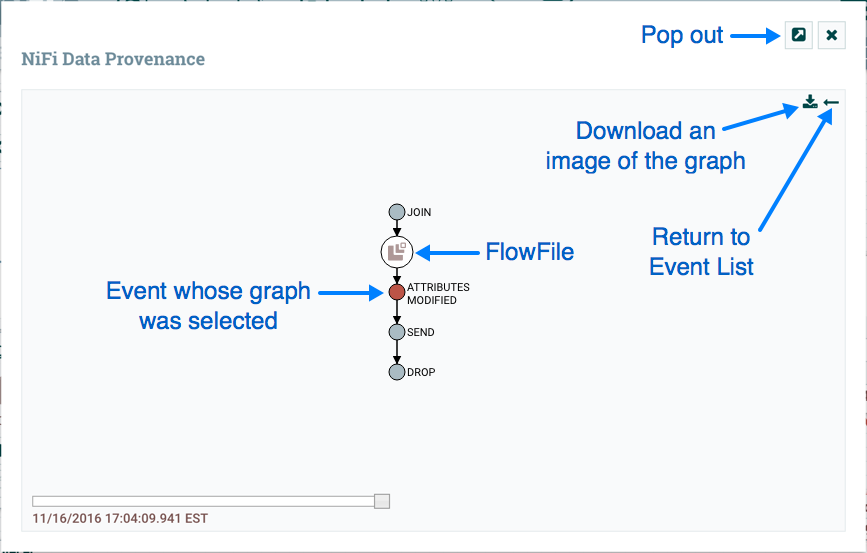
查看FlowFile在数据流中采用的谱系或路径的图形表示通常很有用。要查看FlowFile的谱系,请单击 Data Provenance表的最右侧列中的"Show Lineage"图标。这将打开一个图形,显示FlowFile(
Data Provenance表的最右侧列中的"Show Lineage"图标。这将打开一个图形,显示FlowFile( )和已发生的各种处理事件。所选事件将以红色突出显示。它可以右键单击或任何事件双击看到事件的详细信息(参见事件的详细信息)。要查看谱系如何随时间演变,请单击窗口左下角的滑块并将其向左移动以查看数据流中较早阶段的谱系状态。
)和已发生的各种处理事件。所选事件将以红色突出显示。它可以右键单击或任何事件双击看到事件的详细信息(参见事件的详细信息)。要查看谱系如何随时间演变,请单击窗口左下角的滑块并将其向左移动以查看数据流中较早阶段的谱系状态。
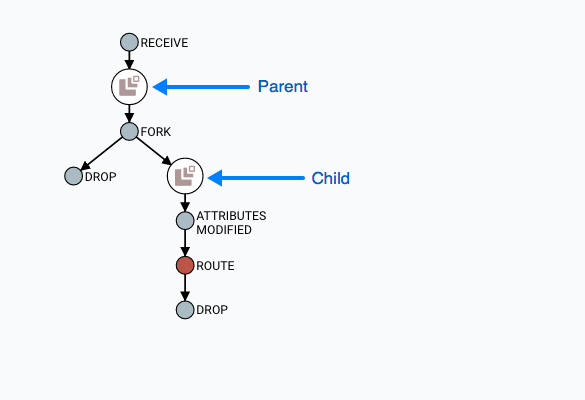
找到Parents
有时,用户可能需要跟踪从中生成另一个FlowFile的原始FlowFile。例如,当发生FORK或CLONE事件时,NiFi会跟踪生成其他FlowFiles的父FlowFile,并且可以在Lineage中找到父FlowFile。右键单击沿袭图中的事件,然后从上下文菜单中选择"查找父项"。
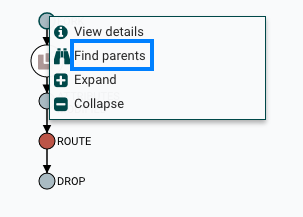
选择"Find parents"后,将重新绘制图形以显示父FlowFile及其谱系以及子项及其谱系。
扩展活动
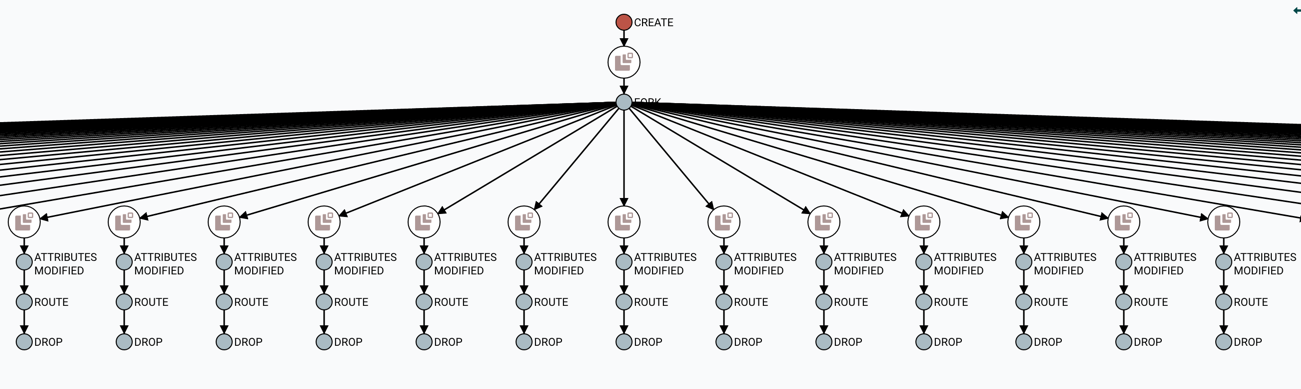
与查找父FlowFile有用的方式相同,用户可能还想确定从给定FlowFile生成的子项。要执行此操作,请右键单击沿袭图中的事件,然后从上下文菜单中选择"展开"。
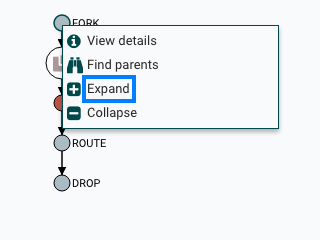
选择"Expand"后,将重新绘制图形以显示子项及其谱系。
提前编写源代码存储库
默认情况下,Provenance Repository以Persistent Provenance配置实现。在Apache NiFi 1.2.0中,引入了Write Ahead配置以提供与Persistent Provenance相同的功能,但性能要好得多。迁移到Write Ahead配置很容易实现。只需nifi.provenance.repository.implementation将nifi.properties文件中系统属性的设置更改为默认值org.apache.nifi.provenance.PersistentProvenanceRepositoryto,org.apache.nifi.provenance.WriteAheadProvenanceRepository然后重新启动NiFi。
但是,为了增加迁移成功的可能性,请考虑以下因素和建议的操作。
向后兼容性
在WriteAheadProvenanceRepository可以使用的存储出处的数据PersistentProvenanceRepository。但是,PersistentProvenanceRepository可能无法读取所写的数据WriteAheadProvenanceRepository。因此,一旦将Provenance Repository更改为使用WriteAheadProvenanceRepository,它就不能在PersistentProvenanceRepository没有先删除Provenance Repository中的数据的情况下更改回。因此,建议在将实施更改为Write Ahead之前,确保您的NiFi版本稳定,以防出现需要回滚到不支持的NiFi的先前版本的问题WriteAheadProvenanceRepository。
较旧的现有NiFi版本
如果要从较旧版本的NiFi升级到1.2.0或更高版本,建议您在1.2.0之前确认流量和环境稳定之前,不要将起源配置更改为Write Ahead。这样可以减少升级中的变量数量,并在出现任何问题时简化调试过程。
Bootstrap.conf
虽然使用G1垃圾收集器可以获得更好的性能,但Java 8错误可能会在Write Ahead配置中更频繁地出现。建议在目录中的bootstrap.conf文件中注释掉以下行conf:
java.arg.13 = -XX:+ UseG1GC
系统属性
Persistent和Write Ahead配置都支持许多相同的系统属性,但是为Persistent Provenance配置选择了默认值。更改为Write Ahead配置时,应注意以下例外和建议:
nifi.provenance.repository.journal.count 与Write Ahead配置无关
nifi.provenance.repository.concurrent.merge.threads并且nifi.provenance.repository.warm.cache.frequency是新的属性。2对于大多数安装,线程的默认值和频率的空白(即禁用)应保留。
将nifi.provenance.repository.max.storage.time(默认值24 hours)和nifi.provenance.repository.max.storage.size(默认值1 GB)的设置更改为更适合您的生产环境的值
nifi.provenance.repository.index.shard.size从默认值更改500 MB为4 GB
nifi.provenance.repository.index.threads从默认值更改2为任一4或8作为Write Ahead存储库使其能够更好地扩展
如果处理事件的高容量,改变nifi.provenance.repository.rollover.time从默认的30 secs对1 min与nifi.provenance.repository.rollover.size从默认100 MB到1 GB
完成这些属性更改后,重新启动NiFi。
注意:可以在系统属性中找到每个属性的详细说明 。
加密的源代码注意事项
上述迁移建议WriteAheadProvenanceRepository也适用于配置的加密版本EncryptedWriteAheadProvenanceRepository。
下一节提供了有关实现Encrypted Provenance Repository的更多信息。
加密的Provenance存储库
虽然操作系统级访问控制可以提供对存储库中写入磁盘的起源数据的一些安全性,但有些情况下数据可能是敏感的,合规性和法规要求存在,或者NiFi在不受直接控制的硬件上运行。组织(云等)。在这种情况下,originance存储库允许在将所有数据持久保存到磁盘之前对其进行加密。
性能 加密源文件库的当前实现拦截了记录编写者和读者WriteAheadProvenanceRepository,它提供了对遗留的显着性能改进PersistentProvenanceRepository并使用该AES/GCM算法,该算法在商品硬件上相当高效。在大多数情况下,增加的成本并不显着(在每秒数百个来源事件的流量上不明显,在每秒数千个 - 数万个事件的流量上适度显着)。但是,管理员应该执行自己的风险评估和性能分析,并决定如何继续前进。目前不建议在加密/未加密的实现之间来回切换。
它是什么?
这EncryptedWriteAheadProvenanceRepository是originance资源库的一个新实现,它在将所有事件记录信息写入存储库之前对其进行加密。这允许在OS级访问控制不足以保护数据的系统上进行存储,同时仍允许通过NiFi UI / API查询和访问数据。
它是如何工作的?
它WriteAheadProvenanceRepository是在NiFi 1.2.0中引入的,并提供了比以前更好的重构和更快的出处库实现PersistentProvenanceRepository。加密版本使用记录编写器和读取器包装该实现,该记录编写器和读取器分别加密和解密序列化字节。
完全限定类org.apache.nifi.provenance.EncryptedWriteAheadProvenanceRepository在nifi.properties中指定为originance存储库实现,作为值nifi.provenance.repository.implementation。此外,必须填充新属性以允许成功初始化。
StaticKeyProvider
该StaticKeyProvider实现直接在nifi.properties中定义键。各个键以十六进制编码提供。使用NiFi Toolkit中的工具,密钥也可以像nifi.properties中的任何其他敏感属性一样进行加密./encrypt-config.sh。
以下配置部分将导致密钥提供程序具有两个可用密钥,"Key1"(活动)和"AnotherKey"。
nifi.provenance.repository.encryption.key.provider.implementation = org.apache.nifi.security.kms.StaticKeyProvider nifi.provenance.repository.encryption.key.id =key1 nifi.provenance.repository.encryption.key = 0123456789ABCDEFFEDCBA98765432100123456789ABCDEFFEDCBA9876543210 nifi.provenance.repository.encryption.key.id.AnotherKey = 0101010101010101010101010101010101010101010101010101010101010101
FileBasedKeyProvider
在FileBasedKeyProvider执行从格式的加密定义文件上写着:
key1 = NGCpDpxBZNN0DBodz0p1SDbTjC2FG5kp1pCmdUKJlxxtcMSo6GC4fMlTyy1mPeKOxzLut3DRX + 51j6PCO5SznA == key2 = GYxPbMMDbnraXs09eGJudAM5jTvVYp05XtImkAg4JY4rIbmHOiVUUI6OeOf7ZW + hH42jtPgNW9pSkkQ9HWY / VQ == KEY3 = SFe11xuz7J89Y / IQ7YbJPOL0 / YKZRFL / VUxJgEHxxlXpd / 8ELA7wwN59K1KTr3BURCcFP5YGmwrSKfr4OE4Vlg == KEY4 = kZprfcTSTH69UuOU3jMkZfrtiVR / eqWmmbdku3bQcUJ / + UToecNB5lzOVEMBChyEXppyXXC35Wa6GEXFK6PMKw == KEY5 = c6FzfnKm7UR7xqI2NFpZ + fEKBfSU7 + 1NvRw + XWQ9U39MONWqk5gvoyOCdFR1kUgeg46jrN5dGXk13sRqE0GETQ ==
每行定义一个密钥ID,然后定义16字节IV和包装的AES-128,AES-192或AES-256密钥的Base64编码密文,具体取决于可用的JCE策略。各个密钥由使用AES/GCM加密包裹主密钥通过限定nifi.bootstrap.sensitive.key在conf/bootstrap.conf。
Key Rotation
只需更新nifi.properties即可引用新的密钥ID nifi.provenance.repository.encryption.key.id。只要该密钥在密钥定义文件中仍然可用,或者nifi.provenance.repository.encryption.key.id.OldKeyID密钥ID与加密记录一起序列化,以前加密的事件仍然可以被解密。
写作和阅读事件记录
初始化存储库后,所有源项事件记录写入操作将根据配置的模式编写器(EventIdFirstSchemaRecordWriter默认情况下WriteAheadProvenanceRepository)序列化为a byte[] 然后,这些字节被使用的一个实现加密ProvenanceEventEncryptor(唯一的当前的实现是AES/GCM/NoPadding)和加密的元数据(keyId,algorithm,version,IV)被串行化和前缀。byte[]然后将complete完成写入磁盘上的存储库。
在记录读取时,该过程是相反的。解密加密元数据并用于解密序列化字节,然后将其反序列化为ProvenanceEventRecord对象。对正常模式记录写入器/读取器的委托允许"随机访问"(即,立即搜索而不解密不必要的记录)。
在NiFi UI / API中,加密和未加密的起源存储库之间没有可检测到的差异。Provenance Query操作按预期工作,不会对过程进行任何更改。
潜在问题
切换实现 当执行"家族"之间(即切换VolatileProvenanceRepository或PersistentProvenanceRepository到EncryptedWriteAheadProvenanceRepository),现有的存储库,必须从文件系统启动之前NiFi清除。终端命令localhost:$NIFI_HOME $ rm -rf provenance_repository/就足够了。
在未加密和加密的存储库之间切换
如果用户具有未加密的现有存储库(WriteAheadProvenanceRepository仅 - 非 PersistentProvenanceRepository)并将其配置切换为使用加密存储库,则应用程序会将错误写入日志但会启动。但是,以前的事件无法通过起源查询界面访问,新事件将覆盖现有事件。如果用户从加密存储库切换到未加密的存储库,则会发生相同的行为。自动翻转是未来的努力(NIFI-3722),但NiFi不适用于物源事件的长期存储,因此影响应该是最小的。翻转有两种情况:
加密→未加密 - 如果以前的存储库实现已加密,只要可用的密钥提供程序仍具有用于加密事件的密钥,就应无缝处理这些事件(请参阅密钥轮换)
未加密→加密 - 如果以前的存储库实现未加密,则应无缝处理这些事件,因为先前记录的事件只需要使用明文架构记录读取器读取,然后使用加密记录写入器写回
今后还有一项工作是在NiFi Toolkit中提供一个独立的工具来加密/解密现有的出处存储库,以便更容易地进行过渡。转换过程可能需要很长时间,具体取决于现有存储库的大小,并且能够在应用程序启动之外执行此任务将是有价值的(NIFI-3723)。
多个存储库 - 此时不再对多个存储库应用额外的工作或测试。可能/可能在不同物理设备上的存储库中会出现问题。没有选择提供异构环境(即一个加密的,一个明文存储库)。
损坏 - 当磁盘被填满或损坏时,已报告存储库损坏并且需要恢复步骤的问题。这可能会继续成为加密存储库的问题,但仍然限制在单个记录的范围内(即整个存储库文件由于加密而不会无法恢复)。
其他管理功能
除摘要页面,数据源页面,模板管理页面和公告板页面外,全局菜单中还有其他工具(请参阅NiFi用户界面),这些工具对DFM很有用。选择"流配置历史记录"以查看对数据流所做的所有更改。历史记录可以帮助进行故障排除,例如,如果最近对数据流的更改导致了问题并且需要修复。DFM可以查看已进行的更改并根据需要调整流量以解决问题。虽然NiFi没有"撤消"功能,但DFM可以对数据流进行新的更改以解决问题。
全局菜单中的另外两个工具是控制器设置和用户。控制器设置页面提供了更改NiFi实例名称,添加描述NiFi实例的注释以及设置应用程序可用的最大线程数的功能。它还提供了DFM可以添加和配置Controller Services和Reporting Tasks的选项卡。用户页面用于管理用户访问,系统管理员指南中对此进行了描述。